
有没有办法保存熊猫的分类数据?
有没有办法保存熊猫的分类数据?
提问于 2019-11-23 03:10:48
我有一个数据,其中一列是美国。我想要创建一个新的列,并根据区域,即南部、西南部等来存储状态。看起来pd.cut只用于连续变量,所以这样的绑定看起来不像一个选项。是否有一种很好的方法来创建一个以另一列中的分类数据为条件的列?
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-11-24 09:51:28
import pandas as pd
def label_states (row):
if row['state'] in ['Maine', 'New Hampshire', 'Vermont', 'Massachusetts', 'Rhode Island', 'Connecticut', 'New York', 'Pennsylvania', 'New Jersey']:
return 'north-east'
if row['state'] in ['Wisconsin', 'Michigan', 'Illinois', 'Indiana', 'Ohio', 'North Dakota', 'South Dakota', 'Nebraska', 'Kansas', 'Minnesota', 'Iowa', 'Missouri']:
return 'midwest'
if row['state'] in ['Delaware', 'Maryland', 'District of Columbia', 'Virginia', 'West Virginia', 'North Carolina', 'South Carolina', 'Georgia', 'Florida', 'Kentucky', 'Tennessee', 'Mississippi', 'Alabama', 'Oklahoma', 'Texas', 'Arkansas', 'Louisiana']:
return 'south'
return 'etc'
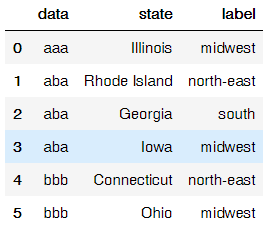
df = pd.DataFrame([{'state':"Illinois", 'data':"aaa"}, {'state':"Rhode Island",'data':"aba"}, {'state':"Georgia",'data':"aba"}, {'state':"Iowa",'data':"aba"}, {'state':"Connecticut",'data':"bbb"}, {'state':"Ohio",'data':"bbb"}])
df['label'] = df.apply(lambda row: label_states(row), axis=1)
df
Stack Overflow用户
发布于 2019-11-23 18:59:35
假设您的df包含:
- State - US state code.
- 其他列,关于测试(见下文),我只包含了州名.
当然,对于每个状态,它可以包含更多的列和多行。
若要添加区域名称(新列),请定义区域DataFrame,包含列:
- State -美国州代码.
- 区域-区域名称.
然后合并这些DataFrames并将结果保存回df下。
df = df.merge(regions, on='State')部分结果是:
State Name State Region
0 Alabama AL Southeast
1 Arizona AZ Southwest
2 Arkansas AR South
3 California CA West
4 Colorado CO Southwest
5 Connecticut CT Northeast
6 Delaware DE Northeast
7 Florida FL Southeast
8 Georgia GA Southeast
9 Idaho ID Northwest
10 Illinois IL Central
11 Indiana IN Central
12 Iowa IA East North Central
13 Kansas KS South
14 Kentucky KY Central
15 Louisiana LA South当然,对于如何将美国状态分配给区域,有许多变体,因此,如果您想使用其他变体,请根据您的分类定义区域DataFrame。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59004206
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号