
如何对numpy ndarray的timeseries数据执行重叠窗口
我有一个时间序列数据集作为一个粗大的形状数组:
(batch_size , observations , sensor_number
例如:
(3,10,2) 3批两个传感器,每个传感器具有长度为10的时间序列数据。
在这个numpy数组上,我现在想重塑时间序列的length,并指定一个overlapping因子。
,这里有一个例子,试图从上面的中更改原始数据集:每个样本的新周期长度应该是5,我希望样本重叠0.4 (40%)。为了简单起见,时间序列数据来自1.10原始形状数据集(3,10,2),如下所示:
array([[[ 1, 2],[ 3, 4],[ 5, 6],[ 7, 8],[ 9, 10],
[ 1, 2],[ 3, 4],[ 5, 6],[ 7, 8],[ 9, 10]],
[[ 1, 2],[ 3, 4],[ 5, 6],[ 7, 8],[ 9, 10],
[ 1, 2],[ 3, 4],[ 5, 6],[ 7, 8],[ 9, 10]],
[[ 1, 2],[ 3, 4],[ 5, 6],[ 7, 8],[ 9, 10],
[ 1, 2],[ 3, 4],[ 5, 6],[ 7, 8],[ 9, 10]]])我希望新的、经过整形的numpy数组具有以下形状:(6,5,2)。每个中心都会被加窗,如下所示:
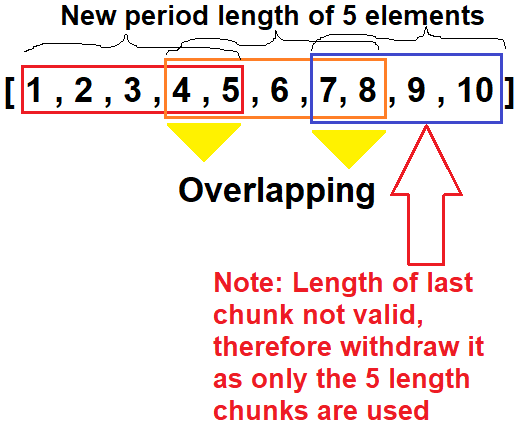
Overlapping:对于新的目标长度为5,a 40%的重叠意味着来自前一个样本的2个元素被重叠到下一个样本中。
因此,仅用有效长度的时间序列元素进行整形,意味着在上述情况下,通过切片原始时间序列2将原始数据量增加一倍,一个较短的时间序列与样本之间的重叠。
我尝试通过在for循环中遍历所有的元素来重塑它,但是这需要很长的时间,所以我认为必须有一种更好的方法,例如向量化操作。
有谁能帮上忙,并给出如何做的提示吗?谢谢你的建议。
回答 3
Stack Overflow用户
发布于 2020-11-01 15:20:25
让我们来看6个观察,每3个批次和2个传感器。
data = np.arange(3*6).reshape((3,6))[:,:, None] * ((1,1))
size = 3
step = 2
print("data:\n", data)输出:
data:
[[[ 0 0]
[ 1 1]
[ 2 2]
[ 3 3]
[ 4 4]
[ 5 5]]
[[ 6 6]
[ 7 7]
[ 8 8]
[ 9 9]
[10 10]
[11 11]]
[[12 12]
[13 13]
[14 14]
[15 15]
[16 16]
[17 17]]]我想这是一种优雅的方式。它使用列表理解,这通常比正常的for循环更快,特别是在这里,因为我不遍历数据,而是遍历每个窗口的第一个索引。
# Range until the last index where it is possible to start a window
last_start = data.shape[1] - size + 1
period_starts = range(0, last_start, step)
reshaped_data = np.concatenate(
[data[:,k:k+size] for k in period_starts],
axis=1).reshape(-1, size, data.shape[2])
print('Reshaped data:\n', reshaped_data)输出:
Reshaped data:
[[[ 0 0]
[ 1 1]
[ 2 2]]
[[ 2 2]
[ 3 3]
[ 4 4]]
[[ 6 6]
[ 7 7]
[ 8 8]]
[[ 8 8]
[ 9 9]
[10 10]]
[[12 12]
[13 13]
[14 14]]
[[14 14]
[15 15]
[16 16]]]如果我们不计算列表理解期间的间隔,可能会更快,尽管此时您可能不需要进一步增强:
period_intervals = np.array((period_starts, period_starts + size)).T
reshaped_data = np.concatenate(
[data[:,i:j] for i,j in period_intervals],
axis=1).reshape(-1, size, data.shape[2])或者,您可以使用索引,但在本例中,执行相同操作的代码要复杂得多(参见 on stackoverflow):
last_start = data.shape[1] - size + 1
period_starts = np.arange(0, last_start, step)
