
是否有更好的方法通过加入Redshift来避免数据倾斜?
如下所示的查询SQL导致红移群集磁盘的一个节点已满
insert
into
report.agg_info
( pd ,idate ,idate_str ,app_class ,app_superset ,aid ,pf ,is ,camp ,ua_camp_id ,country ,is_predict ,cohort_size ,new_users ,retained ,acc_re ,day_iap_rev ,iap_rev ,day_rev ,rev )
select
p.pd ,
p.idate ,
p.idate_str ,
p.app_class ,
p.app_superset ,
p.aid ,
p.pf ,
p.is ,
p.camp ,
p.ua_camp_id ,
p.country ,
1 as is_predict ,
p.cohort_size ,
p.new_users ,
p.retained ,
ar.acc_re ,
p.day_iap_rev ,
ar.iap_rev ,
p.day_rev ,
ar.rev
from
tmp_predict p
join
tmp_accumulate ar
on p.pd = ar.pd
and p.idate = ar.idate
and p.aid = ar.aid
and p.pf = ar.pf
and p.is = ar.is
and p.camp = ar.camp
and p.ua_camp_id = ar.ua_camp_id
and p.country = ar.country查询计划是
XN Hash Join DS_DIST_BOTH (cost=11863664.64..218084556052252.12 rows=23020733790769 width=218)
-> XN Seq Scan on tmp_predict p (cost=0.00..3954554.88 rows=395455488 width=188)
-> XN Hash (cost=3954554.88..3954554.88 rows=395455488 width=165)
-> XN Seq Scan on tmp_accumulate ar (cost=0.00..3954554.88 rows=395455488 width=165)
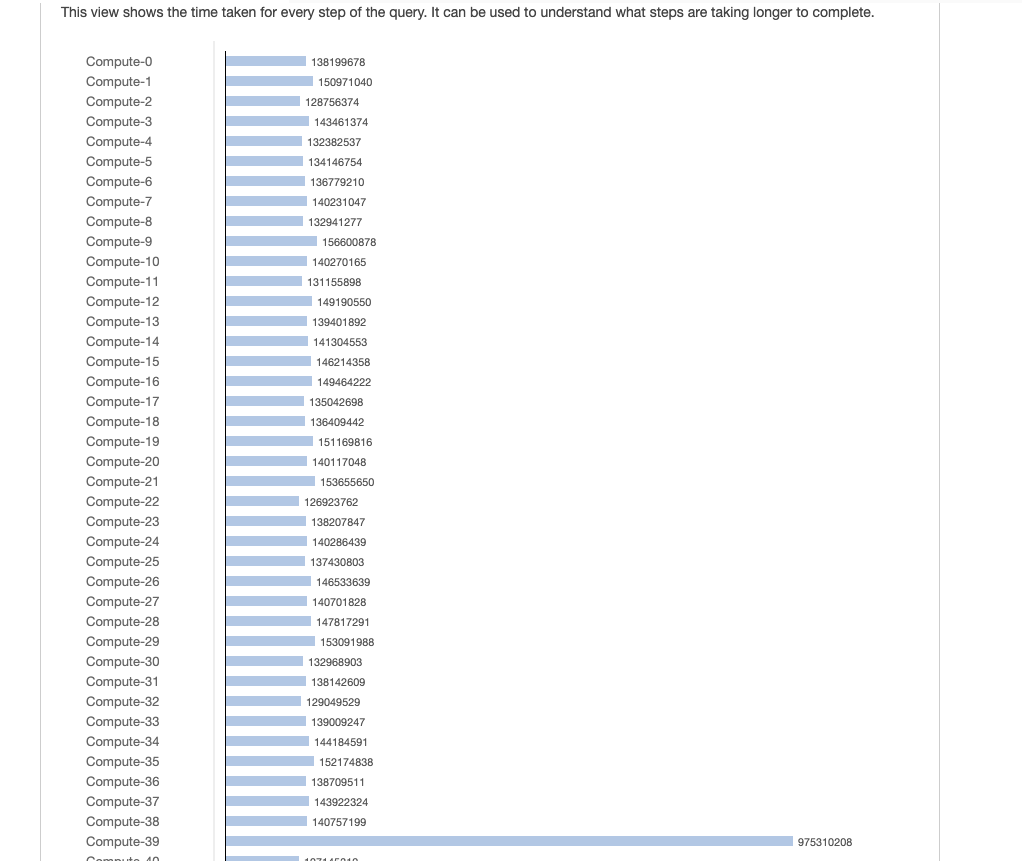
从上面的图像中我们知道node-39比其他节点保存更多的数据。因为数据被join扭曲了。
为了解决这个问题,我们尝试使用update而不是join。
update
report.agg_info
set
acc_re = ar.acc_re,
iap_rev = ar.iap_rev,
rev = ar.rev
from
tmp_accumulate ar
where
report.agg_info.pd = ar.pd
and report.agg_info.idate = ar.idate
and report.agg_info.aid = ar.aid
and report.agg_info.pf = ar.pf
and report.agg_info.is = ar.is
and report.agg_info.camp = ar.camp
and report.agg_info.ua_camp_id = ar.ua_camp_id
and report.agg_info.country = ar.country查询计划
XN Hash Join DS_BCAST_INNER (cost=11863664.64..711819961371132.00 rows=91602 width=254)
-> XN Seq Scan on agg_info (cost=0.00..2.70 rows=270 width=224)
