
语法不分隔'123和],尽管为它设置了规则
语法不分隔'123和],尽管为它设置了规则
提问于 2021-02-24 02:28:41
我是新来的。我试图解析一些查询,如网络流量:src_port= '123和网络流量:src_port=和网络流量:src_port= and .我有如下语法:
grammar STIXPattern;
pattern
: observationExpressions EOF
;
observationExpressions
: <assoc=left> observationExpressions FOLLOWEDBY observationExpressions #observationExpressionsFollowedBY
| observationExpressionOr #observationExpressionOr_
;
observationExpressionOr
: <assoc=left> observationExpressionOr OR observationExpressionOr #observationExpressionOred
| observationExpressionAnd #observationExpressionAnd_
;
observationExpressionAnd
: <assoc=left> observationExpressionAnd AND observationExpressionAnd #observationExpressionAnded
| observationExpression #observationExpression_
;
observationExpression
: LBRACK comparisonExpression RBRACK # observationExpressionSimple
| LPAREN observationExpressions RPAREN # observationExpressionCompound
| observationExpression startStopQualifier # observationExpressionStartStop
| observationExpression withinQualifier # observationExpressionWithin
| observationExpression repeatedQualifier # observationExpressionRepeated
;
comparisonExpression
: <assoc=left> comparisonExpression OR comparisonExpression #comparisonExpressionOred
| comparisonExpressionAnd #comparisonExpressionAnd_
;
comparisonExpressionAnd
: <assoc=left> comparisonExpressionAnd AND comparisonExpressionAnd #comparisonExpressionAnded
| propTest #comparisonExpressionAndpropTest
;
propTest
: objectPath NOT? (EQ|NEQ) primitiveLiteral # propTestEqual
| objectPath NOT? (GT|LT|GE|LE) orderableLiteral # propTestOrder
| objectPath NOT? IN setLiteral # propTestSet
| objectPath NOT? LIKE StringLiteral # propTestLike
| objectPath NOT? MATCHES StringLiteral # propTestRegex
| objectPath NOT? ISSUBSET StringLiteral # propTestIsSubset
| objectPath NOT? ISSUPERSET StringLiteral # propTestIsSuperset
| LPAREN comparisonExpression RPAREN # propTestParen
| objectPath NOT? (EQ|NEQ) objectPathThl # propTestThlEqual
;
startStopQualifier
: START TimestampLiteral STOP TimestampLiteral
;
withinQualifier
: WITHIN (IntPosLiteral|FloatPosLiteral) SECONDS
;
repeatedQualifier
: REPEATS IntPosLiteral TIMES
;
objectPath
: objectType COLON firstPathComponent objectPathComponent?
;
objectPathThl
: varThlType DOT firstPathComponent objectPathComponent?
;
objectType
: IdentifierWithoutHyphen
| IdentifierWithHyphen
;
varThlType
: IdentifierWithoutHyphen
| IdentifierWithHyphen
;
firstPathComponent
: IdentifierWithoutHyphen
| StringLiteral
;
objectPathComponent
: <assoc=left> objectPathComponent objectPathComponent # pathStep
| '.' (IdentifierWithoutHyphen | StringLiteral) # keyPathStep
| LBRACK (IntPosLiteral|IntNegLiteral|ASTERISK) RBRACK # indexPathStep
;
setLiteral
: LPAREN RPAREN
| LPAREN primitiveLiteral (COMMA primitiveLiteral)* RPAREN
;
primitiveLiteral
: orderableLiteral
| BoolLiteral
| edgeCases
;
edgeCases
: QUOTE (IdentifierWithHyphen | IdentifierWithoutHyphen | IntNoSign) RBRACK
| RBRACK
;
orderableLiteral
: IntPosLiteral
| IntNegLiteral
| FloatPosLiteral
| FloatNegLiteral
| StringLiteral
| BinaryLiteral
| HexLiteral
| TimestampLiteral
;
IntNegLiteral :
'-' ('0' | [1-9] [0-9]*)
;
IntNoSign :
('0' | [1-9] [0-9]*)
;
IntPosLiteral :
'+'? ('0' | [1-9] [0-9]*)
;
FloatNegLiteral :
'-' [0-9]* '.' [0-9]+
;
FloatPosLiteral :
'+'? [0-9]* '.' [0-9]+
;
HexLiteral :
'h' QUOTE TwoHexDigits* QUOTE
;
BinaryLiteral :
'b' QUOTE
( Base64Char Base64Char Base64Char Base64Char )*
( (Base64Char Base64Char Base64Char Base64Char )
| (Base64Char Base64Char Base64Char ) '='
| (Base64Char Base64Char ) '=='
)
QUOTE
;
StringLiteral :
QUOTE ( ~['\\] | '\\\'' | '\\\\' )* QUOTE
;
BoolLiteral :
TRUE | FALSE
;
TimestampLiteral :
't' QUOTE
[0-9] [0-9] [0-9] [0-9] HYPHEN
( ('0' [1-9]) | ('1' [012]) ) HYPHEN
( ('0' [1-9]) | ([12] [0-9]) | ('3' [01]) )
'T'
( ([01] [0-9]) | ('2' [0-3]) ) COLON
[0-5] [0-9] COLON
([0-5] [0-9] | '60')
(DOT [0-9]+)?
