
如何对旧/新值的列排序,使ith旧值=(i-1)的新值
编辑:欢迎标题建议。这可能有一个名字,但我不知道它是什么,也找不到类似的东西。
Edit2:,我重写了这个问题,试图更清楚地解释它。在这两个版本中,我认为我已经达到了网站标准,我提出了一个解释,可复制的例子,以及我自己的解决方案.如果你能在投票前提出改进建议,我们将不胜感激。
我已经用户从包含以下三列的系统中输入了数据:
- 日期:
%Y-%m-%d %H:%M:%S格式的时间戳;但是所有情况下都是%S=00 - 旧的:这个观察的旧价值
- 新的:这个观察的新价值
如果用户在同一分钟内输入数据,那么仅按时间戳进行排序是不够的。我们最终得到了一个“块”条目,这些条目的顺序可能是正确的,也可能不是正确的。为了说明这一点,我用整数替换了日期,并给出了一个正确和混乱的情况:
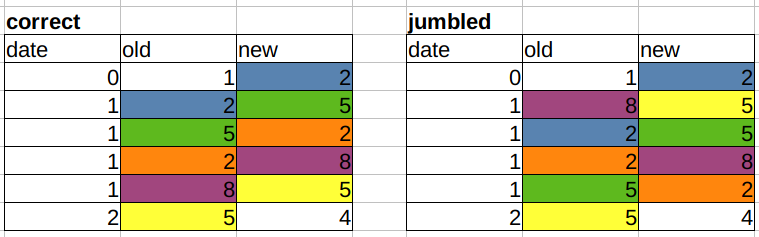
我们如何知道数据的顺序是正确的?当old的每行值等于new的上一行值时(忽略第一行/最后一行,我们没有什么可比较的)。换句话说:old_i = new_(i-1)。这将在左边创建匹配的对角线颜色,这些颜色在右边是杂乱的。
其他评论:
- 可能有多个解决方案,因为两行对于
old和new可能具有相同的值,因此是可插入的。 - 如果一个模棱两可的块本身出现(假设数据只是上面
date=1的行),那么任何解决方案都足够了。 - 如果歧义块在出现之前和/或之后具有唯一日期,则这些都是附加的约束,必须考虑才能实现解决方案。
- 将背靠背模糊块作为奖励;我计划忽略这些,并且不确定它们是否存在于数据中。
我的数据集要大得多,所以我的最终解决方案将涉及使用pandas.groupby()来提供像上面这样的函数块。右侧将被传递给函数,我需要返回左侧(或一些索引/命令将我带到左侧)。
下面是一个可重复的示例,使用与上面相同的数据,但是添加一个group列和另一个块,这样您就可以看到我的groupby()解决方案了。
设置和输入混乱的数据:
import pandas as pd
import itertools
df = pd.DataFrame({'group': ['a', 'a', 'a', 'a', 'a', 'a', 'b', 'b', 'b'],
'date': [0, 1, 1, 1, 1, 2, 3, 4, 4],
'old': [1, 8, 2, 2, 5, 5, 4, 10, 7],
'new': [2, 5, 5, 8, 2, 4, 7, 1, 10]})
print(df)
### jumbled: the `new` value of a row is not the same as the next row's `old` value
# group date old new
# 0 a 0 1 2
# 1 a 1 8 5
# 2 a 1 2 5
# 3 a 1 2 8
# 4 a 1 5 2
# 5 a 2 5 4
# 6 b 3 4 7
# 7 b 4 10 1
# 8 b 4 7 10我写了一个疯狂的解决方案,要求采用一种更优雅的方法。有关下面调用的这里函数后面的代码,请参见gist order_rows。输出是正确的:
df1 = df.copy()
df1 = df1.groupby(['group'], as_index=False, sort=False).apply(order_rows).reset_index(drop=True)
print(df1)
### correct: the `old` value in each row equals the `new` value of the previous row
# group date old new
# 0 a 0 1 2
# 1 a 1 2 5
# 2 a 1 5 2
# 3 a 1 2 8
# 4 a 1 8 5
# 5 a 2 5 4
# 6 b 3 4 7
# 7 b 4 7 10
# 8 b 4 10 1基于networkx 建议的更新
请注意,上面的符号#2表明,这些不明确的块可以在没有先前的引用行的情况下发生。在这种情况下,作为df.iloc[0]提供起始点是不安全的。此外,我还发现,当用一个不正确的起点播种图时,它似乎只输出它可以成功排序的节点。请注意,传递了5行,但只返回了4个值。
示例:
import networkx as nx
import numpy as np
df = pd.DataFrame({'group': ['a', 'a', 'a', 'a', 'a'],
'date': [1, 1, 1, 1, 1],
'old': [8, 1, 2, 2, 5],
'new': [5, 2, 5, 8, 2]})
g = nx.from_pandas_edgelist(df[['old', 'new']],
source='old',
target='new',
create_using=nx.DiGraph)
ordered = np.asarray(list(nx.algorithms.traversal.edge_dfs(g, df.old[0])))
ordered
# array([[8, 5],
# [5, 2],
# [2, 5],
# [2, 8]])回答 1
Stack Overflow用户
发布于 2019-10-03 17:30:01
这是一个图问题。您可以使用networkx创建图形,然后使用numpy进行操作。一个简单的遍历算法,如深度优先搜索,将访问从源开始的所有边缘。
源只是您的第一个节点(即df.old[0])
以你为例:
import networkx as nx
g = nx.from_pandas_edgelist(df[['old', 'new']],
source='old',
target='new',
create_using=nx.DiGraph)
ordered = np.asarray(list(nx.algorithms.traversal.edge_dfs(g, df.old[0])))>>>ordered
array([[ 1, 2],
[ 2, 5],
[ 5, 2],
[ 2, 8],
[ 8, 5],
[ 5, 4],
[ 4, 7],
[ 7, 10],
[10, 1]])您可以将其重新分配到您的数据框架:df[['old', 'new']] = ordered。您可能需要更改一些小细节,例如,如果您的组不是相互关联的。但是,如果起点是group和date上的排序df,并且对old_i = new_(i-1)的依赖关系受到组间的尊重,那么您应该只需要重新分配ordered数组。
然而,我仍然认为,你应该调查一下你的时间戳。我相信这是一个简单的问题,只需对时间戳进行排序就可以解决。确保您在读取/写入文件时不会丢失时间戳的准确性。
https://stackoverflow.com/questions/58212040
复制相似问题
腾讯云开发者
