
为什么神经网络在自己的训练数据上预测错误?
提出了一种带监督学习的LSTM (RNN)神经网络用于数据库存预测。问题是为什么它对自己的培训数据预测错误?(注:可复制的示例如下)
我建立了一个简单的模型来预测未来5天的股价:
model = Sequential()
model.add(LSTM(32, activation='sigmoid', input_shape=(x_train.shape[1], x_train.shape[2])))
model.add(Dense(y_train.shape[1]))
model.compile(optimizer='adam', loss='mse')
es = EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True)
model.fit(x_train, y_train, batch_size=64, epochs=25, validation_data=(x_test, y_test), callbacks=[es])正确的结果在y_test (5个值)中,所以模型训练,回顾前90天,然后用patience=3恢复最佳(val_loss=0.0030)结果的权重。
Train on 396 samples, validate on 1 samples
Epoch 1/25
396/396 [==============================] - 1s 2ms/step - loss: 0.1322 - val_loss: 0.0299
Epoch 2/25
396/396 [==============================] - 0s 402us/step - loss: 0.0478 - val_loss: 0.0129
Epoch 3/25
396/396 [==============================] - 0s 397us/step - loss: 0.0385 - val_loss: 0.0178
Epoch 4/25
396/396 [==============================] - 0s 399us/step - loss: 0.0398 - val_loss: 0.0078
Epoch 5/25
396/396 [==============================] - 0s 391us/step - loss: 0.0343 - val_loss: 0.0030
Epoch 6/25
396/396 [==============================] - 0s 391us/step - loss: 0.0318 - val_loss: 0.0047
Epoch 7/25
396/396 [==============================] - 0s 389us/step - loss: 0.0308 - val_loss: 0.0043
Epoch 8/25
396/396 [==============================] - 0s 393us/step - loss: 0.0292 - val_loss: 0.0056预测结果很棒,不是吗?
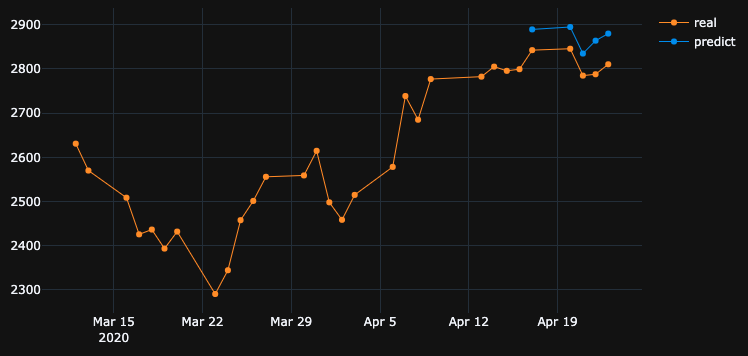
这是因为算法从#5时代恢复了最佳权重。好的,让我们现在将这个模型保存到.h5文件中,移回10天并预测最后5天(在最初的示例中,我们在4月17日至23日建立了模型并进行了验证,包括周末休假,现在让我们在4月2-8日进行测试)。结果:
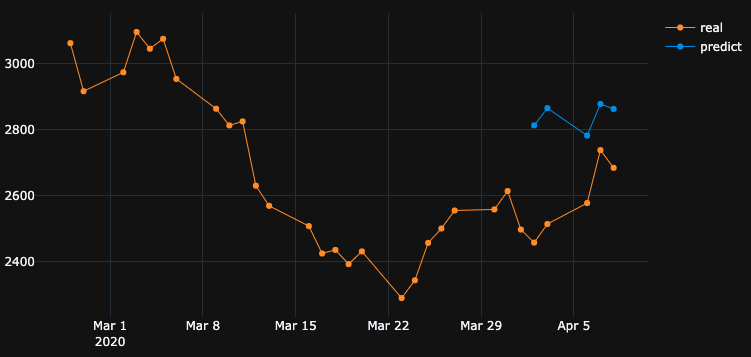
它显示出完全错误的方向。正如我们所看到的,这是因为模型是经过训练的,在4月17日至23日最适合于验证,而不是在2-8年。如果我尝试更多的训练,玩什么时代选择,无论我做什么,总是有很多时间间隔,在过去有错误的预测。
为什么模型在自己训练的数据上显示错误的结果?我训练数据,它必须记住如何预测数据集,但预测错误。我也尝试过:
- 使用带有50k+行的大数据集,20年的股票价格,增加了或多或少的特性
- 创建不同类型的模型,例如添加更多隐藏层、不同batch_sizes、不同层激活、退出、批规范化
- 创建自定义EarlyStopping回调,从许多验证数据集获取平均val_loss并选择最佳
也许我错过了什么?我还能改进什么?
