
电影评论爬行
电影评论爬行
提问于 2019-10-12 06:34:24
我想在这页上爬行所有这些电影评论。红圈中的哪一部分
{kind=link}
我试着用这个代码爬行。(我使用了木星笔记本-Anaconda3 3)
import requests
from bs4 import BeautifulSoup
test_url = "https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code=174903&type=after&page=1"
resp = requests.get(test_url)
soup = BeautifulSoup(resp.content, 'html.parser')
soupscore_result = soup.find('div', {'class': 'score_result'})
lis = score_result.findAll('li')
lis[:3]from urllib.request import urljoin #When I ran this block and next block it didn't save any reviews.
review_text=[]
#review_text = lis[0].find('p').getText()
list_soup =soup.find_all('li', 'p')
for item in list_soup:
review_text.append(item.find('p').get_text())review_text[:5] #Nothing was saved.正如我在第三块和第四块中所写的那样,没有保存任何东西。有什么问题吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-10-12 07:15:22
这会得到你想要的。在木星笔记本中的巨蟒中进行测试(最新)
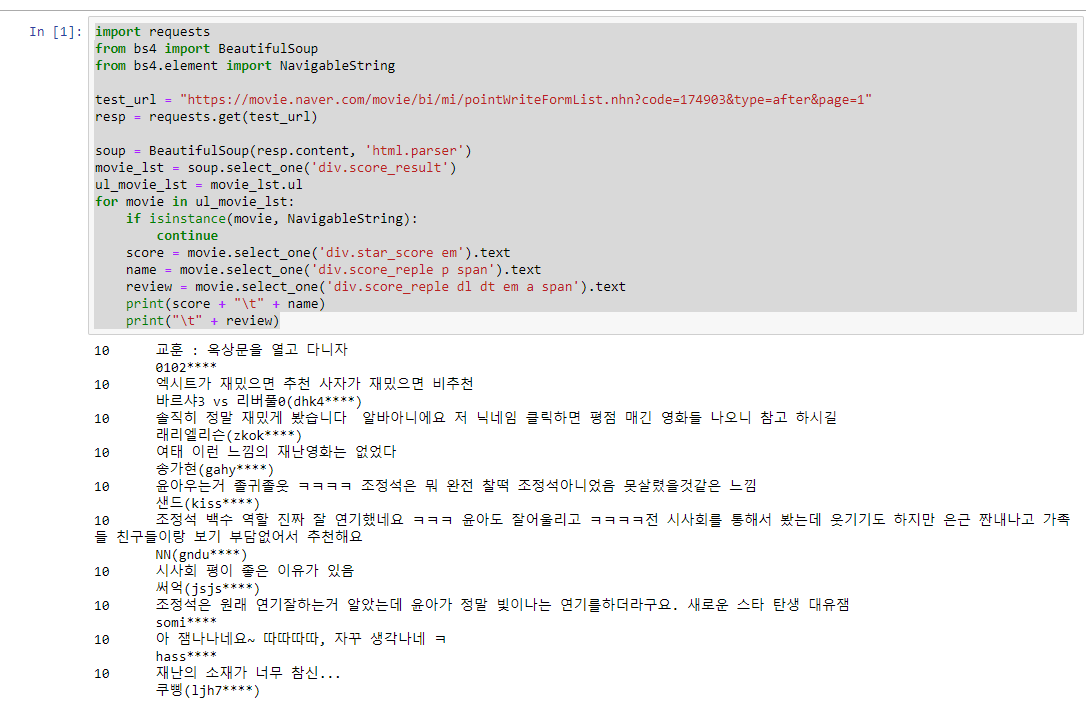
import requests
from bs4 import BeautifulSoup
from bs4.element import NavigableString
test_url = "https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code=174903&type=after&page=1"
resp = requests.get(test_url)
soup = BeautifulSoup(resp.content, 'html.parser')
movie_lst = soup.select_one('div.score_result')
ul_movie_lst = movie_lst.ul
for movie in ul_movie_lst:
if isinstance(movie, NavigableString):
continue
score = movie.select_one('div.star_score em').text
name = movie.select_one('div.score_reple p span').text
review = movie.select_one('div.score_reple dl dt em a span').text
print(score + "\t" + name)
print("\t" + review)预览
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58351530
复制相关文章
相似问题
腾讯云开发者
