
Google中的IMPORTXML函数
Google中的IMPORTXML函数
提问于 2019-10-31 03:47:11
使用IMPORTXML函数,是否可以构造一个XPATH来提取给定维基百科页面的行业值?
例如,我想从这个页面中提取的值-- 公司 --是“零售”,而在这个页面上-- https://en.wikipedia.org/wiki/Boohoo.com --它将是“时尚”。
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-10-31 05:03:08
- 您希望创建xpath,用于检索给定Wikipedia页面的Industry。
如果我的理解是正确的,和其他模式一样,那么使用这个xpath的公式如何?请把这看作是几个答案中的一个。
样本公式:
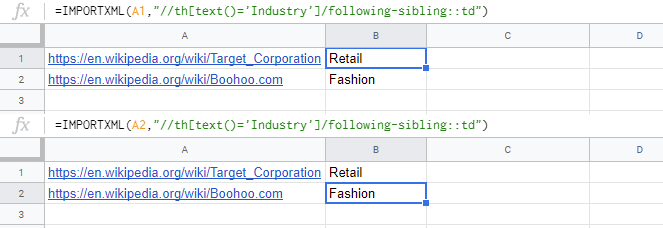
=IMPORTXML(A1,"//th[text()='Industry']/following-sibling::td")- xpath是
//th[text()='Industry']/following-sibling::td。 - 在本例中,
https://en.wikipedia.org/wiki/Target_Corporation或https://en.wikipedia.org/wiki/Boohoo.com的URL放在单元格"A1“中。
结果:
参考资料:
添加:
从您的回复中,我知道您想再添加两个URL。所以所有的URL如下所示。
https://en.wikipedia.org/wiki/Target_Corporation- `https://en.wikipedia.org/wiki/Boohoo.com
- `https://en.wikipedia.org/wiki/Woot
- `https://en.wikipedia.org/wiki/TripAdvisor
问题和解决办法:
对于上述URL,当使用=IMPORTXML(A1,"//th[text()='Industry']/following-sibling::td")公式时,将返回Retail、Fashion、Retail和Travel, services。
当xpath被修改为//th[text()='Industry']/following-sibling::td/a时,将返回Retail、#N/A、#N/A和Travel。
造成这种情况的原因是以下差异。
<tr>
<th scope="row">Industry</th>
<td class="category"><a href="/wiki/Travel" title="Travel">Travel</a> services</td>
</tr>和
<tr>
<th scope="row" style="padding-right:0.5em;">Industry</th>
<td class="category" style="line-height:1.35em;"><a href="/wiki/Retail" title="Retail">Retail</a></td>
</tr>和
<tr>
<th scope="row" style="padding-right:0.5em;">Industry</th>
<td class="category" style="line-height:1.35em;">Fashion</td>
</tr>由此,我认为不幸的是,为了从上面检索Travel、Retail和Fashion,只能使用一个xpath就不能直接检索它们。所以我在这种情况下使用了内置函数。
解决办法:
在这个解决方案中,我使用了INDEX。请把这看作是几个答案中的一个。
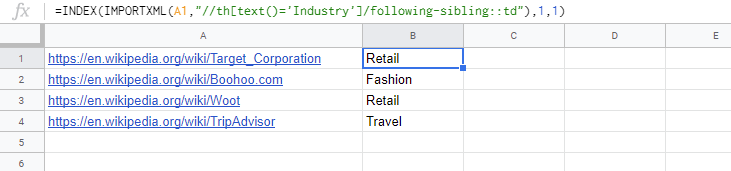
=INDEX(IMPORTXML(A1,"//th[text()='Industry']/following-sibling::td"),1,1)- xpath是
//th[text()='Industry']/following-sibling::td。这是没有修改的。 - 在本例中,URL放在单元格"A1“中。
- 当检索到2个值时,检索第一个值。通过这个,我使用了
INDEX。
结果:
Stack Overflow用户
发布于 2019-10-31 03:56:57
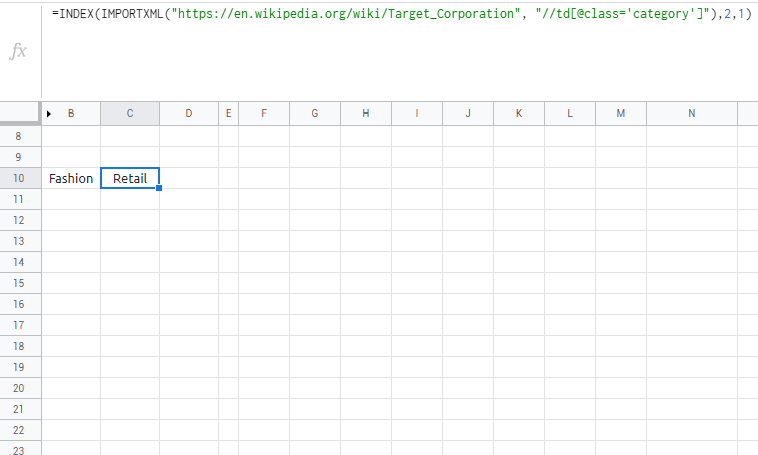
尝试:
=INDEX(IMPORTXML("https://en.wikipedia.org/wiki/Boohoo.com",
"//td[@class='category']"), 2, 1)=INDEX(IMPORTXML("https://en.wikipedia.org/wiki/Target_Corporation",
"//td[@class='category']"),2,1)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58636667
复制相关文章
相似问题
腾讯云开发者
