
如何将Spyder中的编码更改为UTF - 8?
我想把Spyder中的编码改为UTF - 8。
有人能解释一下我是怎么做到这一点的吗?谢谢你帮我!
编辑
def deleteDoubleValues (derivativeAngle):
position = []
cleanValues = [] #leeres Array erstellen
cleanValues.append(derivativeAngle[0])
for i in range (len(derivativeAngle)-1):
if format(derivativeAngle[i],'.4f') != format(derivativeAngle[i+1],'.4f'):
#i=i+1
position.append(i)
cleanValues.append(derivativeAngle[i+1])
if format(derivativeAngle[i],'.4f') != format(derivativeAngle[i+1],'.4f'):
position.append(i+1)
return cleanValues, position
def deletePositionAccel(position,strideData):
xAcceleration = strideData["accel x"].to_numpy()
yAcceleration = strideData["accel y"].to_numpy()
xValues = []
yValues = []
for i in range(len(position)):
xValues.append(xAcceleration(position[i]))
yValues.append(yAcceleration(position[i]))
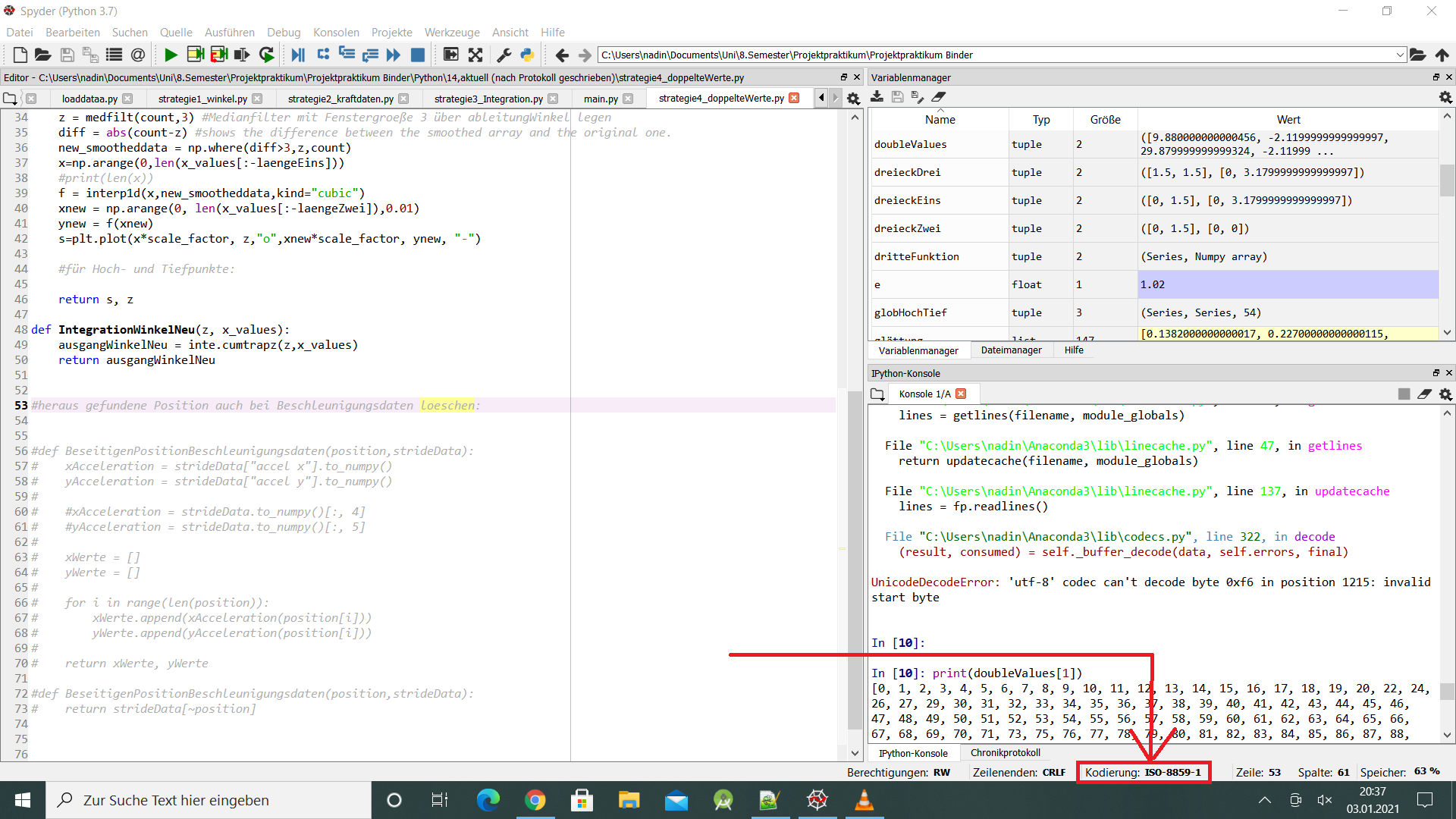
return xValues, yValues当我随后主要运行def deletePositionAccel()时,总是会出现以下错误:
UnicodeDecodeError:'utf-8‘编解码器无法解码位置1382的字节0 0xdf :无效的连续字节
我不知道为什么,因为我工作的CSV文件是在UTF - 8中。
derivativeAngle=[ 9.88 -2.12 29.88 -2.12 9.88 16.88 9.88 4.88 9.88
