
如何在DBFS中保存和下载本地csv?
如何在DBFS中保存和下载本地csv?
提问于 2019-10-08 14:10:52
由于SQL查询,我试图保存csv文件,通过Databricks发送给Athena。该文件应该是一个4-6 GB (约40米行)的大表。
我正在做接下来的步骤:
- 通过以下方式创建PySpark数据框架: df =sqlContext.sql(“从my_table中选择*,其中年份= 19")
- 将PySpark数据转换为Pandas数据。我意识到,这一步可能是不必要的,但我只开始使用Databricks,可能不知道更快地执行所需的命令。所以我就这样做: ab = df.toPandas()
- 将文件保存在某个地方,以便稍后在本地下载: ab.to_csv('my_my.csv')
但是我怎么下载呢?
我恳请您非常具体,因为我不知道在使用Databricks时的许多技巧和细节。
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-10-23 07:36:43
使用GUI,您可以下载完整的结果(最多100万行)。
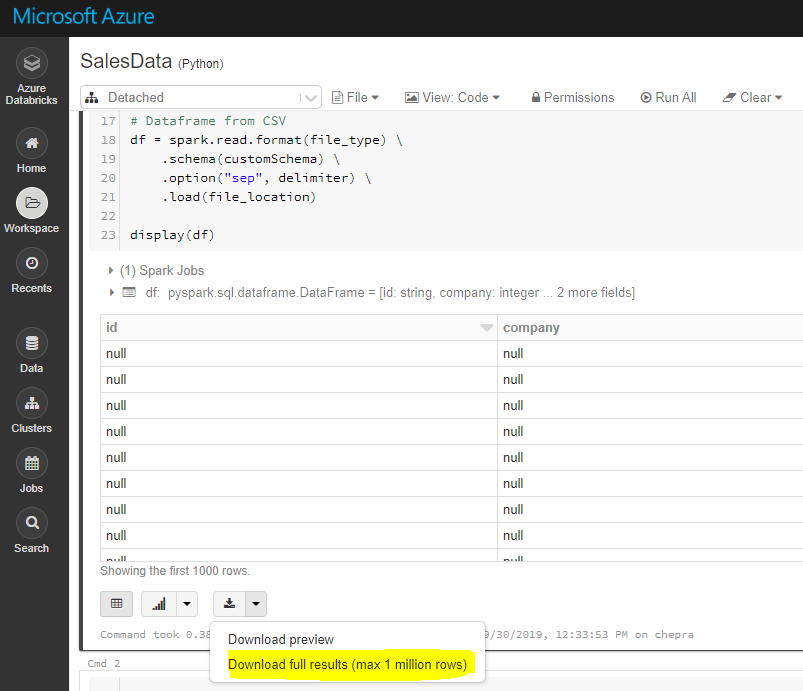
要下载完整的结果,首先将文件保存到dbfs,然后使用Databricks cli将文件复制到本地机器,如下所示。
dbfs cp“dbfs:/FileStore/table/my_my.csv”"A:\AzureAnalytics“
参考: 数据库文件系统
DBFS命令行接口(CLI)使用DBFS向DBFS公开一个易于使用的命令行接口。使用此客户端,您可以使用类似于Unix命令行中使用的命令与DBFS交互。例如:
# List files in DBFS
dbfs ls
# Put local file ./apple.txt to dbfs:/apple.txt
dbfs cp ./apple.txt dbfs:/apple.txt
# Get dbfs:/apple.txt and save to local file ./apple.txt
dbfs cp dbfs:/apple.txt ./apple.txt
# Recursively put local dir ./banana to dbfs:/banana
dbfs cp -r ./banana dbfs:/banana参考: 安装和配置Azure数据库CLI
希望这能有所帮助。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58288111
复制相关文章
相似问题
腾讯云开发者
