
数据仓库:基于RDBMs- vs S3/ADLS的数据仓库
我开始在电信领域开发数据仓库。我熟悉Kimball的方法(将我的DW建模为星型模式)。我预计许多事实表,最大的可能是数百亿行。我无法想象几年后数据仓库将再次运行的所有类型的查询。
现代db方法指出,计算能力应与存储(即Azure Synapse Analytics、Redshift谱、Presto等)分离。而格林梅利或红移等数据库则总是运行PostgreSQL服务器来存储数据。
与“解耦”相比,更喜欢基于RDBMs的数据仓库的原因是什么?
虽然我完全喜欢解耦方法,但我的混淆是基于这样一个事实:我完全不知道在S3/ADLS和RDBMs中分析数据对性能的影响:
- 如果您选择没有能力暂停集群(并使用无服务器方法)的Redshift/Greenplum,您将获得用于查找、聚合和联接的RDBMs系统的性能优化。
- 如果您选择基于S3/ADLS的MPP datawarehouse,那么您已经在云存储上运行了查询。这将使您能够非常快地扩展/暂停集群,甚至可以在云供应商允许的情况下使用无服务器方法。但是我找不到关于Redshift/ Analytics如何索引数据的好文档。他们使用地板和索引吗?它们是否使用自定义的列存储格式?他们是否在对非常有选择性的查询进行全面扫描时遇到了困难?
如果这类问题还没有成为一般的理论,而且是非常基于意见的,那么我是否应该根据PoCs来做所有的决定呢?我对这个选项感到困惑,因为DW PoC可能需要很长时间。也许你知道什么性能基准?
回答 1
Stack Overflow用户
发布于 2020-01-01 20:46:25
但我找不到好的文件。。。Azure Synapse分析他们如何索引数据。
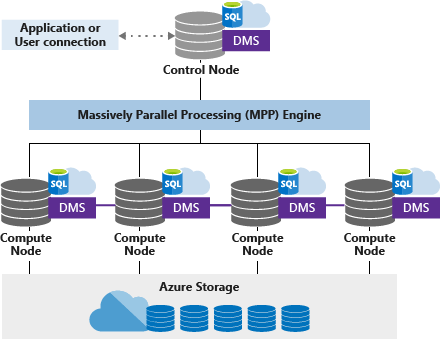
Azure Synapse Analytics支持对Azure database (ADLS)进行读写,ADLS称为“外部表”,并支持对存储在基于Flash的存储上的分布式数据库进行读写的常规表或“内部表”,该数据库是高度压缩和重缓存的。默认情况下,内部表是群集列存储,但也可以是堆或群集索引。如果需要,还可以使用分区索引和辅助索引。见创建表。
因此,ADLS构成了最低级别、最低成本、最慢的存储层,您可以构建存储在快速访问SQL Server内部存储中的表。
因此存储层次结构如下所示:
- 计算节点RAM
- 计算节点局部NVMe闪存
- 存储在远程分布式Flash存储上的数据库文件
- 存储在Azure上的拼花文件
这是来自体系结构概述文档的:
将我的数据仓库建模为星型模式
因此Synapse Analytics的一个常见模式是将原始数据存储在Parquet文件中,存储在ADLS中,并使用内部表构建已消费的星型模式,通常使用Hash或Round分布分发的事实表,以及作为复制表存储的维度。
https://stackoverflow.com/questions/59554044
复制相似问题
腾讯云开发者
