
当在SavedModel中加载TF2时,报告"signature_wrapper接受0的位置参数,但给出了1“
当在SavedModel中加载TF2时,报告"signature_wrapper接受0的位置参数,但给出了1“
提问于 2021-03-24 11:53:34
我试图创建一个解码器,它以五张元组作为输入。当我将它保存为.h5时,它可以正常工作,但是当我试图保存(没有错误报告)、加载和进行推断时,它会报告:
Traceback (most recent call last):
File "D:/MA/Recources/monodepth2-torch/dsy.py", line 196, in <module>
build_model(inputs)
File "D:/MA/Recources/monodepth2-torch/dsy.py", line 185, in build_model
outputs = decoder_pb(inputs)
File "C:\Users\Dexxh\AppData\Roaming\Python\Python36\site-packages\tensorflow\python\eager\function.py", line 1655, in __call__
return self._call_impl(args, kwargs)
File "C:\Users\Dexxh\AppData\Roaming\Python\Python36\site-packages\tensorflow\python\eager\function.py", line 1673, in _call_impl
return self._call_with_flat_signature(args, kwargs, cancellation_manager)
File "C:\Users\Dexxh\AppData\Roaming\Python\Python36\site-packages\tensorflow\python\eager\function.py", line 1695, in _call_with_flat_signature
len(args)))
TypeError: signature_wrapper(input_1, input_2, input_3, input_4, input_5) takes 0 positional arguments but 1 were given我对该模型的定义如下。细节似乎没有问题,因为当我以Keras模型加载它时,它运行得很好。如果你需要的话,我使用tensorflow 2.3.1。
class DepthDecoder(tf.keras.Model):
def __init__(self):
super(DepthDecoder, self).__init__()
self.num_ch_enc = [64, 64, 128, 256, 512]
self.num_ch_dec = [16, 32, 64, 128, 256]
self.scales = [0,1,2,3] # range(4)
self.num_output_channels = 1
self.convs_0 = [None]*len(self.num_ch_dec)
self.convs_1 = [None]*len(self.num_ch_dec)
# todo: dispconv can be multiple output
self.dispconv_0 = self.make_conv(self.num_ch_dec[0], self.num_output_channels, activate_type=None,
pad_mode='reflect', type='disp', index=0)
for i in range(4, -1, -1):
# upconv_0
num_ch_in = self.num_ch_enc[-1] if i == 4 else self.num_ch_dec[i + 1]
num_ch_out = self.num_ch_dec[i]
self.convs_0[i] = self.make_conv(num_ch_in, num_ch_out, pad_mode='reflect', activate_type='elu',
type='conv_0', index=i)
# upconv_1
num_ch_in = self.num_ch_dec[i]
if i > 0:
num_ch_in += self.num_ch_enc[i - 1]
num_ch_out = self.num_ch_dec[i]
self.convs_1[i] = self.make_conv(num_ch_in, num_ch_out, pad_mode='reflect', activate_type='elu',
type='conv_1', index=i)
def make_conv(self, input_channel, filter_num, activate_type=None, pad_mode='reflect',
type:str=None, index=-1, input_shape:tuple=None):
name = None
if type is not None and index != -1:
name = ''.join([type, '_%d'%index])
if pad_mode == 'reflect':
padding = 'valid'
else:
padding = 'same'
conv = Conv2D(filters=filter_num, kernel_size=3, activation=activate_type,
strides=1, padding=padding, use_bias=True, name=name)
return conv
def call(self, input_features, training=None, mask=None):