-> XN Hash (cost=3954554.88..3954554.88 rows=395455488 width=170)
-> XN Seq Scan on tmp_accumulate ar (cost=0.00..3954554.88 rows=395455488 width=170)
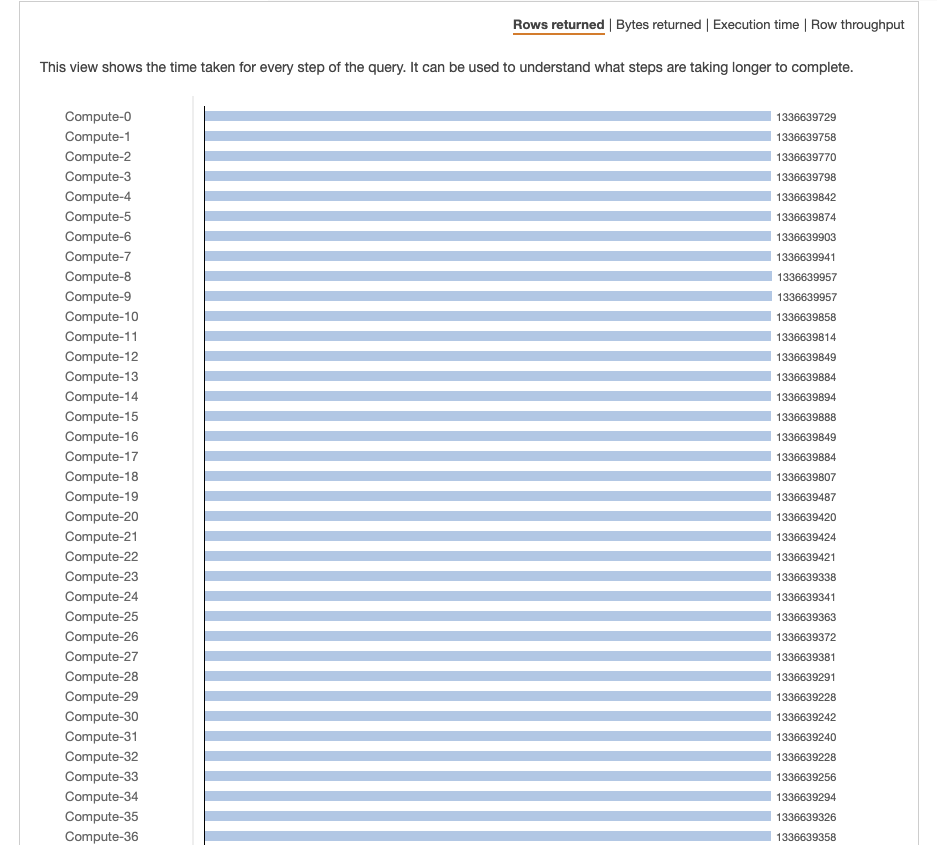
根据图片,数据均匀分布在所有节点上。但是,每个节点中有更多的数据。
我想知道,是否有通过加入Redshift来处理数据倾斜的最佳实践?
回答 2
Stack Overflow用户
发布于 2019-10-21 14:22:57
https://docs.aws.amazon.com/redshift/latest/dg/c-analyzing-the-query-plan.html
寻找成本较高的广播运营商:
· DS_BCAST_INNER:指示表被广播到所有计算节点,这对于一个小表来说很好,但对于一个较大的表来说并不理想。
· DS_DIST_ALL_INNER:指示所有工作负载都在单个片上。
· DS_DIST_BOTH:表示重分布。
第一个查询中的DS_DIST_BOTH将在特定列上重新分发两个表。您还没有在EXPLAIN片段中包含所选择的列,但它可能是联接中的第一列。
DS_BCAST_INNER正在向每个节点广播tmp_accumulate的完整副本。这两种操作都非常昂贵和缓慢。
您的连接非常广泛,似乎第一列是非常倾斜的。您可以尝试两种方法来解决倾斜和防止广播:
- 更改在join中声明的列的顺序,以首先声明最惟一(或最不偏斜)列。第一列通常将用作重新分配键。(注意:如果表已经是diststyle键,这是行不通的。)
- 建议。由于连接是如此复杂和倾斜,您可以在这些列中预先计算一个散列值,然后对该值进行连接。
--Example of Pre-Calculated Hash
CREATE TEMP TABLE tmp_predict
DISTKEY(dist_hash)
AS SELECT FUNC_SHA1(pd||idate::VARCHAR||aid::VARCHAR||pf::VARCHAR
||is::VARCHAR||camp::VARCHAR||ua_camp_id::VARCHAR
||country::VARCHAR) dist_hash
,pd ,idate ,aid ,pf ,is ,camp ,ua_camp_id, country
,…
FROM …
;
CREATE TEMP TABLE tmp_accumulate
DISTKEY(dist_hash)
AS SELECT FUNC_SHA1(pd||idate::VARCHAR||aid::VARCHAR||pf::VARCHAR
||is::VARCHAR||camp::VARCHAR||ua_camp_id::VARCHAR
||country::VARCHAR) dist_hash
,pd ,idate ,aid ,pf ,is ,camp ,ua_camp_id, country
,…
FROM …
;
INSERT INTO report.agg_info
SELECT …
FROM tmp_predict p
JOIN tmp_accumulate ar
ON p.dist_hash = ar.dist_hash
;Stack Overflow用户
发布于 2019-10-21 12:37:46
数据是倾斜的,因为您要加入的表似乎在一个节点上拥有它的所有数据。这可能是因为没有DISTKEY,或者DISTKEY是高度倾斜的。
因此,您可以使用DISTSTYLE均匀地在所有节点上分发该表的数据,也可以选择不同的DISTKEY,它在数据中具有更多的分布。
https://stackoverflow.com/questions/58484326
复制相似问题
腾讯云开发者
