
使用的文档间的余弦相似性和TS-SS相似性
使用的文档间的余弦相似性和TS-SS相似性
提问于 2019-10-23 18:49:21
计算基于文本的文档间的余弦相似度的一种常用方法是计算tf,然后计算tf矩阵的线性核。
用TfidfVectorizer()计算TF-国防军矩阵。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix_content = tfidf.fit_transform(article_master['stemmed_content'])这里,article_master是一个包含所有文档文本内容的数据格式。
正如Chris 这里所解释的,TfidfVectorizer生成标准化向量;因此linear_kernel结果可以用作余弦相似性。
cosine_sim_content = linear_kernel(tfidf_matrix_content, tfidf_matrix_content)
,这就是我困惑的地方。
有效地,两个向量之间的余弦相似性是:
InnerProduct(vec1,vec2) / (VectorSize(vec1) * VectorSize(vec2))线性核计算InnerProduct作为声明的这里
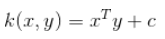
所以问题是:
- 为什么我不用向量大小的乘积来分割内积呢?
- 为什么正常化使我免除了这一要求?
- 现在,如果我想计算ts-ss相似,我还能使用规范化的tf-国防军矩阵和余弦值(仅由线性核计算)吗?
Stack Overflow用户
发布于 2019-10-24 21:39:57
多亏了@timleathart的回答这里,我终于知道了原因。
标准化向量的震级为1,所以不管你是否显式除以震级。无论哪种方法,它在数学上都是等价的。
对每个行(向量)进行归一化,使其全部长度为1。由于余弦相似性仅与角度有关,因此向量的大小差异并不重要。
使用ts-ss的主要原因是考虑了矢量的角度和大小的差异。因此,即使使用标准化向量没有什么错;然而,这超出了使用三角形相似组件的全部目的。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58529311
复制相关文章
相似问题
腾讯云开发者
