
在R中绘制散点图
在R中绘制散点图
提问于 2020-11-11 14:37:13
由于这个问题,我有一个数据结构,这里说。
代码:
df <- tibble::tribble(~person, ~age, ~height,
"John", 1, 20,
"Mike", 3, 50,
"Maria", 3, 52,
"Elena", 6, 90,
"Biden", 9, 120)
df %>%
mutate(
age_c = cut(
age,
breaks = c(-Inf, 5, 10),
labels = c("0-5", "5-10"),
right = TRUE
),
height_c = cut(
height,
breaks = c(-Inf, 50, 100, 200),
labels = c("0-50", "50-100", "100-200"),
right = TRUE
)
) %>%
count(age_c, height_c, .drop = FALSE)
# A tibble: 6 x 3
age_c height_c n
<fct> <fct> <int>
1 0-5 0-50 2
2 0-5 50-100 1
3 0-5 100-200 0
4 5-10 0-50 0
5 5-10 50-100 1
6 5-10 100-200 1现在我正在尝试创建一个散点图,但是我遇到了一个问题,似乎代码没有注意到X和Y轴上的值是重复的。相反,它是在重复它们。所以,我希望我的x轴有两个值0-5和5-10 (我得到的是0-5,0-5,0-5,5-10,5-10,5-10,5-10,5-10),y-轴三值0-50,50-100和100-200 (相反,我有两个系列)。
我用来绘制的代码:
ggplot(df, aes(x=age_c, y=height_c))预期地块(其中圆圈的大小将以N的值为基础):
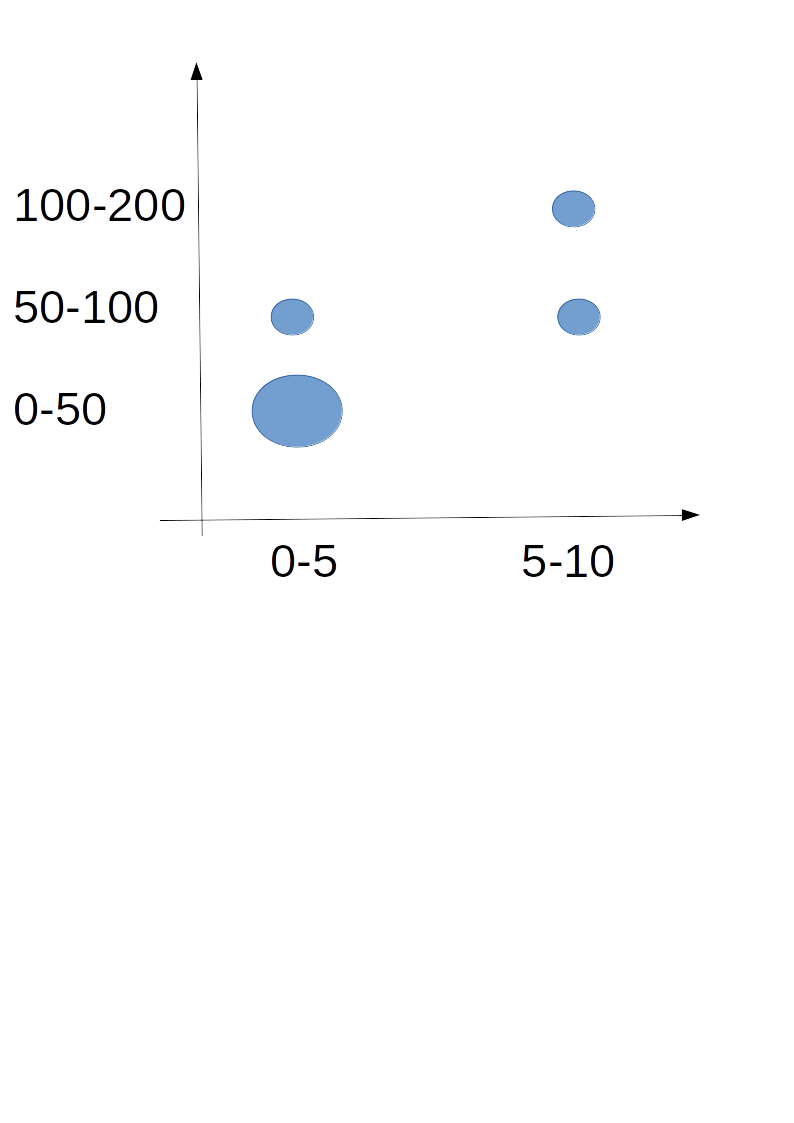
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-11-11 15:20:53
如果您绘制了count data.frame,它应该可以工作:
countdf = df %>%
mutate(
age_c = cut(
age,
breaks = c(-Inf, 5, 10),
labels = c("0-5", "5-10"),
right = TRUE
),
height_c = cut(
height,
breaks = c(-Inf, 50, 100, 200),
labels = c("0-50", "50-100", "100-200"),
right = TRUE
)
) %>%
count(age_c, height_c, .drop = FALSE)
countdf %>%
filter(n>0) %>%
ggplot(aes(x=age_c,y=height_c,size=n)) +
geom_point() +
scale_size_continuous(range=c(5,10),breaks=c(1,2))
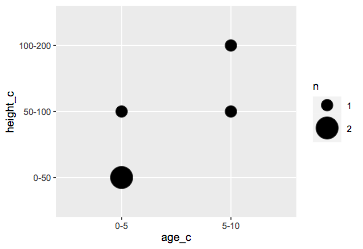
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64788506
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号