
文本预测的LSTM神经网络问题
文本预测的LSTM神经网络问题
提问于 2019-11-08 10:22:48
我正在尝试使用递归神经网络(LSTM)和书本数据集来进行文本预测。无论我如何尝试改变层的大小或其他参数,它总是适合的。
我一直在尝试改变层的数量,LSTM层中的单元数量,正则化,规范化,batch_size,洗牌训练数据/验证数据,将数据集更改为更大。现在我试着用~140 txt的txt书。我也尝试了200 5mb,1mb,5MB。
创建培训/验证数据:
sequence_length = 30
x_data = []
y_data = []
for i in range(0, len(text) - sequence_length, 1):
x_sequence = text[i:i + sequence_length]
y_label = text[i + sequence_length]
x_data.append([char2idx[char] for char in x_sequence])
y_data.append(char2idx[y_label])
X = np.reshape(x_data, (data_length, sequence_length, 1))
X = X/float(vocab_length)
y = np_utils.to_categorical(y_data)
# Split into training and testing set, shuffle data
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, shuffle=False)
# Shuffle testing set
X_test, y_test = shuffle(X_test, y_test, random_state=0)创建模型:
model = Sequential()
model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]), return_sequences=True, recurrent_initializer='glorot_uniform', recurrent_dropout=0.3))
model.add(LSTM(256, return_sequences=True, recurrent_initializer='glorot_uniform', recurrent_dropout=0.3))
model.add(LSTM(256, recurrent_initializer='glorot_uniform', recurrent_dropout=0.3))
model.add(Dropout(0.2))
model.add(Dense(y.shape[1], activation='softmax'))

编译模型:
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])我有以下特点:
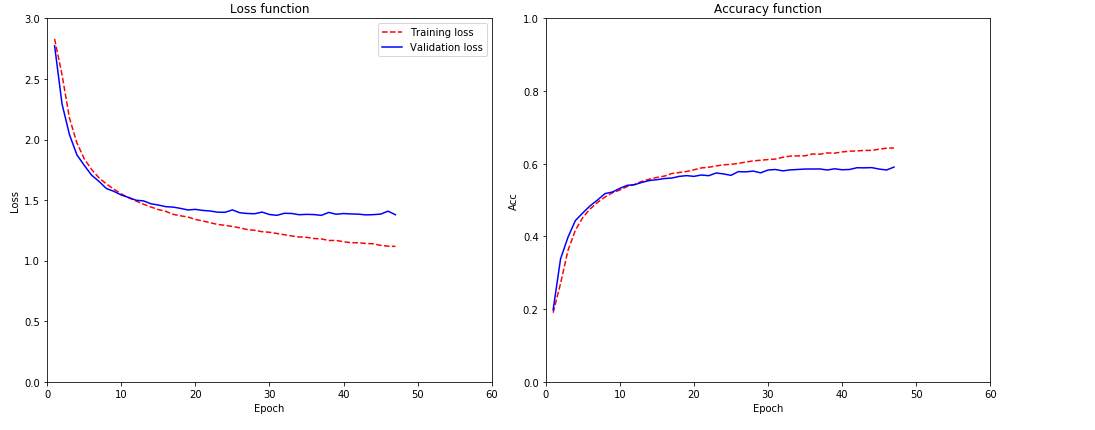
我不知道该怎么办,因为我正在搜索互联网,尝试了很多东西,但似乎都没有用。
我怎么能得到更好的结果?这些预测现在似乎不太好。
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-11-09 03:55:12
下面是我接下来要尝试的一些事情。(我也是个业余爱好者。如果我错了,请纠正我)
- 尝试从文本中提取向量表示。试试word2vec,GloVe,FastText,ELMo。提取向量表示,然后将它们输入网络。您还可以创建一个嵌入层来帮助解决这个问题。这个博客有更多的信息。
- 256个经常性单位可能太多了。我认为一个人不应该从一个庞大的网络开始。从小开始。看看你是不是不合身。如果是,那就再大一点。
- 关闭优化器。我发现亚当太适合了。我最好用瑞丝道普和阿德罗塔来成功。
- 也许,你只需要注意吗?变形金刚最近对NLP做出了巨大贡献。也许您可以在您的网络中尝试简单软注意机制的实现。这是一个不错的视频系列,如果你还不熟悉的话。上面有个互动式研究论文。
- 美国有线电视新闻网也是漂亮的毒品在NLP的应用程序。尽管从直觉上看,它们对文本数据没有任何意义(对大多数人来说)。也许你可以试着利用它们,叠起来,等等。这是一个关于如何使用它进行句子分类的指南。我知道,你的域名不一样。但我认为直觉会延续下去。:)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58764687
复制相关文章
相似问题
腾讯云开发者