period_intervals = np.array((period_starts, period_starts + size)).T
# Create indexes for one observation axis.
# You could use map if you truly want to avoid for loops.
period_indexes = np.array([np.arange(i, j) for i, j in period_intervals])
# repeat as much as needed
observation_indexes = np.tile(period_indexes, (data.shape[0],1))
print("\nIndexes of observations:\n", observation_indexes)
# Create batch indexes
batches = (np.arange(data.shape[0])[:, None]
* np.ones(period_indexes.shape[-1], dtype=np.int8))
batch_indexes = np.repeat(batches, len(period_starts), axis=0)
print("\nIndexes for batch:\n", batch_indexes)
indexes = (batch_indexes, observation_indexes)
reshaped_data = data[indexes]
print("\nReshaped data:\n", reshaped_data)输出:
Indexes of observations:
[[0 1 2]
[2 3 4]
[0 1 2]
[2 3 4]
[0 1 2]
[2 3 4]]
Indexes for batch:
[[0 0 0]
[0 0 0]
[1 1 1]
[1 1 1]
[2 2 2]
[2 2 2]]
Reshaped data:
[[[ 0 0]
[ 1 1]
[ 2 2]]
[[ 2 2]
[ 3 3]
[ 4 4]]
[[ 6 6]
[ 7 7]
[ 8 8]]
[[ 8 8]
[ 9 9]
[10 10]]
[[12 12]
[13 13]
[14 14]]
[[14 14]
[15 15]
[16 16]]]很抱歉,这只是我第一次尝试,然后我才意识到我可以用我以前的(错误)方式,以一种非常简单和优雅的方式。
Stack Overflow用户
发布于 2020-11-01 16:30:09
size = 5
step = 3
new_dataset = False
for batch in np.arange(0,data_array.shape[0],1):
sample_data = data_array[batch].T
sensor_buffer = False
for sensor in np.arange(0,sample_data.shape[0],1):
time_series = sample_data[sensor]
splitted_timeseries = [time_series[i : i + size] for i in range(0,len(time_series), step)]
valid_splitts = np.asarray([splitted_ts for splitted_ts in splitted_timeseries if len(splitted_ts)==size])
valid_splitts = valid_splitts.reshape(valid_splitts.shape[0],
size,
1)
if type(sensor_buffer) == bool:
sensor_buffer = valid_splitts.copy()
else:
sensor_buffer = np.concatenate((sensor_buffer,valid_splitts.copy()),axis=-1)
if type(new_dataset) == bool:
new_dataset = sensor_buffer.copy()
print(new_dataset.shape)
else:
new_dataset = np.concatenate((new_dataset,sensor_buffer),axis=0)
new_dataset.shape这是我目前的版本,给出了正确的结果。size指定新时间序列的长度,并逐步执行步骤(定义重叠的另一种方法)。
对于这样的dataset数组:
array([[[ 1., 1.],
[ 2., 2.],
[ 3., 3.],
[ 4., 4.],
[ 5., 5.],
[ 6., 6.],
[ 7., 7.],
[ 8., 8.],
[ 9., 9.],
[10., 10.]],
[[ 1., 1.],
[ 2., 2.],
[ 3., 3.],
[ 4., 4.],
[ 5., 5.],
[ 6., 6.],
[ 7., 7.],
[ 8., 8.],
[ 9., 9.],
[10., 10.]],
[[ 1., 1.],
[ 2., 2.],
[ 3., 3.],
[ 4., 4.],
[ 5., 5.],
[ 6., 6.],
[ 7., 7.],
[ 8., 8.],
[ 9., 9.],
[10., 10.]]])它给了我正确的形状(6,5,2)和有效的时间序列块:
array([[[1., 1.],
[2., 2.],
[3., 3.],
[4., 4.],
[5., 5.]],
[[4., 4.],
[5., 5.],
[6., 6.],
[7., 7.],
[8., 8.]],
[[1., 1.],
[2., 2.],
[3., 3.],
[4., 4.],
[5., 5.]],
[[4., 4.],
[5., 5.],
[6., 6.],
[7., 7.],
[8., 8.]],
[[1., 1.],
[2., 2.],
[3., 3.],
[4., 4.],
[5., 5.]],
[[4., 4.],
[5., 5.],
[6., 6.],
[7., 7.],
[8., 8.]]])Stack Overflow用户
发布于 2020-11-02 05:35:40
这3行代码应该可以做到:
obs_starts = list(range(0,
1+old_obs_len - new_obs_len,
int(round((1-overlap)*new_obs_len))))
obs_indices = [list(range(x, x+new_obs_len)) for x in obs_starts]
