
根据特定列中的值对dataframe行排序
根据特定列中的值对dataframe行排序
提问于 2020-03-14 16:44:18
我有这个数据:
d = {'important1': [1.1, 2.2], 'notimportant1': [1.4, 2.5], 'important2': [3.5, 4.2], 'notimportant2': [1.3,2.0]}
important_lst = ['important1', 'important2']
df = pd.DataFrame(data=d)
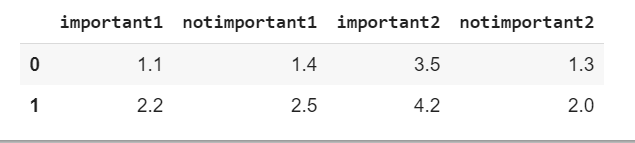
我想添加另一列,即important_lst中所有列的级别之和。
例如,在当前数据帧中,
- 第一行的等级: 1,3,4,2所以等级之和是5 (1 +4)
- 第二排的等级: 2,3,4,1,所以等级之和是6 (2 + 4)
。
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-03-14 16:48:11
将DataFrame.rank与按列表、和最后一次转换为整数的列一起使用:
df['new_col'] = df.rank(axis=1)[important_lst].sum(axis=1).astype(int)
print (df)
important1 notimportant1 important2 notimportant2 new_col
0 1.1 1.4 3.5 1.3 5
1 2.2 2.5 4.2 2.0 6Stack Overflow用户
发布于 2020-03-14 16:47:19
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60685041
复制相关文章
相似问题
腾讯云开发者
