
使用regex python的模式匹配
使用regex python的模式匹配
提问于 2020-01-28 08:56:07
以下是文本示例:
- 美国心理协会。(2016)。流行病学研究中心抑郁症()。检索2016年12月7日,来自美国心理协会,http://www.apa.org/pi/ http://www.apa.org/pi/评估/工具/抑郁量表。
- Beattie,G.S. (2005年,11月)。抑郁的社会原因。2017年5月31日,从http:// www.personalityresearch.org/papers/beattie.html检索
我想要我尝试过的文本中的粗俗部分:
/\)\.|\s[a-zA-Z]+\./我在这里找')‘那么’‘。然后是‘空格’,然后再发短信直到‘’。
基本上,我想要两个点之间的文本,,因为这是论文的标题,在作者或出版物之后开始,如示例中提到的那样,年份放在括号中。但是在上面pattern并没有给出我想要的。
有人能帮我解释一下为什么它不起作用吗?在我的dataframe列中找到这样的文本的另一种方法是什么?
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-01-28 09:08:28
您可以在Series.str.extract中使用以下正则表达式
\)\.\s+([^.]+)见regex演示。
详细信息
\)\.-).子字符串\s+- 1+白空间([^.]+)-第1组:除点以外的一个或多个字符
在潘达斯,你可以像
df['res_col'] = df['orig_col'].str.extract(r'\)\.\s+([^.]+)', expand=False)按注释更新
允许使用任何已知缩写的更具体的正则表达式是
[\d)]\.\s*((?:\ba\.k\.a\.|[^.])+)见另一个regex演示。详细信息:
[\d)]-一个数字或)\.-a点\s*-0或更多的空白空间((?:\ba\.k\.a\.|[^.])+)-第1组:一个或多个a.k.a.子字符串作为一个整体字或除一个点以外的任何字符。
Stack Overflow用户
发布于 2020-01-28 09:14:12
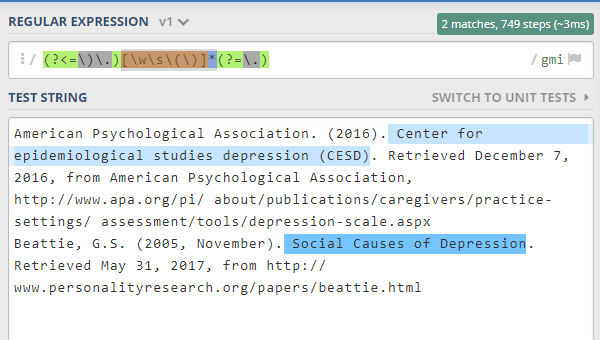
尝尝这个
(?<=\)\.)[\w\s\(\)]*(?=\.)(?<=\)\.)是在搜索后查看是否“)”。在此之前)。[\w\s\(\)]*允许所有单词和空白字符以及(和)切拍。(?=\.)是一个前瞻性的搜索,以检查chracter。
你可以测试它这里
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59945094
复制相关文章
相似问题
腾讯云开发者
