
音频信号在字级边界的分割
我正在使用webrtcvad和pydub处理音频文件。任何片段的分裂都是由句子的沉默造成的。在字级边界条件下,有什么方法可以实现这种分裂吗?(每句话之后)?如果librosa/ffmpeg/pydub有这样的特性,在每个声音中都能分裂吗?但是在分割之后,我需要声音的开始和结束时间,这正是声乐部分在原始文件中所定位的。一种简单的解决方案或由ffmpeg划分的方法也是由以下方法定义的:
https://gist.github.com/vadimkantorov/00bf4fbe4323360722e3d2220cc2915e
但这也是分裂的沉默,和每个填充数或帧大小,分裂是不同的。我正试着用声乐来分裂。例如,我手动完成了原始文件、拆分单词及其在json中的时间位置在链接下面提供的文件夹中:
回答 2
Stack Overflow用户
发布于 2020-12-19 13:43:58
简单的音频分割问题可以用隐马尔可夫模型进行处理,并将音频预处理成合适的特征。言语的典型特征是声音水平、声音活动/声音。要获得字级切分(相对于句子),这需要有相当高的时间分辨率.不幸的是,pyWebRTCVAD没有可调的时间平滑,所以它可能不适合这个任务。
在您的音频示例中,有一位电台主持人用德语讲得相当快。看看声音级别,wrt到单词的边界,你已经标记了,很明显,在一些单词之间,声音水平并没有真正下降。这就排除了一个简单的声级分割模型。
总之,对于一般的语音信号来说,要取得好的效果是相当困难的。但幸运的是,这是非常好的研究,并有现成的解决方案可用。它们通常使用一个声学模型(单词和音素的声音),以及一个语言模型(可能是单词的顺序),通过许多小时的音频学习。
基于语音识别库的分词方法
所有这些功能都包含在语音识别框架中,许多功能都允许获得具有定时的字级输出。下面是一些使用沃斯克的工作代码。
Vosk的替代方案将是PocketSphinx。或者使用Google、Amazon服务、Azure等在线语音识别服务。
import sys
import os
import subprocess
import json
import math
# tested with VOSK 0.3.15
import vosk
import librosa
import numpy
import pandas
def extract_words(res):
jres = json.loads(res)
if not 'result' in jres:
return []
words = jres['result']
return words
def transcribe_words(recognizer, bytes):
results = []
chunk_size = 4000
for chunk_no in range(math.ceil(len(bytes)/chunk_size)):
start = chunk_no*chunk_size
end = min(len(bytes), (chunk_no+1)*chunk_size)
data = bytes[start:end]
if recognizer.AcceptWaveform(data):
words = extract_words(recognizer.Result())
results += words
results += extract_words(recognizer.FinalResult())
return results
def main():
vosk.SetLogLevel(-1)
audio_path = sys.argv[1]
out_path = sys.argv[2]
model_path = 'vosk-model-small-de-0.15'
sample_rate = 16000
audio, sr = librosa.load(audio_path, sr=16000)
# convert to 16bit signed PCM, as expected by VOSK
int16 = numpy.int16(audio * 32768).tobytes()
# XXX: Model must be downloaded from https://alphacephei.com/vosk/models
# https://alphacephei.com/vosk/models/vosk-model-small-de-0.15.zip
if not os.path.exists(model_path):
raise ValueError(f"Could not find VOSK model at {model_path}")
model = vosk.Model(model_path)
recognizer = vosk.KaldiRecognizer(model, sample_rate)
res = transcribe_words(recognizer, int16)
df = pandas.DataFrame.from_records(res)
df = df.sort_values('start')
df.to_csv(out_path, index=False)
print('Word segments saved to', out_path)
if __name__ == '__main__':
main()使用.WAV文件和输出文件的路径运行程序。
python vosk_words.py attached_problem/main.wav out.csv脚本在CSV中输出单词及其时间。然后,可以使用这些时间来分割音频文件。下面是输出示例:
conf,end,start,word
0.618949,1.11,0.84,also
1.0,1.32,1.116314,eine
1.0,1.59,1.32,woche
0.411941,1.77,1.59,des将输出(底部)与您提供的示例文件(顶部)进行比较,它看起来相当不错。
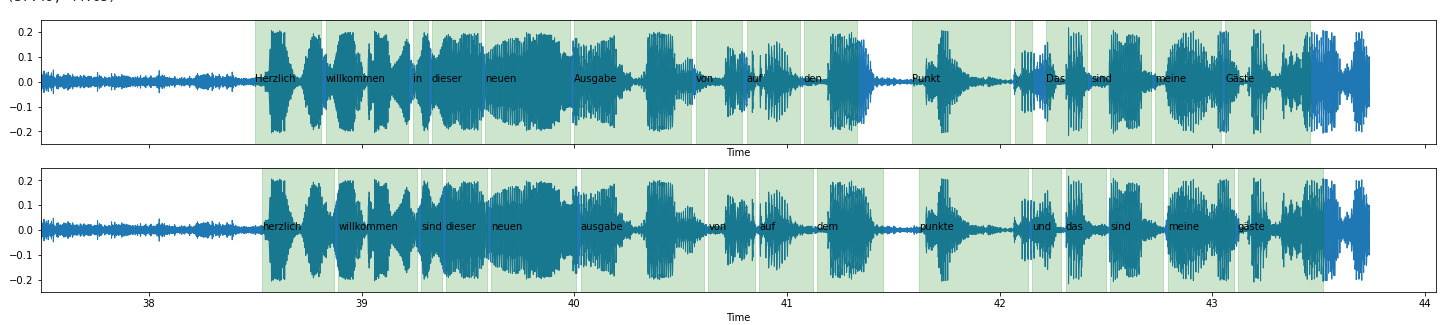
实际上,它在42.25秒时找到了一个注释中没有包含的单词"und“。
Stack Overflow用户
发布于 2020-10-20 10:17:25
划词是在音频域之外的,需要一种智能。手工操作很容易,因为我们很聪明,并且知道我们在寻找什么,但是自动化这个过程是很困难的,因为正如您已经注意到的,沉默并不是(不仅仅是,并不总是)一个单词分隔符。
在音频级别,我们只能接近一个解决方案,这需要分析信号的幅度和添加一些时间机制。作为一个例子,Protools提供了一个很好的工具,名为 automatically ,它根据信号的幅度自动削减音频区域。它总是将材料保持在它在时间线中的原始位置,自然每个区域都知道它的持续时间。除了dB中的阈值之外,为了防止产生过多的区域,它在时域中提供了几个有用的参数:所创建区域的最小长度,切割前的延迟(从幅度通过阈值以下的点计算延迟),在重新打开门之前反向延迟(从幅度超过阈值的点向后计算延迟)。
这对你来说可能是个好的起点。实现这样的系统可能不会100 %成功,但如果设置能够很好地调整到扬声器,您可以获得相当好的比率。即使它不是完美的,它也会大大减少对手工工作的需求。
https://stackoverflow.com/questions/64153590
复制相似问题
腾讯云开发者
