
熊猫read_csv错误命名栏
熊猫read_csv错误命名栏
提问于 2021-11-27 15:53:48
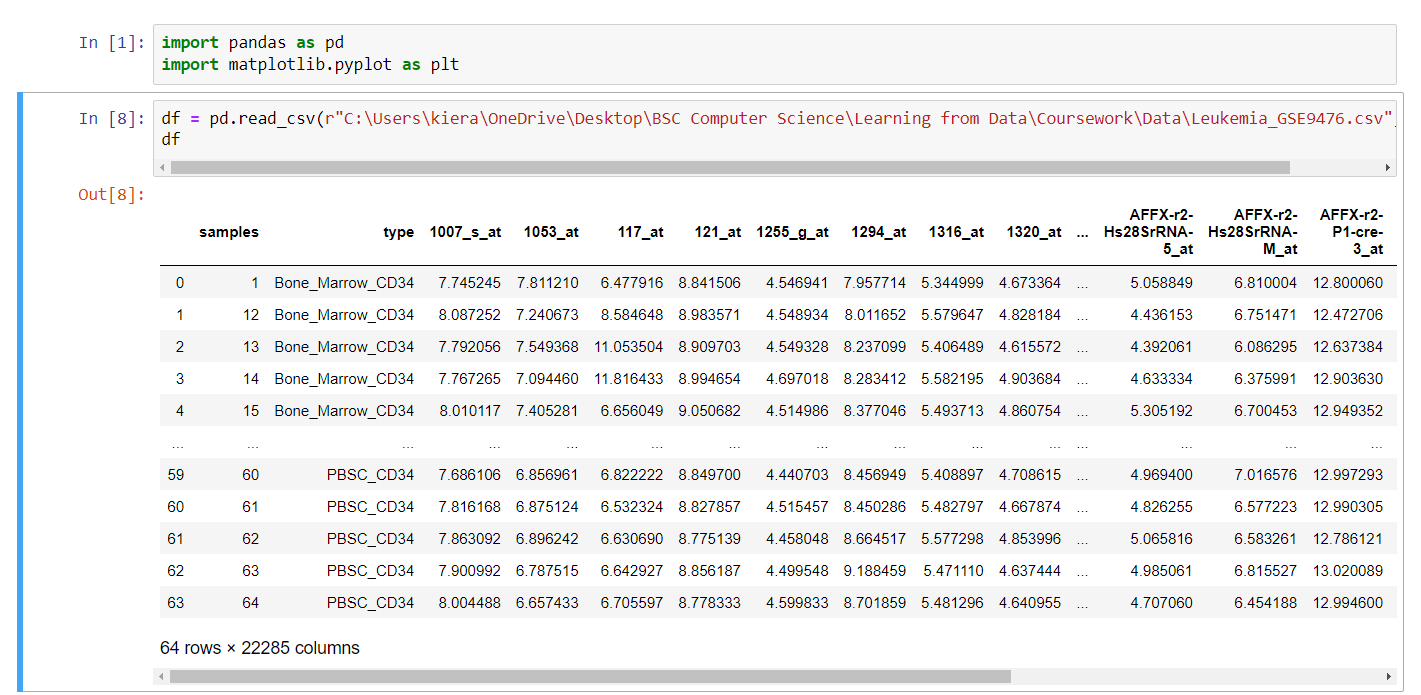
我正在尝试导入在https://www.kaggle.com/brunogrisci/leukemia-gene-expression-cumida上发现的白血病基因表达数据集。这个数据集有很多列(22285),在末尾导入的列有一个不正确的名称。例如,名为AFFX-r2-P1-cre-3_at的最后一列实际上在csv文件中被称为217005_at。下面的图片显示了我的笔记本电脑电池。我不知道它为什么是这样格式化的?任何帮助都将不胜感激。
回答 1
Stack Overflow用户
发布于 2021-11-28 15:58:42
显然,CSV文件的列名以'AFFX-r2-P1‘开头--这不是熊猫的问题。使用内置的csv包显示:
import csv
from pathlib import Path
data_file = Path('../../../Downloads/Leukemia_GSE9476.csv')
with open(data_file, 'rt') as lines:
csv_file = csv.reader(lines)
fields = next(csv_file)
#
[
(field_number, field)
for field_number, field in enumerate(fields)
if field.startswith('AFFX-r2-P1')
]产出如下:
[(22277, 'AFFX-r2-P1-cre-3_at'), (22278, 'AFFX-r2-P1-cre-5_at')]页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/70136362
复制相关文章
相似问题
腾讯云开发者
