
如何在标准C++中使用计算gotos将动态调度速度提高20%
在你投反对票或开始说goto是邪恶和过时之前,请阅读为什么在这种情况下它是可行的理由。在将其标记为副本之前,请阅读完整的问题。
当我偶然发现的时候,我正在阅读有关虚拟机解释器的内容。显然,它们允许显着地提高某些代码段的性能。最著名的例子是主VM解释器循环。
考虑这样一个(非常)简单的VM:
#include <iostream>
enum class Opcode
{
HALT,
INC,
DEC,
BIT_LEFT,
BIT_RIGHT,
RET
};
int main()
{
Opcode program[] = { // an example program that returns 10
Opcode::INC,
Opcode::BIT_LEFT,
Opcode::BIT_LEFT,
Opcode::BIT_LEFT,
Opcode::INC,
Opcode::INC,
Opcode::RET
};
int result = 0;
for (Opcode instruction : program)
{
switch (instruction)
{
case Opcode::HALT:
break;
case Opcode::INC:
++result;
break;
case Opcode::DEC:
--result;
break;
case Opcode::BIT_LEFT:
result <<= 1;
break;
case Opcode::BIT_RIGHT:
result >>= 1;
break;
case Opcode::RET:
std::cout << result;
return 0;
}
}
}这个VM所能做的就是对一个类型的int进行一些简单的操作并打印出来。尽管它值得怀疑是有用的,但它还是说明了这个问题。
VM的关键部分显然是switch循环中的for语句。它的性能取决于许多因素,其中最重要的因素是分支预测和跳到适当执行点( case标签)的动作。
这里有优化的空间。为了加快这个循环的执行速度,人们可以使用所谓的计算gotos。
计算Gotos
计算gotos是Fortran程序员和使用某个(非标准) GCC扩展的人所熟知的构造。我不赞成使用任何非标准、实现定义和(显然)未定义的行为。然而,为了说明这个概念,我将使用上面提到的GCC扩展的语法。
在标准C++中,我们可以定义稍后可以被goto语句跳到的标签:
goto some_label;
some_label:
do_something();这样做被认为不是很好的代码(还有一个很好的理由!)。尽管反对使用goto (其中大部分与代码可维护性相关)有很好的论据,但对于这个令人厌恶的特性,有一个应用程序。这是性能的提高。
语句可以比函数调用更快。 --这是因为“书面文件”的数量,比如设置堆栈和返回值,在调用函数时必须完成。同时,有时可以将goto转换为单个jmp程序集指令。
为了充分利用goto的潜力,对GCC编译器进行了扩展,使goto更具动态性。也就是说,要跳转到的标签可以在运行时确定.
这个扩展允许一个人获得一个标签指针,类似于一个函数指针,并对其进行goto:
void* label_ptr = &&some_label;
goto (*label_ptr);
