
将PDF按章节从目录中拆分
将PDF按章节从目录中拆分
提问于 2020-04-16 04:39:00
我正在使用GemBox.Pdf,我需要提取一个PDF文件中的各个章节作为一个单独的PDF文件。
第一页(也可能是第二页)包含TOC (目录),我需要根据其划分PDF页面的其余部分:
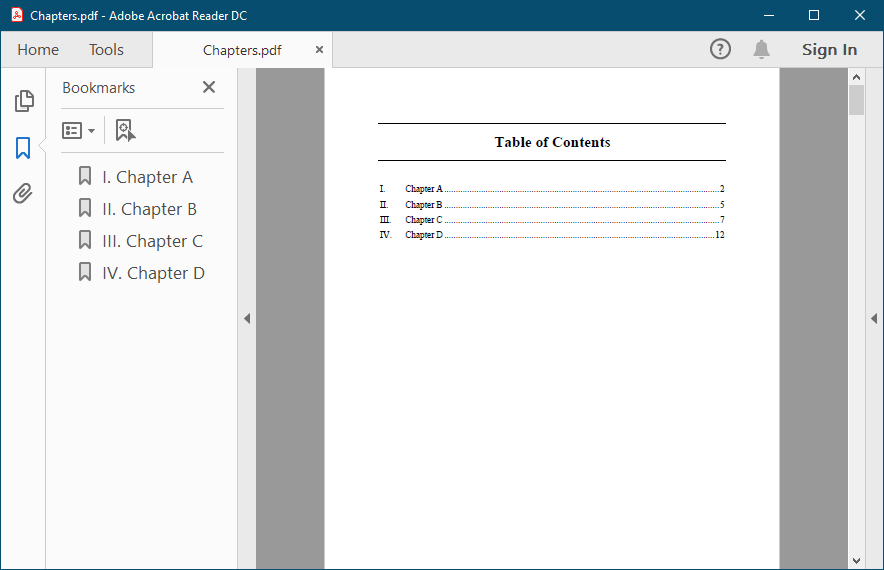
另外,那些拆分的PDF文档应该被命名为它们包含的章节。
我可以根据每个文档的页数来拆分PDF (我使用这个例子计算出了这一点):
using (var source = PdfDocument.Load("Chapters.pdf"))
{
int pagesPerSplit = 3;
int count = source.Pages.Count;
for (int index = 1; index < count; index += pagesPerSplit)
{
using (var destination = new PdfDocument())
{
for (int splitIndex = 0; splitIndex < pagesPerSplit; splitIndex++)
destination.Pages.AddClone(source.Pages[index + splitIndex]);
destination.Save("Chapter " + index + ".pdf");
}
}
}但我不知道如何阅读和处理TOC,并合并各章,根据其项目。
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-04-16 05:33:49
您应该迭代文档的书签(轮廓),并根据书签目标页将其拆分。
例如,尝试如下:
using (var source = PdfDocument.Load("Chapters.pdf"))
{
PdfOutlineCollection outlines = source.Outlines;
PdfPages pages = source.Pages;
Dictionary<PdfPage, int> pageIndexes = pages
.Select((page, index) => new { page, index })
.ToDictionary(item => item.page, item => item.index);
for (int index = 0, count = outlines.Count; index < count; ++index)
{
PdfOutline outline = outlines[index];
PdfOutline nextOutline = index + 1 < count ? outlines[index + 1] : null;
int pageStartIndex = pageIndexes[outline.Destination.Page];
int pageEndIndex = nextOutline != null ?
pageIndexes[nextOutline.Destination.Page] :
pages.Count;
using (var destination = new PdfDocument())
{
while (pageStartIndex < pageEndIndex)
{
destination.Pages.AddClone(pages[pageStartIndex]);
++pageStartIndex;
}
destination.Save($"{outline.Title}.pdf");
}
}
}注意,从截图中可以看出,您的章节书签中包含了序号(罗马数字)。如果需要,您可以很容易地用这样的方法删除这些内容:
destination.Save($"{outline.Title.Substring(outline.Title.IndexOf(' ') + 1)}.pdf");页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61242817
复制相关文章
相似问题
腾讯云开发者
