
大查询数据终止
大查询数据终止
提问于 2020-02-15 06:58:09
为了分析目的,我一直在BigQuery中收集数据。然而,数据的规模正在增长,我只需要2周的近期数据。我想删除未使用的数据。我做了一些研究,发现分区数据有一个过期选项。
电流设置:
我的表是一个分区表,我使用类似于此代码的Lambda函数将数据放入表中(我尝试了添加timePartitioning选项,但它没有工作,这就是为什么我询问堆栈溢出是否有人知道)
wait bq
.dataset("dataset name")
.table('tablename' + '$' + partitionTime)
.load( filename, {
sourceFormat: 'CSV',
schema,
skipLeadingRows: 1,
timePartitioning: {
expirationMs: "300000"
}
});其中partitionTime格式为YYYYMMDD (将数据插入到该分区中)
谢谢你的评论和花时间阅读我的麻烦:)祝你今天愉快。
回答 1
Stack Overflow用户
发布于 2020-02-17 10:46:49
正如您可以看到的,这里函数load接受三个参数:
- 来源(需要)
- 元数据(可选)
- 回调(可选)
您需要的选项可以在metadata参数中设置。在上面提供的链接中,您还可以注意到BigQuery SDK使用API调用来执行给定的操作。在这个链接和printscreen下面,您可以看到如何为BigQuery构建一个正确的API调用。
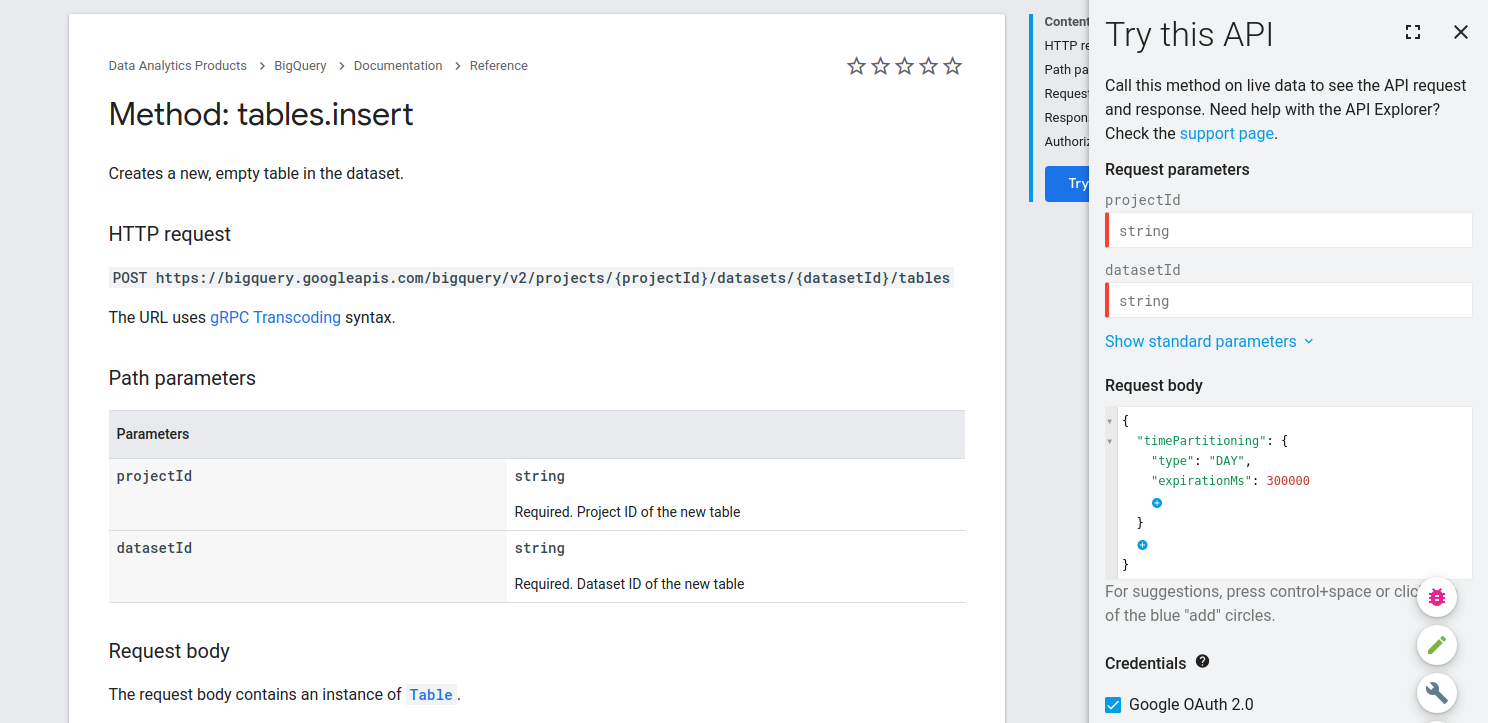
在字段timePartitioning中,您可以添加天作为分区的提示,以及以毫秒为单位的过期时间。
最后,您的代码将有一个小的变化:
wait bq
.dataset("dataset name")
.table('tablename')
.load( filename, {
sourceFormat: 'CSV',
schema,
skipLeadingRows: 1,
timePartitioning: {
type: "DAY",
expirationMs: "300000"
}
});我希望它能帮上忙
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60236589
复制相关文章
相似问题
腾讯云开发者