some_label:
do_something();这是一个有趣的概念,它允许我们进一步增强我们的简单VM。我们将不使用switch语句,而是使用一个标签指针数组(一个所谓的跳转表),而不是将goto用于适当的指针(操作码将用于索引数组):
// [Courtesy of Eli Bendersky][4]
// This code is licensed with the [Unlicense][5]
int interp_cgoto(unsigned char* code, int initval) {
/* The indices of labels in the dispatch_table are the relevant opcodes
*/
static void* dispatch_table[] = {
&&do_halt, &&do_inc, &&do_dec, &&do_mul2,
&&do_div2, &&do_add7, &&do_neg};
#define DISPATCH() goto *dispatch_table[code[pc++]]
int pc = 0;
int val = initval;
DISPATCH();
while (1) {
do_halt:
return val;
do_inc:
val++;
DISPATCH();
do_dec:
val--;
DISPATCH();
do_mul2:
val *= 2;
DISPATCH();
do_div2:
val /= 2;
DISPATCH();
do_add7:
val += 7;
DISPATCH();
do_neg:
val = -val;
DISPATCH();
}
}这个版本比使用switch的版本快25% (链接博客上的版本,而不是上面的)。这是因为每次操作后只执行一次跳转,而不是两次跳转。
使用switch控制流:
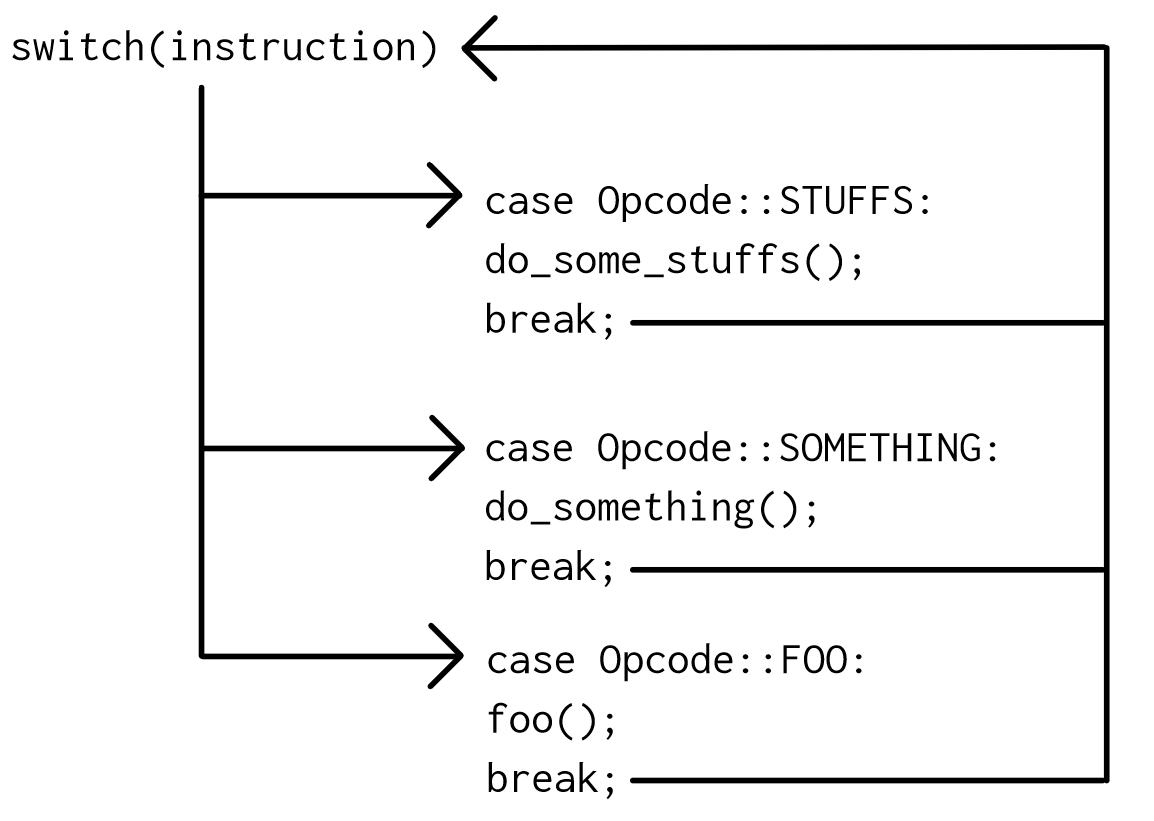
例如,如果我们希望执行Opcode::FOO,然后执行Opcode::SOMETHING,则如下所示:
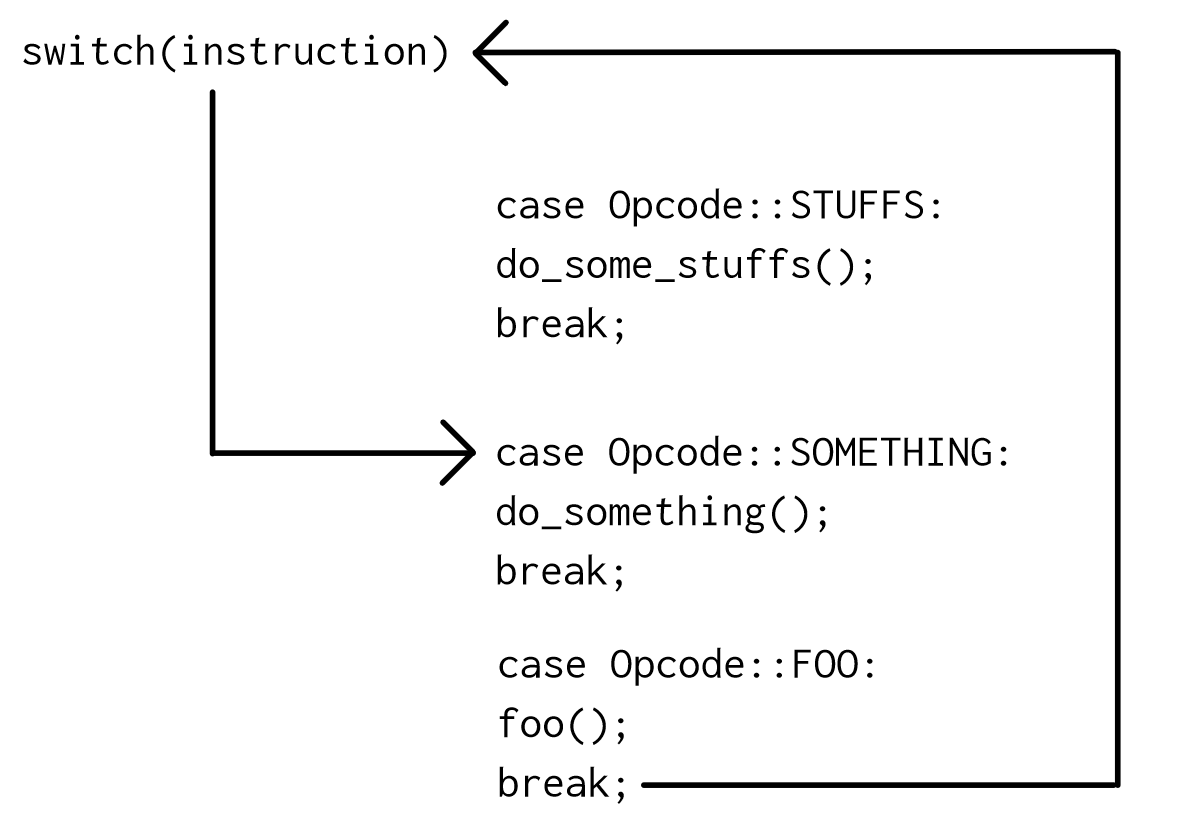
如您所见,在执行一条指令之后,将执行两次跳转。第一个返回到switch代码,第二个返回到实际指令。
相反,如果我们使用一个标签指针数组(作为提醒,它们是不标准的),我们将只有一个跳转:

值得注意的是,除了通过减少操作来节省周期之外,我们还通过消除额外跳转来提高分支预测的质量。
现在,我们知道,通过使用标签指针数组而不是switch,我们可以显着地提高VM的性能(大约20%)。我想也许这也有其他的应用。
我得出的结论是,这种技术可以用于任何具有循环的程序,在该循环中,它依次间接地分配某些逻辑。这方面的一个简单示例(除了VM)可以是在多态对象容器的每个元素上调用virtual方法:
std::vector<Base*> objects;
objects = get_objects();
for (auto object : objects)
{
object->foo();
}现在,这有更多的应用程序。
但是有一个问题:在标准C++中没有诸如标签指针之类的东西。因此,问题是:是否有一种方法可以模拟标准C++ 中计算出的C++s的行为,从而在性能上与它们相匹配?。