这里是非常简单的reproducible示例。yfinance下载标准普尔500指数的股票数据。
"""python 3.7.7
tensorflow 2.1.0
keras 2.3.1"""
import numpy as np
import pandas as pd
from keras.callbacks import EarlyStopping, Callback
from keras.models import Model, Sequential, load_model
from keras.layers import Dense, Dropout, LSTM, BatchNormalization
from sklearn.preprocessing import MinMaxScaler
import plotly.graph_objects as go
import yfinance as yf
np.random.seed(4)
num_prediction = 5
look_back = 90
new_s_h5 = True # change it to False when you created model and want test on other past dates
df = yf.download(tickers="^GSPC", start='2018-05-06', end='2020-04-24', interval="1d")
data = df.filter(['Close', 'High', 'Low', 'Volume'])
# drop last N days to validate saved model on past
df.drop(df.tail(0).index, inplace=True)
print(df)
class EarlyStoppingCust(Callback):
def __init__(self, patience=0, verbose=0, validation_sets=None, restore_best_weights=False):
super(EarlyStoppingCust, self).__init__()
self.patience = patience
self.verbose = verbose
self.wait = 0
self.stopped_epoch = 0
self.restore_best_weights = restore_best_weights
self.best_weights = None
self.validation_sets = validation_sets
def on_train_begin(self, logs=None):
self.wait = 0
self.stopped_epoch = 0
self.best_avg_loss = (np.Inf, 0)
def on_epoch_end(self, epoch, logs=None):
loss_ = 0
for i, validation_set in enumerate(self.validation_sets):
predicted = self.model.predict(validation_set[0])
loss = self.model.evaluate(validation_set[0], validation_set[1], verbose = 0)
loss_ += loss
if self.verbose > 0:
print('val' + str(i + 1) + '_loss: %.5f' % loss)
avg_loss = loss_ / len(self.validation_sets)
print('avg_loss: %.5f' % avg_loss)
if self.best_avg_loss[0] > avg_loss:
self.best_avg_loss = (avg_loss, epoch + 1)
self.wait = 0
if self.restore_best_weights:
print('new best epoch = %d' % (epoch + 1))
self.best_weights = self.model.get_weights()
else:
self.wait += 1
if self.wait >= self.patience or self.params['epochs'] == epoch + 1:
self.stopped_epoch = epoch
self.model.stop_training = True
if self.restore_best_weights:
if self.verbose > 0:
print('Restoring model weights from the end of the best epoch')
self.model.set_weights(self.best_weights)
def on_train_end(self, logs=None):
print('best_avg_loss: %.5f (#%d)' % (self.best_avg_loss[0], self.best_avg_loss[1]))
def multivariate_data(dataset, target, start_index, end_index, history_size, target_size, step, single_step=False):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i, step)
data.append(dataset[indices])
if single_step:
labels.append(target[i+target_size])
else:
labels.append(target[i:i+target_size])
return np.array(data), np.array(labels)
def transform_predicted(pr):
pr = pr.reshape(pr.shape[1], -1)
z = np.zeros((pr.shape[0], x_train.shape[2] - 1), dtype=pr.dtype)
pr = np.append(pr, z, axis=1)
pr = scaler.inverse_transform(pr)
pr = pr[:, 0]
return pr
step = 1
# creating datasets with look back
scaler = MinMaxScaler()
