
如何在不删除整个行/列的情况下忽略df中的所有空单元格?
如何在不删除整个行/列的情况下忽略df中的所有空单元格?
提问于 2019-09-19 14:23:38
{kind=link}
{kind=link}
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-09-19 14:33:55
你可以试试这样的东西
library(tidyverse)
set.seed(1234)
df <- tibble(
v1 = sample(c(letters[1:4], rep(NA, 20)), 20, replace = TRUE),
v2 = sample(c(letters[1:4], rep(NA, 20)), 20, replace = TRUE),
v3 = sample(c(letters[1:4], rep(NA, 20)), 20, replace = TRUE),
v4 = sample(c(letters[1:4], rep(NA, 20)), 20, replace = TRUE)
)
df %>%
fill(names(df)) %>%
distinct()
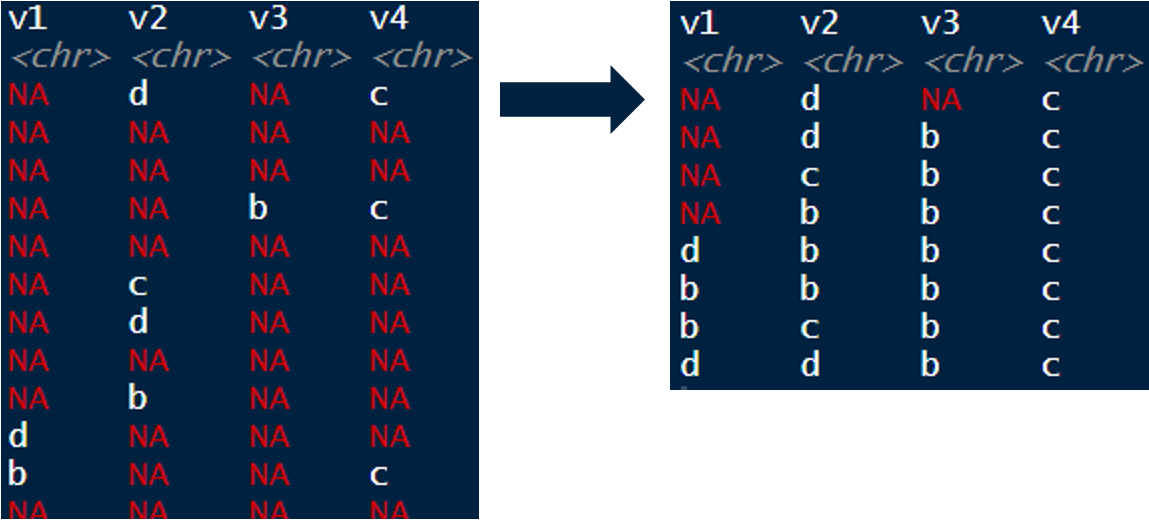
如果您不关心组合体,只想要唯一的值,那么可以这样做:
df %>%
gather() %>%
distinct(key, value) %>%
filter(!is.na(value)) %>%
group_by(key) %>%
arrange(value) %>%
mutate(ord = row_number()) %>%
ungroup() %>%
spread(key, value)
# ord v1 v2 v3 v4
# 1 b b b c
# 2 d c NA NA
# 3 NA d NA NA Stack Overflow用户
发布于 2019-09-19 14:33:03
1)这里的是一个不使用包的单行解决方案。
在每个列上使用na.omit将每个列转换为ts类。然后,cbind将自动处理不同的长度。最后的[TRUE, ]移除ts类。
# test input
DF <- data.frame(V1 = c("a1", NA, "a2"), V2 = c(NA, NA, "a3"),
V3 = c("a4", NA, NA), stringsAsFactors = FALSE)
res1 <- do.call("cbind", lapply(DF, function(x) ts(na.omit(x))))[TRUE, ]给出这个矩阵:
> res1
V1 V2 V3
[1,] "a1" "a3" "a4"
[2,] "a2" NA NA 如果您喜欢数据帧结果,请使用:
as.data.frame(res1, stringsAsFactors = FALSE)2) --这是另一种解决方案,它也是一行,不使用包。它省略NA,然后将结果向量扩展到所需的行数。最后,它将其塑造成一个data.frame。
res2 <- replace(DF, TRUE, lapply(DF, function(x) `length<-`(na.omit(x), nrow(DF))))给这个data.frame:
> res2
V1 V2 V3
1 a1 a3 a4
2 a2 <NA> <NA>
3 <NA> <NA> <NA>这一项略有不同,因为它产生的是data.frame而不是矩阵,它使生成的data.frame与输入具有相同的维度。如果您想删除所有NA的行,那么
res2[rowSums(!is.na(res)) > 0, ]
## V1 V2 V3
## 1 a1 a3 a4
## 2 a2 <NA> <NA>页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58013202
复制相关文章
相似问题
腾讯云开发者