-2.12 9.88 16.88 10.88 9.88 10.88 9.88 4.88 3.88
-2.12 9.88 3.88 10.88 10.88 9.88 9.88 10.88 10.88
15.88 16.88 16.88 22.88 34.88 41.88 53.88 60.88 -2.12
72.88 84.88 97.88 110.88 128.88 141.88 159.88 172.88 191.88
203.88 222.88 241.88 266.88 272.88 297.88 303.88 322.88 303.88
279.88 240.88 166.88 97.88 22.88 -46.12 -64.12 -90.12 -139.12
-134.12 -164.12 -190.12 -2.12 -202.12 -226.12 -221.12 -227.12 -234.12
-214.12 -214.12 -215.12 -215.12 -208.12 -196.12 -189.12 -183.12 -184.12
-189.12 -183.12 -177.12 -165.12 -152.12 -146.12 -2.12 -152.12 -170.12
-171.12 -177.12 -171.12 -177.12 -170.12 -159.12 -133.12 -108.12 -77.12
-52.12 -27.12 -8.12 21.88 47.88 -2.12 73.88 84.88 91.88
109.88 122.88 103.88 110.88 110.88 109.88 109.88 110.88 91.88
78.88 66.88 53.88 47.88 34.88 29.88 -2.12 22.88 22.88
15.88 16.88 10.88 3.88 9.88 4.88 -2.12 16.88 -2.12
3.88 -15.12 -8.12 -15.12 -8.12 -8.12 -2.12 -8.12 -8.12
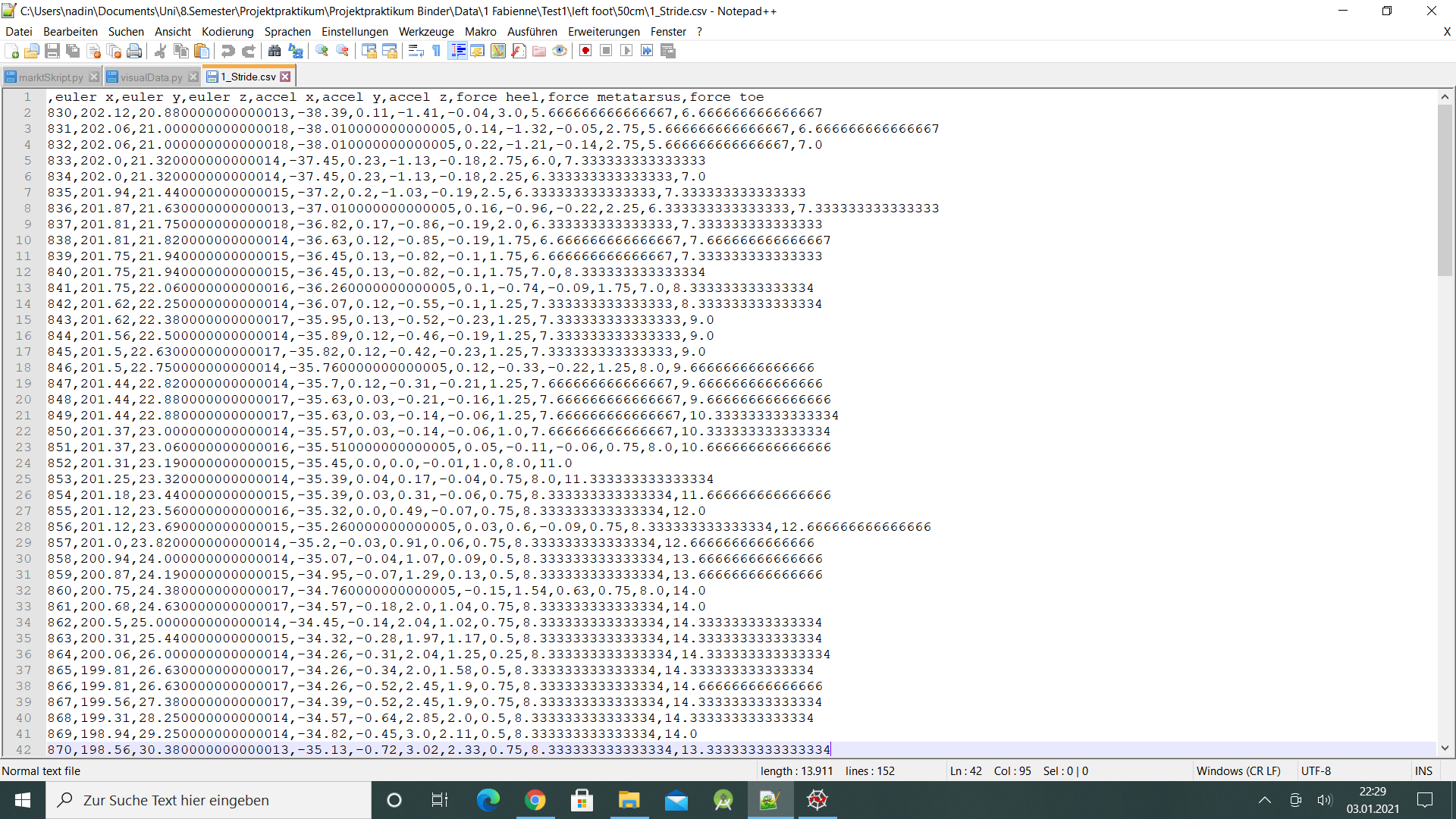
-9.12 -8.12 -8.12 -2.12 -9.12]这就是我的csv文件的样子:
