
Python:修改和编辑函数中的数据
我有如下所示的数据格式:
import pandas as pd
df = pd.DataFrame( {'Tester1': ['A','B','C','A','B','E','F','A','E','B','C','C'],
'Tester2':['D','A','E','A','B','F','F','A','B','B','A','C'],
'Day':['1','1','1','1','1','1','1','2','2','2','2','2'],
'Value':['-0.94','0.48','-0.79','-0.46','-1.02','0.31','-2.21','-2.1','-0.86','0.52','-0.23','0.71']})我想做以下几个步骤:
(
- a)每天查看数据。例如,首先查看
Day == 1 - b),按照
Value - c)的降序对数据子集进行排序,取值最高的
Tester对,并将其附加到列表中,并保存以备将来使用(注意,测试人员对可以是相同的,也可以是不同的。例如,Tester A和Tester B或Tester A和Tester A. - d)从包含的子集中删除所有数据((谢@smci)测试1或 Tester 2,其值最高。
重复步骤c),d)直到完成某一天的所有观察为止。重复,直到数据集中的所有日子都完成为止。
我现在的代码是:
day_list=list(set(d2['Day']))
data_list=[]
for day in day_list:
# Creating subset of the data for days in the day_list - (Step a)
data_per_day=d2[d2['Day']==day]
for i in range(len(data_per_day)):
# Sorting the data in descending order by value
sorted_data_per_day=data_per_day.sort_values('Value',ascending=False)
# Taking the top observation and appending it to data list - (Step b & c)
zz=sorted_data_per_day.iloc[0,:].to_frame().T
data_list.append(zz)
# Creating a list of testers in the data which was stored - (Step d)
tester_list1=(zz['Tester1'].iloc[0],zz['Tester2'].iloc[0])
tester_list=list(set(tester_list1))
# Removing all observations which contain Tester 1 or Tester 2 - (Step d contd.)
sorted_data_per_day1=sorted_data_per_day[~sorted_data_per_day['Tester1'].isin(tester_list)]
sorted_data_per_day2=sorted_data_per_day1[~sorted_data_per_day1['Tester2'].isin(tester_list)]
sorted_data_per_day=sorted_data_per_day2
data_list2=pd.concat(data_list,axis=0)Day == 1的输出示例如下:
对于步骤a) & b) -获取的数据子集和值被排序
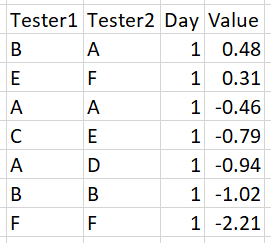
对于步骤c),使用最高值的测试器对

对于步骤d)移除所有包含A或B的测试器对。

在这个新的观察集中重复上述所有步骤。
现在,我得到的信息如下:
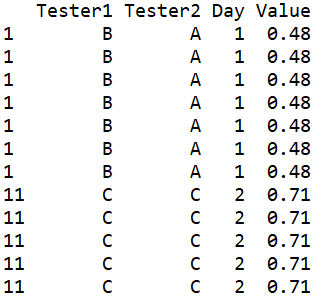
我有一种直觉,我在代码的这两个步骤上犯了一个错误:
i) for i in range(len(data_per_day)) # Should I change this to a while loop?
(二) sorted_data_per_day=sorted_data_per_day2 # Really not sure why this list is not getting updated
任何帮助都将不胜感激。提前谢谢。
,如果这里有什么地方不清楚,请告诉我。我会更新他们的。
编辑:
我也尝试了以下方法,但是输出没有改变:
sorted_data_per_day = data_per_day.sort_values('Value',ascending=False)
for i in range(len(sorted_data_per_day)):回答 2
Stack Overflow用户
发布于 2019-11-11 23:48:03
您可以使用简单的groupby().apply(...)执行所有步骤a)、b)、c),至少在第一次执行时是这样的:
df.groupby('Day').apply(lambda x: x.sort_values('Value', ascending=False).head(1))
Tester1 Tester2 Day Value
Day
1 1 B A 1 0.48
2 11 C C 2 0.71我们只需选择所需的列,删除索引,然后以列表/set/任何您想要的形式返回;您可以修改以下代码:
df.groupby('Day').apply(lambda x: x.sort_values('Value', ascending=False).head(1)[['Tester1','Tester2']] )
Tester1 Tester2
Day
1 1 B A
2 11 C C(步骤d)是模棱两可的,但您澄清了它已简化为“删除/忽略此日组中包含步骤c中的Tester1或Tester2的所有其他条目”。
最简单的方法可能是保留测试人员的set,当天将其初始化给所有测试人员,当我们看到那些测试人员出现在最高值条目上时,删除测试人员(set.discard())。当我们没有条目或测试人员时,当天的处理就结束了。
另外,当您说“删除具有最高值的Tester对,并将其附加到列表中并保存以供将来使用”时,通常我们不需要从分组数据格式中删除和追加类似的内容,我们只需要下降排序的值列表,排除我们已经看到的测试人员,我们可以在一个额外的列中设置一些整数/布尔标志,以说明我们的算法所采用的行。(您只想存储测试人员,还是存储包括值在内的整行?)
例如,下面的代码从每个Day组的顶部记录中获取测试人员,作为列表:
>>> df.groupby('Day').apply(lambda grp: grp.sort_values('Value', ascending=False) [['Tester1','Tester2']].iloc[0].tolist() )
Day
1 [B, A]
2 [C, C]无论如何,您可以适应这种情况,您将需要编写一些迭代函数,该函数位于组上的apply()调用中,它返回一些输出数据(例如,带有一个额外的列Keep,等等)。
Stack Overflow用户
发布于 2019-11-12 00:16:46
把这个也留在这里,以防其他人在将来遇到类似的问题。将for循环更改为while循环会有所帮助。
#Incorrect code
for i in range(len(data_per_day)):
###########################
#Correct code
###########################
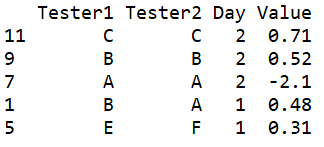
while len(sorted_data_per_day)>0:我现在得到的输出如下所示,这正是我所要寻找的。
https://stackoverflow.com/questions/58809994
复制相似问题
腾讯云开发者