df_normalized = scaler.fit_transform(df.values)
dataset = df_normalized[:-num_prediction]
x_train, y_train = multivariate_data(dataset, dataset[:, 0], 0,len(dataset) - num_prediction + 1, look_back, num_prediction, step)
indices = range(len(dataset)-look_back, len(dataset), step)
x_test = np.array(dataset[indices])
x_test = np.expand_dims(x_test, axis=0)
y_test = np.expand_dims(df_normalized[-num_prediction:, 0], axis=0)
# creating past datasets to validate with EarlyStoppingCust
number_validates = 50
step_past = 5
validation_sets = [(x_test, y_test)]
for i in range(1, number_validates * step_past + 1, step_past):
indices = range(len(dataset)-look_back-i, len(dataset)-i, step)
x_t = np.array(dataset[indices])
x_t = np.expand_dims(x_t, axis=0)
y_t = np.expand_dims(df_normalized[-num_prediction-i:len(df_normalized)-i, 0], axis=0)
validation_sets.append((x_t, y_t))
if new_s_h5:
model = Sequential()
model.add(LSTM(32, return_sequences=False, activation = 'sigmoid', input_shape=(x_train.shape[1], x_train.shape[2])))
# model.add(Dropout(0.2))
# model.add(BatchNormalization())
# model.add(LSTM(units = 16))
model.add(Dense(y_train.shape[1]))
model.compile(optimizer = 'adam', loss = 'mse')
# EarlyStoppingCust is custom callback to validate each validation_sets and get average
# it takes epoch with best "best_avg" value
# es = EarlyStoppingCust(patience = 3, restore_best_weights = True, validation_sets = validation_sets, verbose = 1)
# or there is keras extension with built-in EarlyStopping, but it validates only 1 set that you pass through fit()
es = EarlyStopping(monitor = 'val_loss', patience = 3, restore_best_weights = True)
model.fit(x_train, y_train, batch_size = 64, epochs = 25, shuffle = True, validation_data = (x_test, y_test), callbacks = [es])
model.save('s.h5')
else:
model = load_model('s.h5')
predicted = model.predict(x_test)
predicted = transform_predicted(predicted)
print('predicted', predicted)
print('real', df.iloc[-num_prediction:, 0].values)
print('val_loss: %.5f' % (model.evaluate(x_test, y_test, verbose=0)))
fig = go.Figure()
fig.add_trace(go.Scatter(
x = df.index[-60:],
y = df.iloc[-60:,0],
mode='lines+markers',
name='real',
line=dict(color='#ff9800', width=1)
))
fig.add_trace(go.Scatter(
x = df.index[-num_prediction:],
y = predicted,
mode='lines+markers',
name='predict',
line=dict(color='#2196f3', width=1)
))
fig.update_layout(template='plotly_dark', hovermode='x', spikedistance=-1, hoverlabel=dict(font_size=16))
fig.update_xaxes(showspikes=True)
fig.update_yaxes(showspikes=True)
fig.show()回答 8
Stack Overflow用户
发布于 2020-05-03 16:58:12
“行动纲领”假设了一个有趣的发现。让我把原来的问题简化如下。
如果模型是在特定的时间序列上训练的,那么为什么模型不能重建以前的时间序列数据呢?
嗯,答案就在训练过程本身。由于在这里使用EarlyStopping是为了避免过度拟合,所以最好的模型保存在epoch=5,如OP所提到的val_loss=0.0030。在这种情况下,训练损失等于0.0343,也就是说,训练的RMSE是0.185。由于数据集是使用MinMaxScalar进行缩放的,因此我们需要撤消RMSE的缩放以了解发生了什么。
时间序列的最小值和最大值为2290和3380。因此,将0.185作为训练的RMSE意味着,即使对于训练集,预测值也可能与地面真值相差大约0.185*(3380-2290),即平均~200单位。
这就解释了为什么在先前的时间步骤中预测训练数据本身有很大的差异。
我该怎么做才能完美地模拟训练数据?
