
cor.test.default(x = mat[,i],y= mat[,j],.)中的误差:有限观测量不够
我一直在谷歌和StackOverflow上寻找解决我的问题的方法。我现在试了几样东西,似乎什么也没有用。
我试图创建一个语言特征的关联框图。对于每一项功能(总共36项),Excel中的1用于扬声器使用时,0用于发言者不使用。
有41人发言,他们没有使用所有36个特征,虽然最低得分是8分。我想分析我的数据,看看哪些特征相关,从而找出哪些特征预测其他特征的使用。
我在R中使用了corrplot,下面是我一直使用的命令:
cor_mat <- df_analysis %>%
replace(., is.na(.), 0) %>%
cor(method = "spearman")
cor_residuals <- cor.mtest(cor_mat, conf.level = .95)但是,我说错了:
Error in cor.test.default(x = mat[, i], y = mat[, j], ...) : not enough finite observations
有谁知道我怎么纠正的吗?事实上,我真正需要知道的是什么是问题所在,我可能会自己解决。不过,如果你也有解决办法,我会非常感激的!
非常感谢!
回答 2
Stack Overflow用户
发布于 2020-08-15 18:26:38
您的数据集中有几列没有变化;因此,这些变量的相关性都是NA,这会使下游的事情变得一团糟。
which(apply(df_analysis,2,sd)==0)
## [1] a' c[h]lach bheag [3] a' c[h]loich bhig [14] a' b[h]ord bheag
## 1 3 14
## [26] nan su[ ]l [27] nan sul[ ]
## 26 27 我通过设置options(error=recover)并运行查看错误发生的位置(当发生错误时,此设置会将您拖入browser/debug模式)来解决这个问题。更直接地说,我应该做corrplot(cor_mat),这有助于为NA值添加问号.
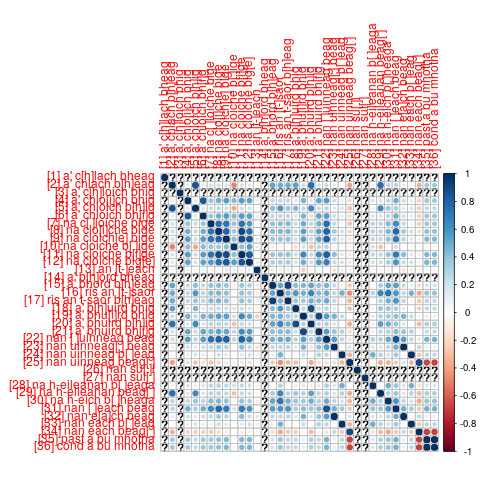
image()或heatmap(as.matrix(df_analysis),Rowv=NA,Colv=NA, scale="none", margins=c(10,8))将有助于查看原始数据。
Stack Overflow用户
发布于 2020-08-15 15:26:23
在理想情况下,可以像这样定义corrplot:
df_cor <- cor(df_analysis)
corrplot(df_cor, type = "full", order = "hclust",
outline.color = "white", hc.method = "ward",
pch.cex = .5, show.diag = TRUE,
p.mat = cor_residuals$p, insig = "blank", sig.level = .01,
addrect = 20, tl.srt = 36, tl.cex = .8, tl.col = "black",
col = rev(lacroix_palette("PassionFruit", 8, "continuous")))https://stackoverflow.com/questions/63427623
复制相似问题
腾讯云开发者