编辑1:
使用这个开关还有另一个缺点。user1937198提醒我这件事。这是绑定检查。简而言之,它检查switch中变量的值是否与任何case的值相匹配。它增加了冗余分支(此检查是标准要求的)。
编辑2:
回应校长,我将澄清我关于减少虚拟函数调用开销的想法是什么。解决这个问题的一种方法是在每个表示其类型的派生实例中都有一个id,用于索引跳转表(标签指针数组)。问题是:
- 没有跳转表是标准的C++
- 当添加新的派生类时,需要修改所有跳转表。
如果有人想出某种类型的模板魔术(或作为最后手段的宏),让它更干净、更可扩展和更自动化,我会很感激,如下所示:
回答 1
Stack Overflow用户
发布于 2019-11-08 22:36:49
在MSVC的最新版本中,关键是给优化器提供它需要的提示,这样它就可以知道,仅仅在跳转表中索引是一种安全的转换。原始代码上有两个约束可以阻止这种情况,从而使优化由计算的标签代码生成的代码成为无效的转换。
首先在原代码中,如果程序计数器溢出程序,则循环退出。在计算的标签代码中,调用未定义的行为(取消引用超出范围的索引)。因此,编译器必须为此插入一个检查,从而导致它为循环头生成一个基本块,而不是在每个开关块中进行内联。
其次,在原始代码中,不处理默认情况。虽然开关涵盖了所有枚举值,因此它是没有分支匹配的未定义的行为,但msvc优化器没有足够的智能来利用这一点,因此生成一个默认的大小写,它什么也不做。检查此默认大小写需要一个条件,因为它处理大量的值。在这种情况下,计算的goto代码也会调用未定义的行为。
第一个问题的解决办法很简单。不要对循环使用c++范围,使用with循环或不带条件的for循环。第二个问题的解决方案需要特定于平台的代码来告诉优化器默认是_assume(0)形式的未定义行为,但是在大多数编译器(__builtin_unreachable()在clang和gcc中)中存在类似的东西,并且在没有任何正确性问题的情况下可以有条件地编译为零。
这样做的结果是:
#include <iostream>
enum class Opcode
{
HALT,
INC,
DEC,
BIT_LEFT,
BIT_RIGHT,
RET
};
int run(Opcode* program) {
int result = 0;
for (int i = 0; true;i++)
{
auto instruction = program[i];
switch (instruction)
{
case Opcode::HALT:
break;
case Opcode::INC:
++result;
break;
case Opcode::DEC:
--result;
break;
case Opcode::BIT_LEFT:
result <<= 1;
break;
case Opcode::BIT_RIGHT:
result >>= 1;
break;
case Opcode::RET:
std::cout << result;
return 0;
default:
__assume(0);
}
}
}生成的程序集可以在哥德波特上进行验证。
https://stackoverflow.com/questions/58774170
复制相似问题
腾讯云开发者
