
如何使用R为每个ID找到最大连续序列的开始和结束?
如何使用R为每个ID找到最大连续序列的开始和结束?
提问于 2019-09-20 13:10:37
我有一个数据集。每个ID的序列为0和1,日期列和num.day的另一列。我想为每个ID找到最长的1序列的开始和结束,然后计算开始到结束之间的日期间隔。在此之后添加结束日期的相应num.day。
例如,下表ID = 1,最长的序列以日期4(上面的一个记录)开始,以9结尾。因此,间隔为5。相应的结束日期的num.day应该是day_gap = (9-4) +3 = 8。如果一个ID有相同的最长序列,那么对这个ID取这些序列的最大day_gap。
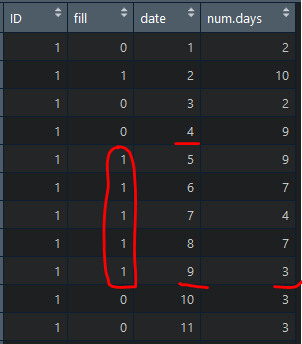
下面是创建虚拟表的代码
library(data.table)
ID=c(rep(1,10),rep(2,10),rep(3,10))
set.seed(1)
fill=sample(c(0,1),length(ID),replace=TRUE)
dat=data.table(ID,fill)[,date:=seq(.N),by="ID"][date==1,fill:=0]
set.seed(1)
dat$num.days=sample(1:10,nrow(dat),replace=TRUE)回答 2
Stack Overflow用户
回答已采纳
发布于 2019-09-20 13:56:12
下面是我使用dplyr的解决方案:
dat %>%
group_by(ID) %>%
mutate(group = cumsum(fill != lag(fill, default = fill[[1]])) + 1) %>%
ungroup() %>%
filter(fill == 1) %>%
group_by(ID, group) %>%
mutate(fill_group_no_max = max(row_number())) %>%
ungroup() %>%
group_by(ID) %>%
filter(fill_group_no_max == max(fill_group_no_max),
group == max(group)) %>%
summarise(dategap = max(date) - min(date) + last(num.days)) %>%
ungroup() 更新:对不起!我忘了总结部分
Stack Overflow用户
发布于 2019-09-23 01:28:52
在base::rle中使用data.table的一个选项
dat[, {
r <- rle(fill)
i <- which.max(r$lengths * r$values)
.(day_gap = r$lengths[i] + num.days[sum(r$lengths[1L:i])])
}, ID]产出:
ID day_gap
1: 1 11
2: 2 12
3: 3 8数据:
library(data.table)
ID = c(rep(1,10),rep(2,10),rep(3,10))
set.seed(1)
fill = sample(c(0,1),length(ID),replace=TRUE)
dat = data.table(ID,fill)[,date:=seq(.N),by="ID"][date==1,fill:=0]
set.seed(1)
dat$num.days=sample(1:10,nrow(dat),replace=TRUE)
datdat
ID fill date num.days
1: 1 0 1 3
2: 1 0 2 4
3: 1 1 3 6
4: 1 1 4 10
5: 1 0 5 3
6: 1 1 6 9
7: 1 1 7 10
8: 1 1 8 7
9: 1 1 9 7
10: 1 0 10 1
11: 2 0 1 3
12: 2 0 2 2
13: 2 1 3 7
14: 2 0 4 4
15: 2 1 5 8
16: 2 0 6 5
17: 2 1 7 8
18: 2 1 8 10
19: 2 0 9 4
20: 2 1 10 8
21: 3 0 1 10
22: 3 0 2 3
23: 3 1 3 7
24: 3 0 4 2
25: 3 0 5 3
26: 3 0 6 4
27: 3 0 7 1
28: 3 0 8 4
29: 3 1 9 9
30: 3 0 10 4
ID fill date num.days页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58029058
复制相关文章
相似问题
腾讯云开发者