'Z'
QUOTE
;
//////////////////////////////////////////////
// Keywords
AND: 'AND' ;
OR: 'OR' ;
NOT: 'NOT' ;
FOLLOWEDBY: 'FOLLOWEDBY';
LIKE: 'LIKE' ;
MATCHES: 'MATCHES' ;
ISSUPERSET: 'ISSUPERSET' ;
ISSUBSET: 'ISSUBSET' ;
LAST: 'LAST' ;
IN: 'IN' ;
START: 'START' ;
STOP: 'STOP' ;
SECONDS: 'SECONDS' ;
TRUE: 'true' ;
FALSE: 'false' ;
WITHIN: 'WITHIN' ;
REPEATS: 'REPEATS' ;
TIMES: 'TIMES' ;
// After keywords, so the lexer doesn't tokenize them as identifiers.
// Object types may have unquoted hyphens, but property names
// (in object paths) cannot.
IdentifierWithoutHyphen :
[a-zA-Z_] [a-zA-Z0-9_]*
;
IdentifierWithHyphen :
[a-zA-Z_] [a-zA-Z0-9_-]*
;
EQ : '=' | '==';
NEQ : '!=' | '<>';
LT : '<';
LE : '<=';
GT : '>';
GE : '>=';
QUOTE : '\'';
COLON : ':' ;
DOT : '.' ;
COMMA : ',' ;
RPAREN : ')' ;
LPAREN : '(' ;
RBRACK : ']' ;
LBRACK : '[' ;
PLUS : '+' ;
HYPHEN : MINUS ;
MINUS : '-' ;
POWER_OP : '^' ;
DIVIDE : '/' ;
ASTERISK : '*';
EQRBRAC : ']';
fragment HexDigit: [A-Fa-f0-9];
fragment TwoHexDigits: HexDigit HexDigit;
fragment Base64Char: [A-Za-z0-9+/];
// Whitespace and comments
//
WS : [ \t\r\n\u000B\u000C\u0085\u00a0\u1680\u2000\u2001\u2002\u2003\u2004\u2005\u2006\u2007\u2008\u2009\u200a\u2028\u2029\u202f\u205f\u3000]+ -> skip
;
COMMENT
: '/*' .*? '*/' -> skip
;
LINE_COMMENT
: '//' ~[\r\n]* -> skip
;
// Catch-all to prevent lexer from silently eating unusable characters.
InvalidCharacter
: .
