
如何根据两列中的两个变量删除数据帧中的行
如何根据两列中的两个变量删除数据帧中的行
提问于 2020-01-31 21:39:40
我有一个由3列组成的数据集(邮政编码、Borough和Neighbourhood),设置如下:
df = pd.DataFrame({'Postcode' : ['M1', 'M2', 'M3', 'M4', 'M5'],
'Borough' : ['Ottawa', 'Not assigned', 'Montreal', 'Toronto', 'Kent'],
'Neighbourhood' : ['Ottawa', 'Toronto', 'Montreal', 'Barrhaven', 'Not assigned']})看起来是这样的:
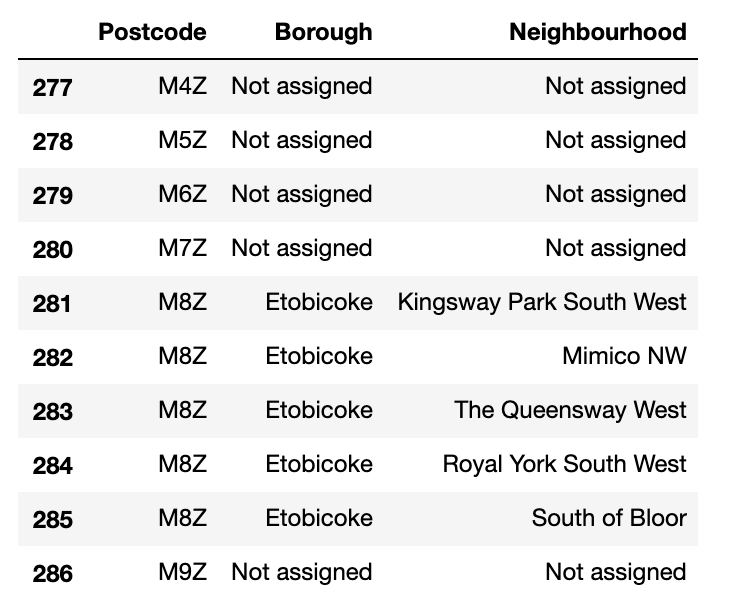
列Borough和Neighbur竟中的值既可以是“未分配的”,也可以是有效的文本--“未分配”的值可以在两个单元格中,也可以在一个或另一个单元格中。
我想要做的是删除整个数据集中的行,在这两个列中都有“未分配的”行。
我对Python很陌生..。我想我应该尝试根据其中一个单元格的值创建一个额外的列,给出真或假,所以我尝试了.
df['Outcome'] = ["True" if x =='Not assigned' else "False" for x in df['Borough']] ..。,成功地添加了一个额外的列。
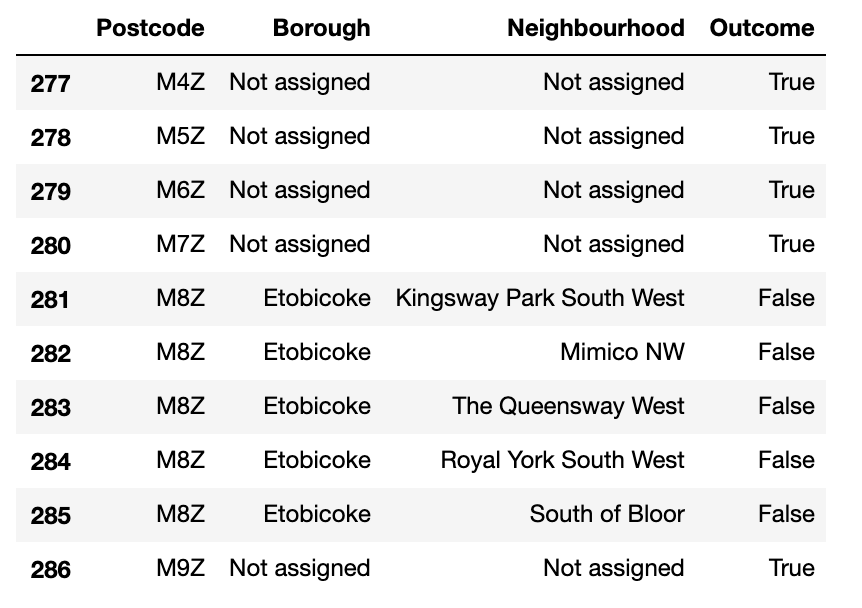
然后,我想我会尝试用drop()函数删除那些真正的行,并在Neighbur竟列上重复这个过程。但这似乎是一种杂乱无章的方法,最后我将得到20行代码,我确信这样做的效率要高得多。
有人能给我建议一下最简单的方法吗?
回答 3
Stack Overflow用户
回答已采纳
发布于 2020-01-31 21:47:52
您可以使用按位“或”|“来完成该操作。
df_filtered = df[~((df['Borough'] == 'Not assigned') |
(df['Neighbourhood'] == 'Not assigned'))]然后,对样本数据集的结果是:
Postcode Borough Neighbourhood
0 M1 Ottawa Ottawa
2 M3 Montreal Montreal
3 M4 Toronto BarrhavenStack Overflow用户
发布于 2020-01-31 21:52:19
我们可以在axis = 1中使用DataFrame.ne + 来执行boolean indexing
df_filtered = df[df[['Borough','Neighbourhood']].ne('Not assigned').all(axis=1)]
print(df_filtered)输出
Postcode Borough Neighbourhood
0 M1 Ottawa Ottawa
2 M3 Montreal Montreal
3 M4 Toronto BarrhavenStack Overflow用户
发布于 2020-01-31 21:51:44
尝试:
df = df[~(df['Borough'].eq('Not assigned') | df['Borough'].eq('Not assigned'))] Postcode Borough Neighbourhood
0 M1 Ottawa Ottawa
2 M3 Montreal Montreal
3 M4 Toronto Barrhaven页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60011588
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号