
Pyspark:检查每个单元格的条件并计算校验位数
Pyspark:检查每个单元格的条件并计算校验位数
提问于 2021-11-14 16:56:05
我有一个列RESULT,在每个列中都有长度为11的数字,其模式是:
RESULT: string (nullable = true)
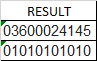
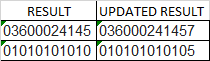
现在,我想执行下面的操作,并更新一个新的列,这将增加一个额外的数字在最后。下面所示的示例用于第一个数字03600024145
注意事项:我不想把桌子的格式改成熊猫,但是我想用Pyspark做所有的事情。
- 添加奇数数字: 0+6+0+2+1+5 = 14。
- 结果乘以3: 14×3= 42。
- 添加偶数位数: 3+0+0+4+4 = 11。
- 将这两个结果相加: 42 + 11 = 53。
- 要计算校验数字,取(53 / 10 )的余数,也称为(53模10),如果不是0,则从10减去。因此,校验数字值为7,即(53 / 10) =5余数3;10-3= 7。
- 最后加这个支票数字。所以这个数字变成了
036000241457
因此,如果将此逻辑应用于整个列,结果将变成UPDATED RESULT。
为了进一步澄清逻辑:digit#UPC
有类似的python代码,但在第5步:python:创建检查数字函数中有一点不同。
回答 3
Stack Overflow用户
回答已采纳
发布于 2021-11-14 17:35:50
我们可以把逻辑转换成火花函数。
- 首先在不同的位置提取数字并将它们转换为整数。
- 然后分别求和奇数位和偶数位。
- 奇数和乘以3,再加上偶数和。
- 应用模块化操作。
- 根据步骤4的结果减去10,然后应用模10,当步骤4的结果为0时,模拟校验数字为0的行为。
- 最后,将
RESULT列与check digit连接起来。
工作实例
import pyspark.sql.functions as F
from pyspark.sql import Column
from typing import List
df = spark.createDataFrame([("03600024145",), ("01010101010",)], ("RESULT",))
def sum_digits(c: Column, pos: List[int]):
sum_col = F.lit(0)
for p in pos:
sum_col = sum_col + F.substring(c, p, 1).cast("int")
return sum_col
def check_digit(c: Column) -> Column:
odd_sum = sum_digits(c, [1, 3, 5, 7, 9, 11])
even_sum = sum_digits(c, [2, 4, 6, 8, 10])
sum_result = (3 * odd_sum) + even_sum
modulo = sum_result % 10
return (10 - modulo) % 10
df.withColumn("UPDATED_RESULT", F.concat(F.col("RESULT"), check_digit(F.col("RESULT")))).show()输出
+-----------+--------------+
| RESULT|UPDATED_RESULT|
+-----------+--------------+
|03600024145| 036000241457|
|01010101010| 010101010105|
+-----------+--------------+Stack Overflow用户
发布于 2021-11-14 17:54:15
使用用户定义函数(udf)的解决方案。
from pyspark.sql.types import StringType
from pyspark.sql.functions import udf, col
df = spark.createDataFrame([('03600024145',), ('01010101010',)], ['RESULT'])
@udf(StringType())
def add_check_digit(val):
odd = sum(int(i) for i in val[::2])
even = sum(int(i) for i in val[1::2])
check_val = (odd * 3 + even) % 10
return val + str((10 - check_val) % 10)
df = df.withColumn('UPDATED_RESULT', add_check_digit(col('RESULT')))
df.show()
+-----------+--------------+
| RESULT|UPDATED_RESULT|
+-----------+--------------+
|03600024145| 036000241457|
|01010101010| 010101010105|
+-----------+--------------+Stack Overflow用户
发布于 2021-11-14 18:00:46
可以将列RESULT拆分为一个数字数组,而不是使用一些高阶函数transform和aggregate,您可以计算连接到原始字符串的checkdigit:
import pyspark.sql.functions as F
df1 = df.withColumn(
"digits",
F.expr("slice(split(RESULT, ''), 1, size(split(RESULT, '')) - 1)")
).withColumn(
"digits",
F.expr("transform(digits, (x, i) -> struct(int(x) as d, i+1 as i))")
).withColumn(
"odd_even",
F.expr(
"""aggregate(digits,
array(0, 0),
(acc, x) ->
IF (x.i%2 = 1,
array(acc[0] + x.d, acc[1]),
array(acc[0], acc[1] + x.d)
)
)""")
).withColumn(
"UPDATED RESULT",
F.concat(F.col("RESULT"), 10 - ((F.col("odd_even")[0] * 3 + F.col("odd_even")[1]) % 10))
).select(
"RESULT", "UPDATED RESULT"
)
df1.show(truncate=False)
#+-----------+--------------+
#|RESULT |UPDATED RESULT|
#+-----------+--------------+
#|03600024145|036000241457 |
#|01010101010|010101010105 |
#+-----------+--------------+解释:
- 步骤1:拆分列,并将得到的数组切片移除最后一个空值。然后,通过添加数组的索引,对数组的每个元素进行转换。(例如
0 -> struct(0, 1)) - 步骤2:使用我们在第一步中添加的索引使用聚合、求和偶数和奇数位置数字。
- 步骤3:计算检查数字并将其与结果列连接
您可以显示所有中间列来理解逻辑。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69965226
复制相关文章
相似问题
腾讯云开发者
