
收敛失败:不收敛的迭代极限(10)
我很难得到一条特殊的曲线来拟合nls模型的数据。
这是数据的公式:
((b1 * ((b2 * x)^b4)) / (1 + ((b2 * x)^b4)))^(b3 / b4)我使用带有随机算法的nls2包来查找输入值。
library(nls2)
#FORMULA
eq <- y ~ (b1 * ((b2 * x)^b4)) / (1 + ((b2 * x)^b4))^(b3 / b4)
#LIMITS
values <- data.frame(
b1 = c(60, 63)
b2 = c(0, 0.05)
b3 = c(0, 1)
b4 = c(0, 0.9)
fit <- nls2(eq,
data = .data,
start = values,
algorithm = "random",
control = mls.control(maxiter = 1000))
nls(eq, .data, start = coef(fit), alg = "port", lower = 0)
plot(.data)这些价值应该是:
b1 = 62.2060
b2 = 0.0438
b3 = 0.9692
b4 = 0.8693然而,当我试图运行代码时,我总是以一条错误消息结束:Convergence Failure: Iteration limit reached without convergence (10)
如何避免收敛失败的错误?任何帮助都是非常感谢的。谢谢。
回答 1
Stack Overflow用户
发布于 2020-01-01 09:22:33
0。TLDR
您没有在lower和upper中设置nls绑定,因此没有得到收敛的结果。如果你设置它们,你就会在边界附近得到一个结果。查看我在最后一段中编写的代码.
实际上,即使设置了边界,由于数据质量不好的(样本大小很小,不符合公式),很难在真正的b1、'b2‘、'b3’和b4附近拟合一个最优值。参见非技术原因。
1.收敛失败的非技术性原因
我认为您的代码是正确的,这种收敛失败是由于您的数据质量或您对公式的错误说明。
一般来说,你很难用6点来估计4个参数。如果你有很好的数据符合你的模型,nlm将收敛。在您的情况下,要么您的数据是错误的,要么您的公式规格偏差是巨大的。
我画了一个图谋给你看:
码
# generate a line using true parameters:b1,b2,b3,b4
b1 = 62.2060
b2 = 0.0438
b3 = 0.9692
b4 = 0.8693
x_points = seq(50,420,length.out = 200)
y_points = (b1 * ((b2 * x_points)^b4)) / (1 + ((b2 * x_points)^b4))^(b3 / b4)
# plot the function
plot(x = x_points ,y = y_points, type ='l',col ='black',lwd = 5,
xlim = c(min(yourdata$x)-5,max(yourdata$x)+5),
ylim = c(min(yourdata$y)-5,max(yourdata$y)+5))
# plot the data your got
points(yourdata$x,yourdata$y,cex = 2)输出:
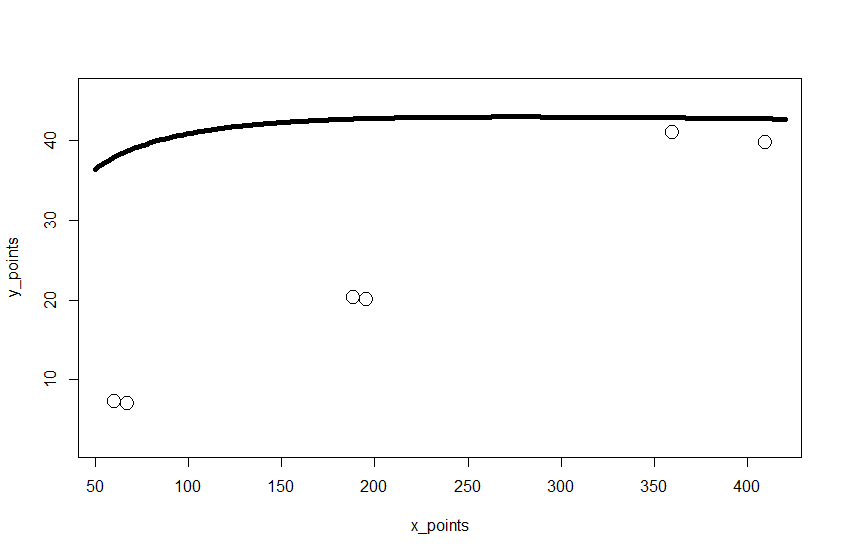
如果我们从您的公式中生成数据,我们可以很容易地对它们进行拟合,如下所示:
## generate data
b1 = 62.2060
b2 = 0.0438
b3 = 0.9692
b4 = 0.8693
x <- runif(6,60,450)
y <- (b1 * ((b2 * x)^b4)) / (1 + ((b2 * x)^b4))^(b3 / b4)
data <- data.frame(x,y)