new_A = A[:, obs_indices, :].reshape(-1, new_obs_len, num_sens)这里:
A是您的数组,具有(num_batches, old_obs_len, num_sens)形状
new_A是新的数组,具有(-1, new_obs_len, num_sens)形状。
overlap是重叠比。
请注意,没有重复的连接或拼接数组。所以在引擎盖下面有最少的数组数据复制。前两行用于构造嵌套的索引列表。第三行使用这个索引‘数组’来索引A,并形成结果。
设置演示数据:
import numpy as np
num_batches = 3 # Initial value
old_obs_len = 20 # Initial value
num_sens = 2
# Demo data
A = np.arange(num_batches*old_obs_len*num_sens).reshape(num_batches,
old_obs_len,
num_sens)
print (A.shape)
print (A)数据设置的输出:
(3, 20, 2)
[[[ 0 1]
[ 2 3]
[ 4 5]
[ 6 7]
[ 8 9]
[ 10 11]
[ 12 13]
[ 14 15]
[ 16 17]
[ 18 19]
[ 20 21]
[ 22 23]
[ 24 25]
[ 26 27]
[ 28 29]
[ 30 31]
[ 32 33]
[ 34 35]
[ 36 37]
[ 38 39]]
[[ 40 41]
[ 42 43]
[ 44 45]
[ 46 47]
[ 48 49]
[ 50 51]
[ 52 53]
[ 54 55]
[ 56 57]
[ 58 59]
[ 60 61]
[ 62 63]
[ 64 65]
[ 66 67]
[ 68 69]
[ 70 71]
[ 72 73]
[ 74 75]
[ 76 77]
[ 78 79]]
[[ 80 81]
[ 82 83]
[ 84 85]
[ 86 87]
[ 88 89]
[ 90 91]
[ 92 93]
[ 94 95]
[ 96 97]
[ 98 99]
[100 101]
[102 103]
[104 105]
[106 107]
[108 109]
[110 111]
[112 113]
[114 115]
[116 117]
[118 119]]]测试用例1:
overlap = 0.5
new_obs_len = 10测试用例1 (**print (new_A)**):的输出
[[[ 0 1]
[ 2 3]
[ 4 5]
[ 6 7]
[ 8 9]
[ 10 11]
[ 12 13]
[ 14 15]
[ 16 17]
[ 18 19]]
[[ 10 11]
[ 12 13]
[ 14 15]
[ 16 17]
[ 18 19]
[ 20 21]
[ 22 23]
[ 24 25]
[ 26 27]
[ 28 29]]
[[ 20 21]
[ 22 23]
[ 24 25]
[ 26 27]
[ 28 29]
[ 30 31]
[ 32 33]
[ 34 35]
[ 36 37]
[ 38 39]]
[[ 40 41]
[ 42 43]
[ 44 45]
[ 46 47]
[ 48 49]
[ 50 51]
[ 52 53]
[ 54 55]
[ 56 57]
[ 58 59]]
[[ 50 51]
[ 52 53]
[ 54 55]
[ 56 57]
[ 58 59]
[ 60 61]
[ 62 63]
[ 64 65]
[ 66 67]
[ 68 69]]
[[ 60 61]
[ 62 63]
[ 64 65]
[ 66 67]
[ 68 69]
[ 70 71]
[ 72 73]
[ 74 75]
[ 76 77]
[ 78 79]]
[[ 80 81]
[ 82 83]
[ 84 85]
[ 86 87]
[ 88 89]
[ 90 91]
[ 92 93]
[ 94 95]
[ 96 97]
[ 98 99]]
[[ 90 91]
[ 92 93]
[ 94 95]
[ 96 97]
[ 98 99]
[100 101]
[102 103]
[104 105]
[106 107]
[108 109]]
[[100 101]
[102 103]
[104 105]
[106 107]
[108 109]
[110 111]
[112 113]
[114 115]
[116 117]
[118 119]]]测试用例2:
overlap = 0.2
new_obs_len = 10测试用例2的(**print (new_A)**):输出:
[[[ 0 1]
[ 2 3]
[ 4 5]
[ 6 7]
[ 8 9]
[ 10 11]
[ 12 13]
[ 14 15]
[ 16 17]
[ 18 19]]
[[ 16 17]
[ 18 19]
[ 20 21]
[ 22 23]
[ 24 25]
[ 26 27]
[ 28 29]
[ 30 31]
[ 32 33]
[ 34 35]]
[[ 40 41]
[ 42 43]
[ 44 45]
[ 46 47]
[ 48 49]
[ 50 51]
[ 52 53]
[ 54 55]
[ 56 57]
[ 58 59]]
[[ 56 57]
[ 58 59]
[ 60 61]
[ 62 63]
[ 64 65]
[ 66 67]
[ 68 69]
[ 70 71]
[ 72 73]
[ 74 75]]
[[ 80 81]
[ 82 83]
[ 84 85]
[ 86 87]
[ 88 89]
[ 90 91]
[ 92 93]
[ 94 95]
[ 96 97]
[ 98 99]]
[[ 96 97]
[ 98 99]
[100 101]
[102 103]
[104 105]
[106 107]
[108 109]
[110 111]
[112 113]
[114 115]]]测试用例3:
overlap = 0.8
new_obs_len = 10测试用例1 (**print (new_A[16:18,:,:])**):的输出
[[[ 96 97]
[ 98 99]
[100 101]
[102 103]
[104 105]
[106 107]
[108 109]
[110 111]
[112 113]
[114 115]]
[[100 101]
[102 103]
[104 105]
[106 107]
[108 109]
[110 111]
[112 113]
[114 115]
[116 117]
[118 119]]]https://stackoverflow.com/questions/64625690
复制相似问题
腾讯云开发者