ch_axis = 3
x = input_features[-1]
for i in range(4, -1, -1):
x = tf.pad(x, [[0, 0], [1, 1], [1, 1], [0, 0]], mode='REFLECT')
x = self.convs_0[i](x)
x = [tf.keras.layers.UpSampling2D()(x)]
if i > 0:
x += [input_features[i - 1]]
x = tf.concat(x, ch_axis)
x = tf.pad(x, [[0, 0], [1, 1], [1, 1], [0, 0]], mode='REFLECT')
x = self.convs_1[i](x)
# outputs.append(tf.math.sigmoid(x))
x = tf.pad(x, [[0, 0], [1, 1], [1, 1], [0, 0]], mode='REFLECT')
x = self.dispconv_0(x)
disp0 = tf.math.sigmoid(x)
return disp0然后保存并加载:
inputs = (tf.random.uniform(shape=(1,96, 320, 64)),
tf.random.uniform(shape=(1,48, 160, 64)),
tf.random.uniform(shape=(1,24, 80, 128)),
tf.random.uniform(shape=(1,12, 40, 256)),
tf.random.uniform(shape=(1,6, 20, 512)))
# Load
decoder = DepthDecoder()
outputs = decoder.predict(inputs)
decoder = decoder_load_weights(decoder) # a custom weights loading from Pytorch, weights, details see below
tf.keras.models.save_model(decoder, "decoder_test")
# Inference
decoder_import = tf.saved_model.load("decoder_test")
decoder_pb = decoder_import.signatures['serving_default']
outputs = decoder_pb(inputs)
for k, v in outputs:
print(v.shape)
# For completeness, here is the decoder_load_weigths() function
def decoder_load_weights(decoder, weights_path=None):
# Weights as List of ndarray, stored layerwise. Since it's fully convolutional, it's like [[#conv_0]*5,[#conv1]*5, [dispconv]], nothing else.
decoder_weights = np.load(weights_path, allow_pickle=True)
ind = 0
for l in decoder.layers:
print(l.name)
weights = l.get_weights()
if len(weights) == 0:
print("no weigths")
else:
print(weights[0].shape, "\t", weights[1].shape)
print(weights_grouped[ind][0].shape, "\t", weights_grouped[ind][1].shape)
new_weights = weights_grouped[ind]
l.set_weights(new_weights)
print("loading the %dnd conv layer..."% ind)
ind += 1
return decoder奇怪的是,它说采用位置参数,表示不允许输入。你能提供一些见解吗?谢谢!!
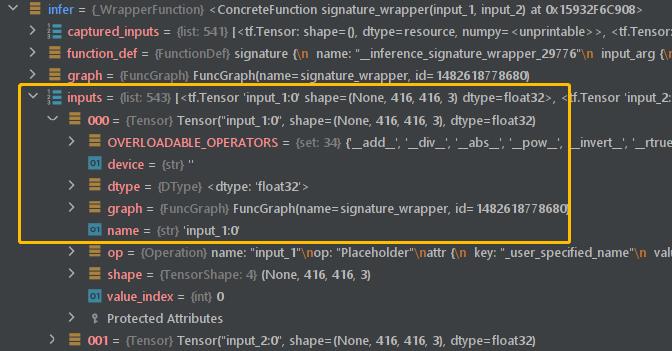
最后,让我发布decoder_pb内部的快照(快照中称为infer )。您可以看到,decoder_pb实际上已经有了名为input_1、input_2等的Tensor,因此问题是,如何将输入分配给他们。我不能直接给它们分配张量,因为指定的张量的“名称”不是input_1,而EagerTensor不能被重命名为。
我记得在TF1.x中有feed_dict通过了session,不知道它是否相关.
回答 1
Stack Overflow用户
发布于 2021-03-25 07:12:35
解决了!
这正是错误报告的含义.它不需要位置参数,这意味着它只使用关键字参数。所以解决办法是
res = infer(input_1=features[0], input_2=features[1], ...)或
# feed_dict = {'input_1' : features[0], ...}
res = infer(**feed_dict)但这是不被接受的:
disp_raw = decoder(features[0], features[1],features[2],features[3], features[4])这实际上很奇怪,因为通常我们不需要指定关键字,只要我们按照正确的顺序传递它们。另外,当我们只有一个输入(例如res = infer(#one_tensor) )时,我们不需要这样做。
所以我猜这是一种虫子?不管怎么说,希望其他遇到这个问题的人能从这个答案中受益:)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66780478
复制相关文章
相似问题
腾讯云开发者