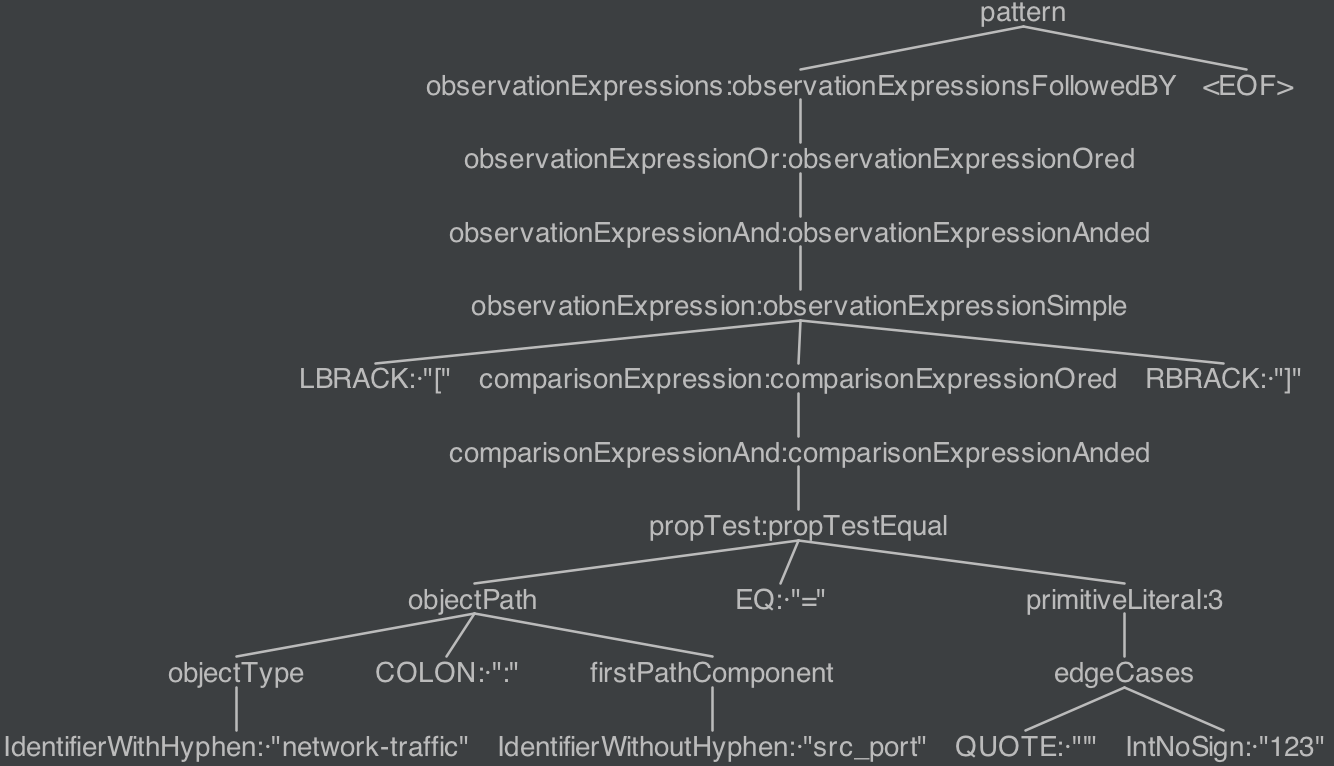
;现在,当我输入网络流量:src_port= '123时,我希望antlr将查询解析为'123和]。
但是语法返回'123]而不能分开'123‘和]是不是遗漏了什么?
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-02-24 07:39:40
语法不分隔'123和],尽管为其设置了规则
那不是真的。引号和123是单独的标记。正如在您的previous反the问题中所演示/建议的那样:首先,将所有令牌打印到您的控制台,以查看正在创建哪些令牌。在尝试调试ANTLR语法时,这应该始终是第一件事。这会帮你节省很多时间和头痛。
事实上,[network-traffic:src_port = '123]没有被正确地解析,是因为](RBRACK)正在被替代的observationExpressionSimple所消耗。
observationExpression
: LBRACK comparisonExpression RBRACK # observationExpressionSimple
| LPAREN observationExpressions RPAREN # observationExpressionCompound
| observationExpression startStopQualifier # observationExpressionStartStop
| observationExpression withinQualifier # observationExpressionWithin
| observationExpression repeatedQualifier # observationExpressionRepeated
;因为解析器规则已经使用了RBRACK,所以edgeCases规则也不能使用这个RBRACK令牌。
要解决这个问题,请更改您的规则:
edgeCases
: QUOTE (IdentifierWithHyphen | IdentifierWithoutHyphen | IntNoSign) RBRACK
| RBRACK
;这方面:
edgeCases
: QUOTE (IdentifierWithHyphen | IdentifierWithoutHyphen | IntNoSign)
;现在将正确地解析[network-traffic:src_port = '123]:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66343836
复制相关文章
相似问题
腾讯云开发者
