
基于多层感知器的双向长时间存储网络( BiLSTM )
本文的网络体系结构是由尹瑞青、赫夫·布林、克劳德·巴拉斯·巴拉斯( Claude Barras,as,在这里输入图像描述 )提出的一种基于双向长时间存储网络的广播电视说话人变化检测系统。
{kind=link}
该模型由两个Bi(Bi 1和2)和一个多层感知器(MLP)组成,其权重跨序列共享。Bi 1有64个输出(向前32个,向后32个)。双LSTM2 2有40只(每只20只)。全连通层分别为40维、10维和1维.前向和后向LSTM的输出被连接起来,并前馈到下一层。共享MLP由三个完全连接的前馈层组成,前两层使用tanh激活函数,最后一层采用sigmoid激活函数,以便输出0到1之间的分数。我参考了各种来源并编写了以下代码,
model = Sequential()
model.add(Bidirectional(LSTM(64, return_sequences=True)))
model.add(Bidirectional(LSTM(40, return_sequences=True)))
model.add(TimeDistributed(Dense(40,activation='tanh')))
model.add(TimeDistributed(Dense(10,activation='tanh')))
model.add(TimeDistributed(Dense(1, activation='sigmoid')))
model.build(input_shape=(None, 200, 35))
model.summary()我对TimeDistributed层感到困惑,它如何模拟MLP,以及权重是如何被共享的,你至少能指出我做得对不对。
回答 1
Stack Overflow用户
发布于 2020-11-21 23:05:53
正如本文中的体系结构所建议的那样,您基本上希望将每个隐藏状态(它们本身是时间分布的)推入到单独的密集层中(从而在每个时间状态下形成一个MLP )。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
bidirectional (Bidirectional (None, 200, 128) 51200
_________________________________________________________________
bidirectional_1 (Bidirection (None, 200, 80) 54080
_________________________________________________________________
time_distributed (TimeDistri (None, 200, 40) 3240
_________________________________________________________________
time_distributed_1 (TimeDist (None, 200, 10) 410
_________________________________________________________________
time_distributed_2 (TimeDist (None, 200, 1) 11
=================================================================
Total params: 108,941
Trainable params: 108,941
Non-trainable params: 0这里的Bi设置为return_sequence = True.因此,它将隐藏的状态序列返回到后续层。如果你把这个序列推到一个致密的层里,那就没有意义了,因为你要返回一个三维张量(batch, time, feature)。现在,如果您想在每次都形成一个密集的网络,您将需要它的时间分布。
如输出形状所示,该层在前200步时间步骤中创建一个40节点层,这是Bi之前的输出(隐藏状态)。然后将每一个节点层与10个节点层以及(None, 200, 10)叠加。同样,下面的逻辑也是这样。
如果您怀疑TimeDistributed层是什么-按照正式文件。
此包装器允许将一个层应用于输入的每个时态切片。
最后的目标是speaker change detection。这意味着你想在200个时间步骤中的每一个步骤中预测说话人或说话人的概率。因此,输出层返回200个logits (None, 200, 1)。
希望这能解决你的困惑。
是另一种直观的看待它的方法-
您的Bi设置为返回序列,而不仅仅是特性。返回的每个时间步骤都需要有自己的密集网络。TimeDistributed稠密基本上是一个层,它接收一个输入序列,并在每个时间步骤中将它输入到分离密集节点。因此,它没有像标准的稠密层那样有40个节点,而是有200×40节点,其中输入,即第3 40个节点,是从Bi的第三个时间步骤。这模拟了Bi序列上的时间分布MLP .
一个很好的视觉直觉,当我使用LSTM的时候-
- 如果不返回序列,则LSTM的输出仅为
ht(以下图像的LHS)的单个值。 - 如果返回序列,则输出为序列(
h0到ht) (以下图像的RHS)。
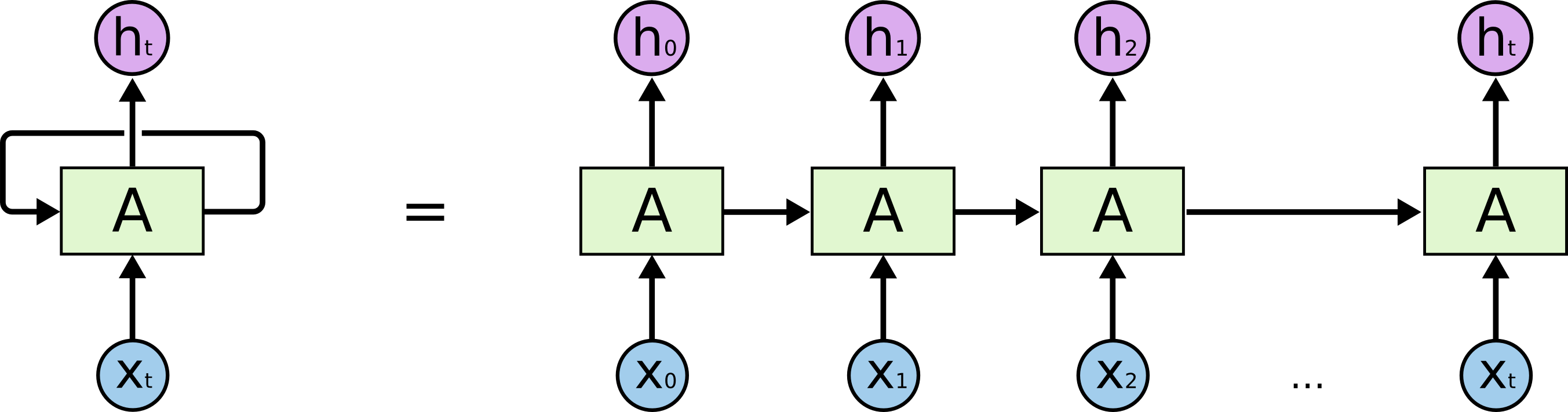
在第一种情况下,添加一个密集层只会以ht作为输入。在第二种情况下,您将需要一个TimeDistributed密度,它将在每个h0到ht之上“堆栈”。
https://stackoverflow.com/questions/61005111
复制相似问题
腾讯云开发者