xAcceleration=[ 0.11 0.14 0.22 0.23 0.23 0.2 0.16 0.17 0.12 0.13
0.13 0.1 0.12 0.13 0.12 0.12 0.12 0.12 0.03 0.03
0.03 0.05 0. 0.04 0.03 0. 0.03 -0.03 -0.04 -0.07
-0.15 -0.18 -0.14 -0.28 -0.31 -0.34 -0.52 -0.52 -0.64 -0.45
-0.72 -0.77 -0.9 -1.12 -0.93 -0.75 -0.3 -0.54 -0.87 0.33
1.46 -2.53 -6.01 -7.76 -5.53 -15.57 -17.11 -16.93 -18.82 -15.84
-15.49 -15. -14.66 -13.86 -13.09 -12.26 -11.5 -10.17 -10.17 -9.26
-8.3 -7.19 -5.31 -4.49 -3.97 -3.12 -2.23 -1.3 -0.38 0.51
0.75 0.99 1.63 3.33 4.19 4.86 5.23 5.6 6.16 6.95
6.95 7.87 9.95 11.15 12.17 13.14 14.69 15.34 15.72 15.64
15.54 15.45 15.23 14.64 14. 14. 13.02 11.84 5.01 -4.19
-16.76 -8.5 1.82 -0.42 -1.1 0.03 0.53 0.27 -0.32 -0.46
-0.46 -0.36 -0.09 0.09 -1.08 -0.74 -0.74 -0.43 -0.84 -0.79
-0.84 -0.89 -0.83 -0.82 -0.85 -0.85 -0.91 -0.97 -0.94 -0.88
-0.79 -0.73 -0.77 -0.77 -0.75 -0.76 -0.71 -0.7 -0.64 -0.66]。
yAcceleration=[[-1.41 -1.32 -1.21 -1.13 -1.13 -1.03 -0.96 -0.86 -0.85 -0.82 -0.82 -0.74
-0.55 -0.52 -0.46 -0.42 -0.33 -0.31 -0.21 -0.14 -0.14 -0.11 0. 0.17
0.31 0.49 0.6 0.91 1.07 1.29 1.54 2. 2.04 1.97 2.04 2.
