
Tensorflow的TripletSemiHardLoss和TripletHardLoss是如何使用的,以及如何在暹罗网络中使用?
据我所知,Triplet Loss是一个损失函数,它减少了锚与正之间的距离,但减小了锚与负之间的距离。此外,它还增加了一个保证金。
例如,LEt us假设:一个提供嵌入的Siamese Network:
anchor_output = [1,2,3,4,5...] # embedding given by the CNN model
positive_output = [1,2,3,4,4...]
negative_output= [53,43,33,23,13...]我想我可以得到三胞胎的损失,比如:(我想我必须用Lambda层作为损失)。
# calculate triplet loss
d_pos = tf.reduce_sum(tf.square(anchor_output - positive_output), 1)
d_neg = tf.reduce_sum(tf.square(anchor_output - negative_output), 1)
loss = tf.maximum(0., margin + d_pos - d_neg)
loss = tf.reduce_mean(loss)那么到底是什么呢:tfa.losses.TripletHardLoss和tfa.losses.TripletSemiHardLoss
据我所知,Siamese Techniques的数据生成技术是半硬的,这推动了模型学习得更多。
MY Thinking:正如我在这篇文章中学到的,我认为你可以做到:
- 生成一批(例如3幅)图像,并生成一对具有
27图像的3幅图像 - 丢弃每个无效的对( i、j、k应该是唯一的)。剩余批
B - 获取批处理
B中每对上的嵌入
因此,我认为HardTripletLoss只考虑了每批3张图像,其中最大的锚固正距离和最小的锚负距离。
对于Semi Hard,我认为它丢弃了所有由距离为0的图像对计算的损失。
如果没有,请有人纠正我,并告诉我如何使用这些。(我知道我们可以在model.complie()内部使用它,但我的问题不一样。
回答 1
Stack Overflow用户
发布于 2021-01-06 04:56:38
什么是TripletHardLoss?
此损失遵循普通的TripletLoss形式,但在计算损失时使用最大正距离和最小负距离加上批内的裕度常数,我们在公式中可以看到:
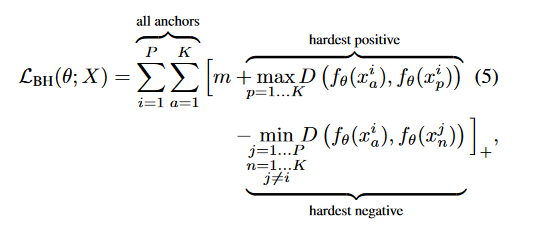
查看一下源代码 of tfa.losses.TripletHardLoss,我们可以看到上面的公式是精确实现的:
# Build pairwise binary adjacency matrix.
adjacency = tf.math.equal(labels, tf.transpose(labels))
# Invert so we can select negatives only.
adjacency_not = tf.math.logical_not(adjacency)
adjacency_not = tf.cast(adjacency_not, dtype=tf.dtypes.float32)
# hard negatives: smallest D_an.
hard_negatives = _masked_minimum(pdist_matrix, adjacency_not)
batch_size = tf.size(labels)
adjacency = tf.cast(adjacency, dtype=tf.dtypes.float32)
mask_positives = tf.cast(adjacency, dtype=tf.dtypes.float32) - tf.linalg.diag(
tf.ones([batch_size])
)
# hard positives: largest D_ap.
hard_positives = _masked_maximum(pdist_matrix, mask_positives)
if soft:
triplet_loss = tf.math.log1p(tf.math.exp(hard_positives - hard_negatives))
else:
triplet_loss = tf.maximum(hard_positives - hard_negatives + margin, 0.0)
# Get final mean triplet loss
triplet_loss = tf.reduce_mean(triplet_loss)注意,soft参数在tfa.losses.TripletHardLoss中是而不是,使用下面的公式计算普通TripletLoss
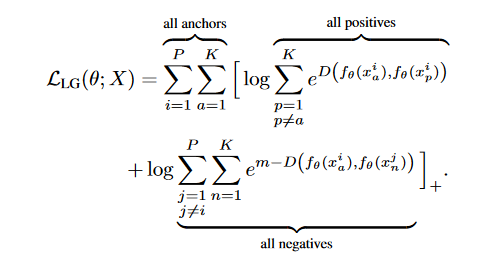
因为正如我们在上面的源代码中所看到的,它仍然使用最大正距离和最小负距离,它决定是否使用软边距。
什么是TripletSemiHardLoss?