这个问题是我自己问的。最简单的答案是,使训练损失接近0,即超出了模型。
经过一些训练后,我意识到一个只有1层32细胞的模型不足以重建训练数据。因此,我添加了另一个LSTM层,如下所示。
model = Sequential()
model.add(LSTM(32, return_sequences=True, activation = 'sigmoid', input_shape=(x_train.shape[1], x_train.shape[2])))
# model.add(Dropout(0.2))
# model.add(BatchNormalization())
model.add(LSTM(units = 64, return_sequences=False,))
model.add(Dense(y_train.shape[1]))
model.compile(optimizer = 'adam', loss = 'mse')该模型是在不考虑1000的情况下对EarlyStopping年代进行训练的。
model.fit(x_train, y_train, batch_size = 64, epochs = 1000, shuffle = True, validation_data = (x_test, y_test))在1000时代末期,我们有一个0.00047的训练损失,比你的情况下的训练损失要低得多。因此,我们期望该模型能更好地重建训练数据。以下是4月2-8日的预测图。
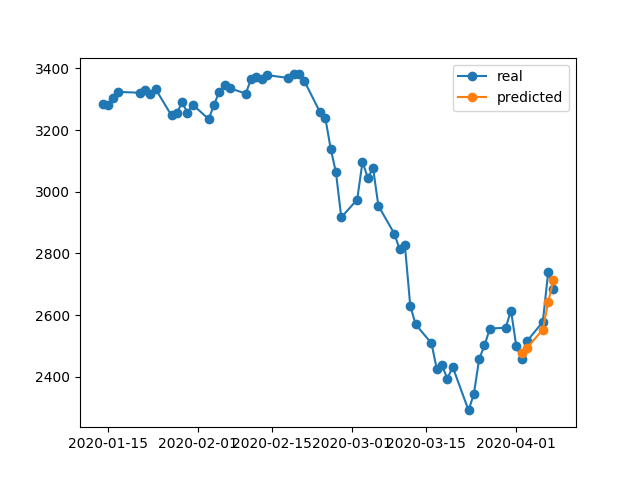
最后注:
对特定数据库的培训并不一定意味着模型应该能够完美地重构培训数据。特别是在引入早期停止、正则化和退出等方法以避免过度拟合时,该模型更易于泛化,而不是记忆训练数据。
Stack Overflow用户
发布于 2020-05-04 00:07:44