2.45 2.45 2.85 3. 3.02 3.11 3.99 3.85 4.11 3.5 2.75 4.45
5.62 5.43 1.09 8.58 9.26 7.84 4.69 4.17 6.89 8.85 7.86 6.61
5.81 5.48 5.3 4.63 4.47 4.55 4.98 6.68 6.68 7.54 8.15 8.44
8.6 8.57 8.54 8.41 8.2 7.76 7.45 7.58 7.44 6.98 6.62 6.53
6.33 6.04 5.58 4.8 4.37 3.85 3.85 3.04 1.62 0.97 0.63 0.32
-0.38 -0.76 -1.25 -2.07 -2.39 -2.47 -2.37 -1.34 -0.61 -0.61 -0.33 -0.69
2.73 2.48 4.25 2.13 0.12 0.93 1.76 1.22 1.62 1.54 1.19 1.15
1.53 1.07 1.15 1.47 0.67 0.66 0.66 0.63 0.13 0.11 0.01 -0.06
0. 0.03 0.11 0.11 0.2 0.25 0.34 0.31 0.32 0.27 0.31 0.31
0.4 0.42 0.39 0.35 0.25 0.2 ]堆栈跟踪:
Traceback (most recent call last):
File "C:\Users\nadin\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 3343, in run_code
self.showtraceback(running_compiled_code=True)
File "C:\Users\nadin\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2043, in showtraceback
value, tb, tb_offset=tb_offset)
File "C:\Users\nadin\Anaconda3\lib\site-packages\IPython\core\ultratb.py", line 1385, in structured_traceback
self, etype, value, tb, tb_offset, number_of_lines_of_context)
File "C:\Users\nadin\Anaconda3\lib\site-packages\IPython\core\ultratb.py", line 1297, in structured_traceback
elist = self._extract_tb(tb)
File "C:\Users\nadin\Anaconda3\lib\site-packages\IPython\core\ultratb.py", line 1278, in _extract_tb
return traceback.extract_tb(tb)
File "C:\Users\nadin\Anaconda3\lib\traceback.py", line 72, in extract_tb
return StackSummary.extract(walk_tb(tb), limit=limit)
File "C:\Users\nadin\Anaconda3\lib\traceback.py", line 363, in extract
f.line
File "C:\Users\nadin\Anaconda3\lib\traceback.py", line 285, in line
self._line = linecache.getline(self.filename, self.lineno).strip()
File "C:\Users\nadin\Anaconda3\lib\linecache.py", line 16, in getline
lines = getlines(filename, module_globals)
File "C:\Users\nadin\Anaconda3\lib\linecache.py", line 47, in getlines
return updatecache(filename, module_globals)
File "C:\Users\nadin\Anaconda3\lib\linecache.py", line 137, in updatecache
lines = fp.readlines()
File "C:\Users\nadin\Anaconda3\lib\codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xdf in position 1382: invalid continuation byte注释: strideData代表导入的CSV文件。
回答 1
Stack Overflow用户
发布于 2021-01-04 09:07:05
Spyder告诉你你的源文件是ISO 8859-1,a.k.a.拉丁文-1。这是Spyder的猜测,但可能是一个准确的猜测,基于名字、归属或评论中的版权声明。这不是问题所在。确实,Python解释器在默认情况下期望源代码为UTF-8。但是,只有当遇到错误的编码时,例如字符串文字,它才会抱怨。这样的话,它就跑不了了。相反,它将给出错误SyntaxError: Non-UTF-8 code starting with ... but no encoding declared。当您的代码运行并读取文件时,会发生错误。更改Python源代码的编码不会修复这个问题。
你的回溯很明显。被投诉的输入文件不是UTF-8。无论如何都不是有效的UTF-8。我知道您认为是这样的,但是(冒着重新声明显而易见的风险)消息说:“在解码一个文件的过程中,预期是UTF-8,在1382位置遇到了一个字节序列,它不是有效的UTF-8字节序列。违规字节是0xDF。”编码库是UTF-8的一个操作定义,因此它在这个主题上总是正确的。
可能是带有意外编码的输入文件不是您认为是的文件。
合理的猜测是,输入文件实际上和您的源一样,也是拉丁文-1。在拉丁文-1中,字节0xDF是,而我的预感是它之前的一个;但有太多的可能性,以准确地猜测。
https://stackoverflow.com/questions/65554410
复制相似问题
腾讯云开发者
