
添加一个Pandas列,该列连接来自另一个df的匹配值。
添加一个Pandas列,该列连接来自另一个df的匹配值。
提问于 2019-10-16 16:18:32
我正在尝试在熊猫中创建一个新的列,它连接来自另一个匹配特定条件的数据的值。
如果我有数据、库存和产品作为输入:
Inventory
Category All_SKU
Apple NaN
Banana NaN
Oranges NaN
Products
Product Category SKU
Macintosh Apple 4123
Gala Apple 4356
Navel Oranges 5897
Cara Cara Oranges 5324
Red Delicious Apple 4896
Cavendish Banana 7895我希望输出是
Inventory
Category All_SKU
Apple 4123; 4356; 4896
Oranges 5897; 5324
Banana 7895我已经尝试过这个(和其他方法),但是得到了一个关键错误。不确定这是否是最好的方法,或者是否有更好的方法来解决这个问题。
for row in Products.index:
InvRow=Inventory.index[Inventory['Category'] == Products['Category',row]]
Inventory['All_SKU',InvRow]=Inventory['All_SKU',InvRow] + "; "+ Products['SKU',row]回答 4
Stack Overflow用户
回答已采纳
发布于 2019-10-16 17:00:30
您可以使用groupby.apply + Series.map
Inventory['All_SKU']=( Inventory['Category']
.map(products[products['Category'].isin(Inventory['Category'])]
.groupby('Category')['SKU']
.apply(lambda x: ','.join(x.astype(str)))) )
print(Inventory) Category All_SKU
0 Apple 4123,4356,4896
1 Banana 7895
2 Oranges 5897,5324Stack Overflow用户
发布于 2019-10-16 16:36:44
像这样的事应该能行
Products.groupby('Category').SKU.apply(lambda x: ';'.join(list(str(i) for i in list(x))))
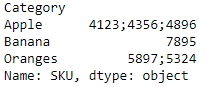
然而,如果我是你,我会使用列表而不是字符串。
Stack Overflow用户
发布于 2019-10-16 16:46:04
您可以像下面这样使用组来完成这个任务。
df = pd.DataFrame([['Macintosh', 'Apple', '4123'], ['Gala', 'Apple', '4356'], ['Navel', 'Oranges', '5897'], ['Cara Cara', 'Oranges', '5324'], ['Red Delicious', 'Apple', '4896'], ['Cavendish', 'Banana', '7895']], columns=('Product', 'Category', 'SKU'))
result = df.groupby("Category")["SKU"].apply(list).str.join(";")如果要将结果限制为库存数据表中的类别,可以使用以下合并
df_inventory.merge(df, on="Category")页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58417719
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号