正如其他人已经说过的那样,你不应该对此期望太高。
不过,我在您的代码中发现了以下内容:
- 你是,在和测试期间,每次都要重新安装标尺。您需要保存sacler,并且只在测试期间转换数据,否则,结果将略有不同: 如果sklearn.externals : scaler = MinMaxScaler() df_normalized = scaler.fit_transform(df.values) joblib.dump( scaler,scaler_filename),否则:scaler= joblib.load( scaler_filename ) df_normalized = scaler.transform(df.values)
- 设置
shuffle=False。因为您确实需要保持数据集的顺序。 - 设置
batch_size=1。因为这样可以减少过度拟合的可能性,使学习更有噪音,误差也更少平均。 - 设置
epochs=50或更多。
在上述设置下,模型实现了loss: 0.0037 - val_loss: 3.7329e-04.
检查下列预测样本:
从17/04/2020 ->23/04/2020
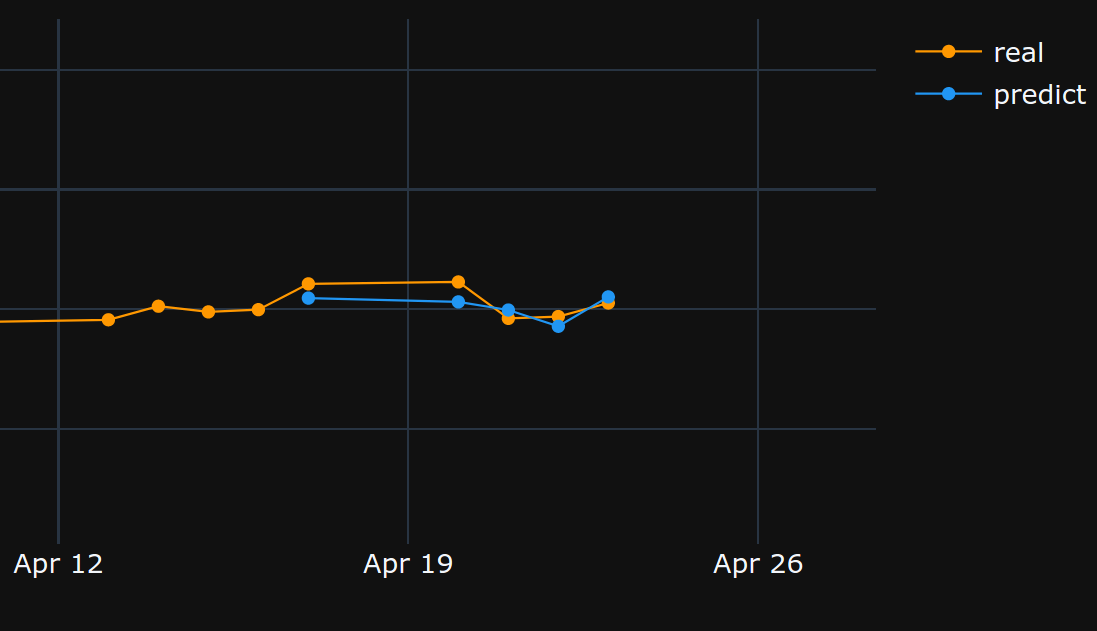
从02/04/2020 -> 08/04/2020:
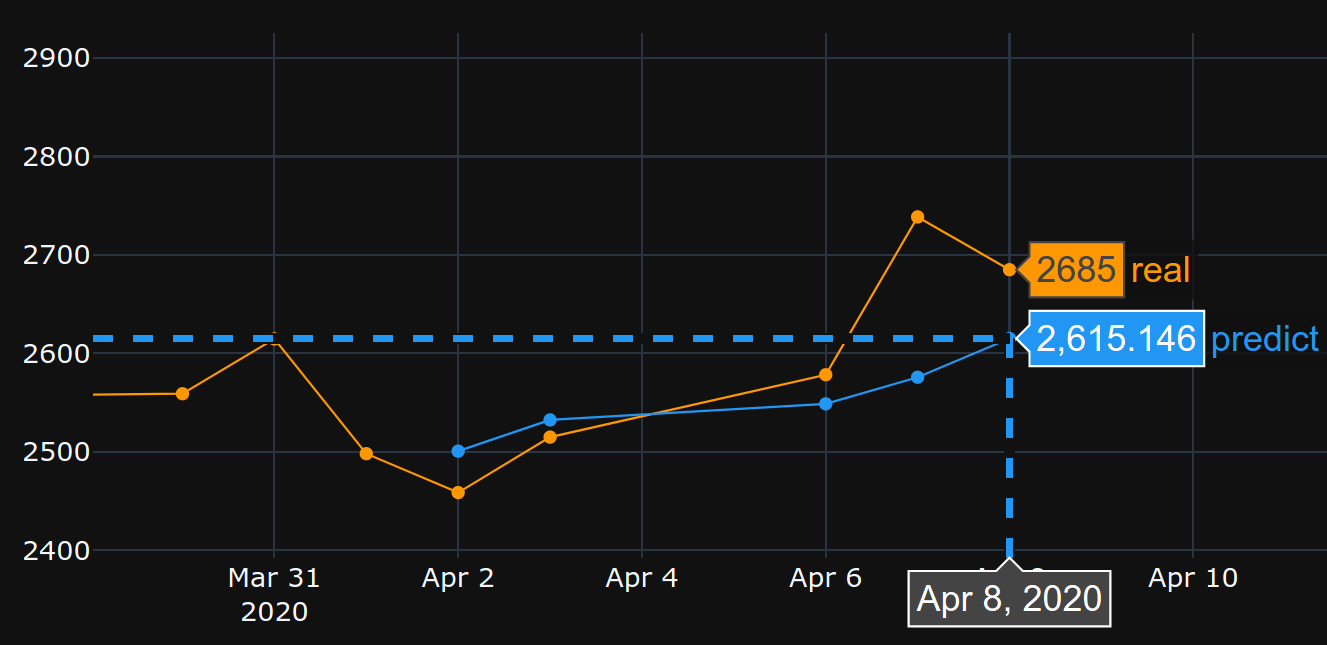
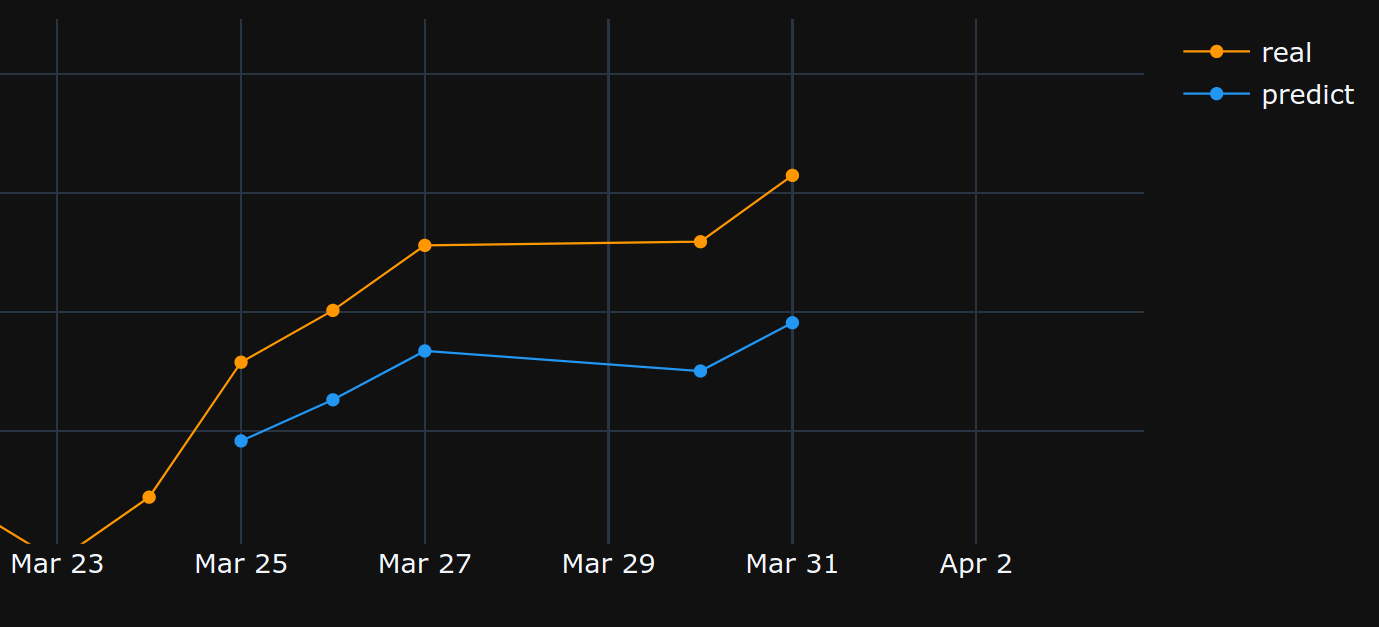
从25/03/2020 -> 31/03/2020:
Stack Overflow用户
发布于 2020-05-03 19:16:59
嫌疑犯#1 -正规化
神经网络对训练数据的拟合能力很强,在训练数据集上存在一个实验代替CIFAR10 (图像分类任务)标签(y值),网络拟合随机标签,造成几乎零损失。