yourdata <- data.frame(x = c(409.56, 195.25, 60.53, 359.56, 188.79, 67.12),
y = c(39.76100, 20.11875, 7.23675, 41.01100, 20.28035, 7.07200))
#FORMULA
eq <- y ~ (b1 * ((b2 * x)^b4)) / (1 + ((b2 * x)^b4))^(b3 / b4)
#LIMITS
values <- data.frame(
b1 = c(60, 63),
b2 = c(0, 0.05),
b3 = c(0, 1),
b4 = c(0, 0.9))
fit <- nls2(eq,
data = data,
start = values,
algorithm = "random",
control = nls.control(maxiter = 1000))
nls(eq, data, start = coef(fit), alg = "port",
control = nls.control(maxiter = 1000,tol = 1e-05),
low = c(60,0,0,0),upper =c(63,0.05,1,0.9) ,trace = TRUE)
plot(x,y)输出:
非线性回归模型:y~ (b1 * ((b2 *x)^ b4 )/(1+ ((b2 * x)^b4))^( b3 /b4)数据: data b1 b2 b3 b4 62.2060 0.0438 0.9692 0.8693残差和平方: 3.616e-24算法“端口”,收敛消息:绝对函数收敛(6)
Alse注意,在上面,我生成only6数来拟合模型。如果您生成更多的数据,例如60,您将有一个更好的收敛性!
2.技术原因
在阅读了端口文档之后,我认为这个错误可能意味着
计算incorrectly
- stopping公差的
- 梯度,tight
- gradient在某些迭代
附近不连续
所有这些都可能与您的数据和培训任务(您的边界和公式)有关系。
尝试下面的代码,您将得到一个更好的结果:
代码:
yourdata <- data.frame(x = c(409.56, 195.25, 60.53, 359.56, 188.79, 67.12),
y = c(39.76100, 20.11875, 7.23675, 41.01100, 20.28035, 7.07200))
#FORMULA
eq <- y ~ (b1 * ((b2 * x)^b4)) / (1 + ((b2 * x)^b4))^(b3 / b4)
#LIMITS
values <- data.frame(
b1 = c(60, 63),
b2 = c(0, 0.05),
b3 = c(0, 1),
b4 = c(0, 0.9))
fit <- nls2(eq,
data = yourdata,
start = values,
algorithm = "random",
control = nls.control(maxiter = 1000))
nls(eq, yourdata, start = coef(fit), alg = "port",
control = nls.control(maxiter = 1000,tol = 1e-05),
low = c(60,0,0,0),upper =c(63,0.05,1,0.9) ,trace = TRUE)
plot(x,y)输出:
非线性回归模型:y~ (b1 * ((b2 *x)^ b4 )/(1+ ((b2 * x)^b4))^( b3 /b4)数据: yourdata b1 b2 b3 b4 63.00000 0.00155 0.00000 0.90000残差和平方: 22.28算法“端口”,收敛消息:X-收敛和相对收敛(5)
正如我们所看到的,它收敛到边界,这意味着您的数据与设置(公式或边界)不一致。
https://stackoverflow.com/questions/59550999
复制相似问题
腾讯云开发者
