
计算python中的pearson相关
计算python中的pearson相关
提问于 2020-02-07 15:05:25
我有4栏“国家、年份、GDP、CO2排放”。
我想衡量每个国家的国内生产总值和CO2emissions之间的皮尔逊相关性。
国家栏包含世界上所有国家,国际年的数值为"1990、1991、.、2018年“。
回答 3
Stack Overflow用户
回答已采纳
发布于 2020-02-07 15:16:43
您应该使用与groupby一起分组的corr()作为您的聚合函数:
country = ['India','India','India','India','India','China','China','China','China','China']
Year = [2018,2017,2016,2015,2014,2018,2017,2016,2015,2014]
GDP = [100,98,94,64,66,200,189,165,134,130]
CO2 = [94,96,90,76,64,180,172,150,121,117]
df = pd.DataFrame({'country':country,'Year':Year,'GDP':GDP,'CO2':CO2})
print(df.groupby('country')[['GDP','CO2']].corr()如果我们稍微研究一下这个输出,我们就可以找到一些更有价值的东西:
df_corr = (df.groupby('country')['GDP','CO2'].corr()).drop(columns='GDP').drop('CO2',level=1).rename(columns={'CO2':'Correlation'})
df_corr = df_corr.reset_index().drop(columns='level_1').set_index('country',drop=True)
print(df_corr)输出:
Correlation
country
China 0.999581
India 0.932202Stack Overflow用户
发布于 2020-02-07 15:18:23
我猜你希望每个国家都有皮尔逊大厨。使用pearsonr,您可以循环遍历并为每个国家创建一个字典。
from scipy.stats.stats import pearsonr
df = pd.DataFrame({"column1":["value 1", "value 1","value 1","value 1","value 2", "value 2", "value 2", "value 2"],
"column2":[1,2,3,4,5, 1,2,3],
"column3":[10,30,50, 60, 80, 10, 90, 20],
"column4":[1, 3, 5, 6, 8, 5, 2, 3]})
results = {}
for country in df.column1.unique():
results[country] = {}
pearsonr_value = pearsonr(df.loc[df["column1"]== country, "column3"],df.loc[df["column1"] == country, "column4"])
results[country]["pearson"] = pearsonr_value[0]
results[country]["pvalue"] = pearsonr_value[0]
print(results["value 1"])
#{'pearson': 1.0, 'pvalue': 1.0}
print(results["value 2"])
#{'pearson': 0.09258200997725514, 'pvalue': 0.09258200997725514}Stack Overflow用户
发布于 2020-02-09 07:19:52
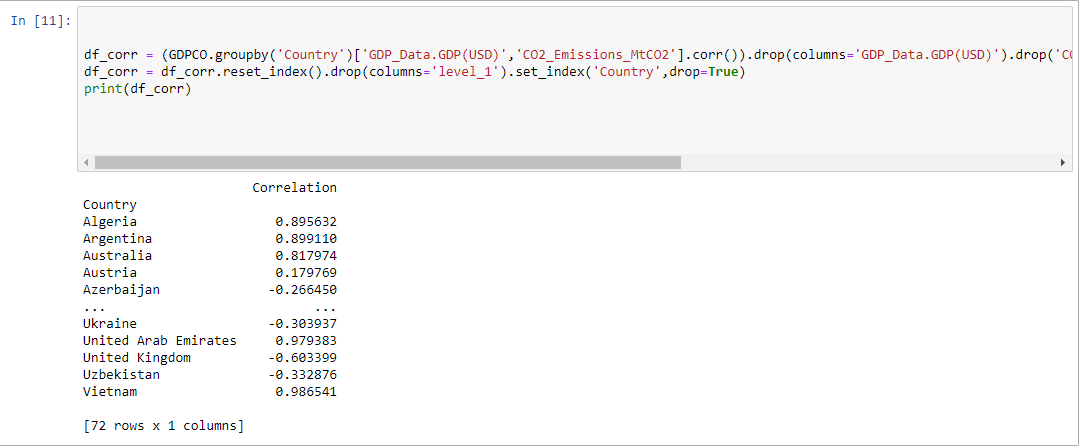
谢谢你@Celius,它成功了,给了我我想要的结果。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/60116042
复制相关文章
相似问题
腾讯云开发者