这种损耗也遵循普通的TripletLoss形式,正距离与普通TripletLoss中的正距离和半硬负中的负距离相同。
其中最小负距离至少大于正距离加上裕度常数,如果不存在这种负距离,则使用最大的负距离。
也就是说,我们首先要找到满足以下条件的负距离:
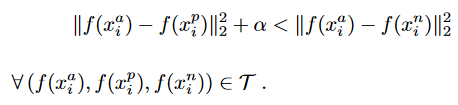
p表示正,n表示负,如果n不能找到满足这个条件的负距离,则使用最大负距离。
正如我们在源代码 of tfa.losses.TripletSemiHardLoss中可以看到的那样,negatives_outside是满足这个条件的距离,negatives_inside是最大的负距离:
# Build pairwise binary adjacency matrix.
adjacency = tf.math.equal(labels, tf.transpose(labels))
# Invert so we can select negatives only.
adjacency_not = tf.math.logical_not(adjacency)
batch_size = tf.size(labels)
# Compute the mask.
pdist_matrix_tile = tf.tile(pdist_matrix, [batch_size, 1])
mask = tf.math.logical_and(
tf.tile(adjacency_not, [batch_size, 1]),
tf.math.greater(
pdist_matrix_tile, tf.reshape(tf.transpose(pdist_matrix), [-1, 1])
),
)
mask_final = tf.reshape(
tf.math.greater(
tf.math.reduce_sum(
tf.cast(mask, dtype=tf.dtypes.float32), 1, keepdims=True
),
0.0,
),
[batch_size, batch_size],
)
mask_final = tf.transpose(mask_final)
adjacency_not = tf.cast(adjacency_not, dtype=tf.dtypes.float32)
mask = tf.cast(mask, dtype=tf.dtypes.float32)
# negatives_outside: smallest D_an where D_an > D_ap.
negatives_outside = tf.reshape(
_masked_minimum(pdist_matrix_tile, mask), [batch_size, batch_size]
)
negatives_outside = tf.transpose(negatives_outside)
# negatives_inside: largest D_an.
negatives_inside = tf.tile(
_masked_maximum(pdist_matrix, adjacency_not), [1, batch_size]
)
semi_hard_negatives = tf.where(mask_final, negatives_outside, negatives_inside)
loss_mat = tf.math.add(margin, pdist_matrix - semi_hard_negatives)
mask_positives = tf.cast(adjacency, dtype=tf.dtypes.float32) - tf.linalg.diag(
tf.ones([batch_size])
)
# In lifted-struct, the authors multiply 0.5 for upper triangular
# in semihard, they take all positive pairs except the diagonal.
num_positives = tf.math.reduce_sum(mask_positives)
triplet_loss = tf.math.truediv(
tf.math.reduce_sum(
tf.math.maximum(tf.math.multiply(loss_mat, mask_positives), 0.0)
),
num_positives,
)如何利用这些损失?
两种丢失都期望y_true作为一维整数Tensor提供,其形状为多类整数标签的形状batch_size。嵌入y_pred必须是l2归一化嵌入向量的二维浮点Tensor .
准备输入和标签的示例代码:
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(16)
train_dataset = train_dataset.map(_normalize_img)
# Take one batch of data
for data in train_dataset.take(1):
print("Batch of images shape:\n{}\nBatch of labels:\n{}\n".format(data[0].shape, data[1]))产出:
Batch of images shape:
(16, 28, 28, 1)
Batch of labels:
[8 4 0 3 2 4 5 1 0 5 7 0 2 6 4 9]如果在使用时遇到问题,请遵循此)一般情况下。
https://stackoverflow.com/questions/65579247
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号