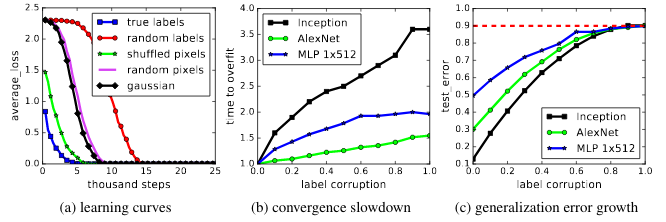
在左边,我们可以看到,给定足够多的历元,随机标签可以得到0左右的损失完美分数(来自理解深度学习需要张等人2016年重新思考概括。)。
那么为什么它没有一直发生呢?正则化。
正则化比我们为模型定义的优化问题(损失)更难解决。
几种常用的神经网络正则化方法:
- 早期停止
- 辍学
- 批归一化
- 重量衰减(例如l1 l2规范)
- 数据增强
- 加随机/高斯噪声
这些方法有助于减少过度拟合,通常会带来更好的验证和测试性能,但会导致更低的训练性能(实际上并不像最后一段所解释的那样重要)。
训练数据的性能通常不那么重要,为此我们使用验证集。
嫌疑犯#2 -型号尺寸
您使用的是32个单元的单一LSTM层。那太小了。尝试增加大小,甚至放置两个LSTM层(或双向层),我确信只要您允许它们,模型和优化器就会超过您的数据--即删除前面指定的早期停止、restore_last_weights和任何其他正则化。
关于问题复杂性的注记
仅仅通过回顾历史来预测未来的股票价格并不是一件容易的事情,即使模型能够(超过)与训练集完全吻合,它也很可能不会在测试集或现实世界中做任何有用的事情。
ML不是黑魔法,x样本需要以某种方式与y标记关联,我们通常假设(x,y)是从某种分布中提取的。
一种更直观的思考方式,当您需要手动标记狗/猫类的图像时--这是非常直接的。但是,你能通过仅仅查看股票的历史来手动“标记”股票价格吗?
这是关于这个问题有多难的一些直觉。
关于过拟合的注记
一个人不应该追求更高的训练性能,因为我们通常尝试用一个新的、属性类似于火车数据的未见数据模型来实现对训练数据的过度拟合,这几乎毫无用处。所有的想法都是试图概括和学习数据的属性和与目标的相关性,这就是学习的内容:)
https://stackoverflow.com/questions/61425296
复制相似问题
腾讯云开发者
