
如何从单词(.docx)复制段落(带有数字格式)和图像,并使用Python粘贴到Excel (.xlsx)
如何从单词(.docx)复制段落(带有数字格式)和图像,并使用Python粘贴到Excel (.xlsx)
提问于 2020-03-22 14:24:18
我有文字(.docx)格式的合同条款,需要经常复制并粘贴到Excel (.xlsx)中,然后发送给第三方。这些子句经常被更新,因此总是需要复制和粘贴这些子句。我只需要复制和粘贴所有的段落和图片后,的内容页。下面是条款文件的一个示例。
为了达到这个目的,我尝试使用Python编写代码。下面是我到目前为止所做的代码:
!pip install python-docx
import docx
import xlsxwriter
document = docx.Document("Clauses Sample.docx")
wb = xlsxwriter.Workbook('C:/xxxx/xxxxxx/xxxx/clauses sample.xlsx')
docText = []
index_row = 0
Sheet1 = wb.add_worksheet("Sheetttt")
for paragraph in document.paragraphs:
if paragraph.text:
docText.append(paragraph.text)
xx = '\n'.join(docText)
Sheet1.write(index_row,0, xx)
index_row = index_row+1
wb.close()
#print(xx) 但是,我的Excel文件输出如下:
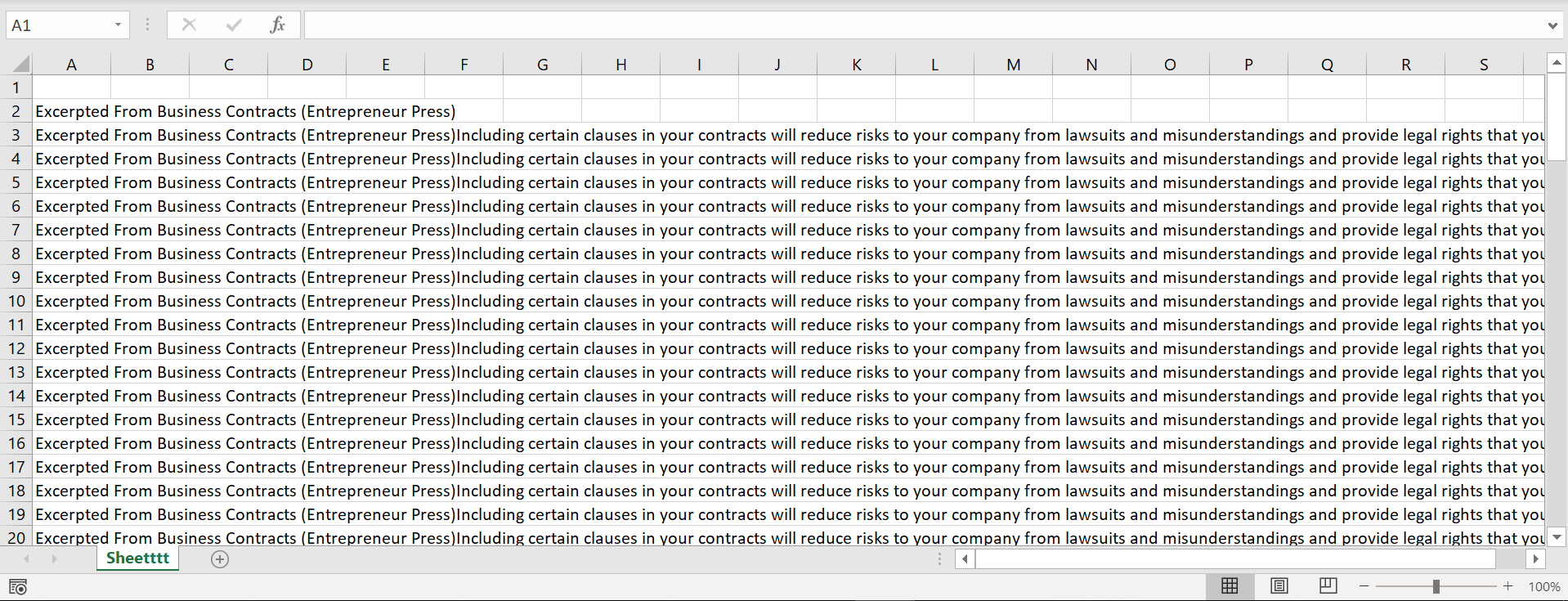
但是,我希望我的Excel输出看起来像这样,例如:
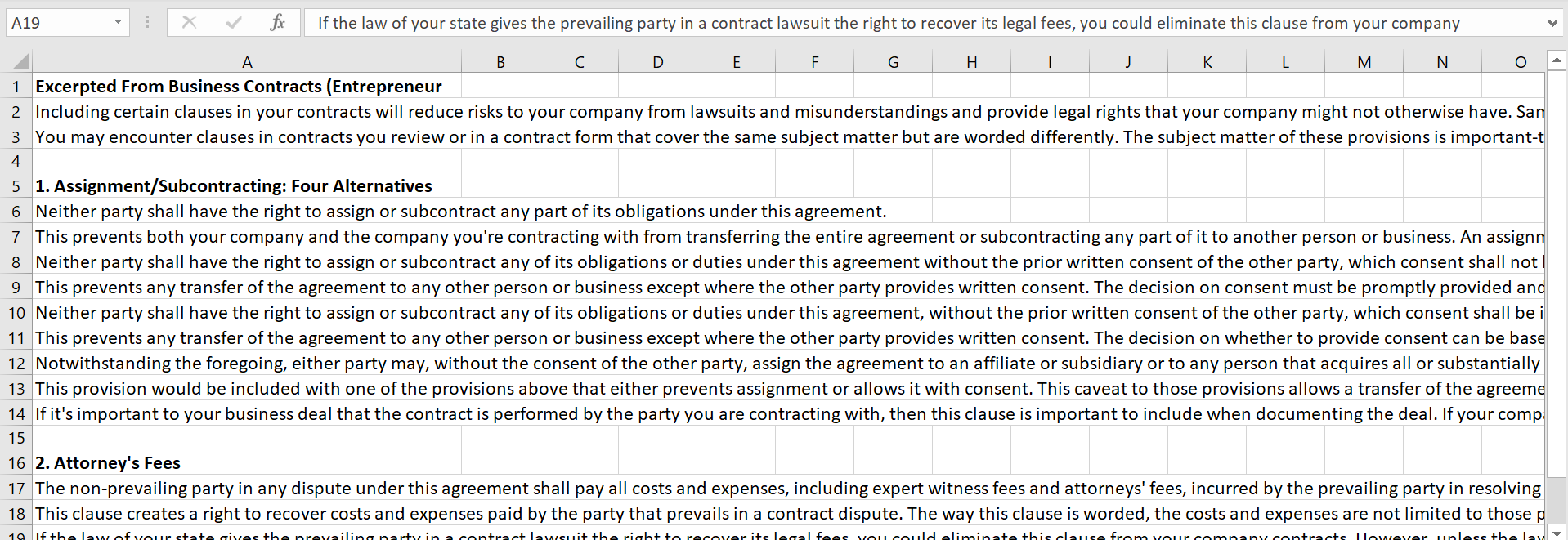

有什么方法可以得到我想要的输出吗?
回答 1
Stack Overflow用户
发布于 2020-03-22 15:57:23
这里有两个问题(和解决方案),我认为这将有助于你接近。
- 您的
docText变量正在累积all文档中的文本。我认为您的意思是在电子表格的每一行中写出一段。我会将for循环改为如下所示:
for paragraph in document.paragraphs:
if paragraph.text:
# Put paragraph.text into the row, NOT docText.
# Do you really need the join()? I don't think so.
Sheet1.write(index_row,0, paragraph.text)
index_row = index_row+1- 您正在使用
if paragraph.text:测试删除空白段落。如果您想要空行(在电子表格示例中显示为第4行和第15行),请取出if测试。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60800494
复制相关文章
相似问题
腾讯云开发者
