
如何使用python列表重新命名dataframe索引?
如何使用python列表重新命名dataframe索引?
提问于 2019-12-18 06:49:04
我有一只熊猫数据和一份如下所示的有序列表
df = pd.DataFrame([[1, 2, 3], [4, 5 ,6]], columns=list('ABC'))
df = df.rename(index={0:'x1'})
df = df.rename(index={1:'x2'})

请注意,我已经参考了post
该列表如下所示
ordered_list = ['Name_1','Name_2']这是我尝试过的,但它没有效率,不能用于有更多记录的数据格式。
df = df.rename(index={'x1':'Name_1'})
df = df.rename(index={'x2':'Name_2'})您可以看到,我使用rename函数重命名了索引。但是,使用可用的ordered list ,是否有效率地做到这一点呢?,因为我的真实数据中有more than 60 index values。
我的意思是列表中的第一个元素对应于x1,列表中的第二个元素对应于x2等等。
我希望我的输出如下所示
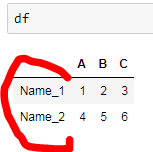
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-12-18 06:52:40
只需使用:
df.index = ordered_listStack Overflow用户
发布于 2019-12-18 07:22:15
您可以这样做,那么您将不需要一个有序的列表:
df.index = df.reset_index().index+1
df = df.T.add_prefix('Name_').T页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59386797
复制相关文章
相似问题
腾讯云开发者
