
鸟鸣音频分析-找到两个剪辑如何匹配
我有~100个wav音频文件,样本率为48000的同类鸟类,我想测量它们之间的相似性。我从wave文件开始,但我对处理图像了解更多(非常稍微),所以我假设我的分析将出现在谱图图像上。我有几个不同日子的一些鸟的样本。
以下是数据的一些示例(对未标记的轴表示歉意;x是样本,y是线性频率乘以大约10,000 Hz的频率):
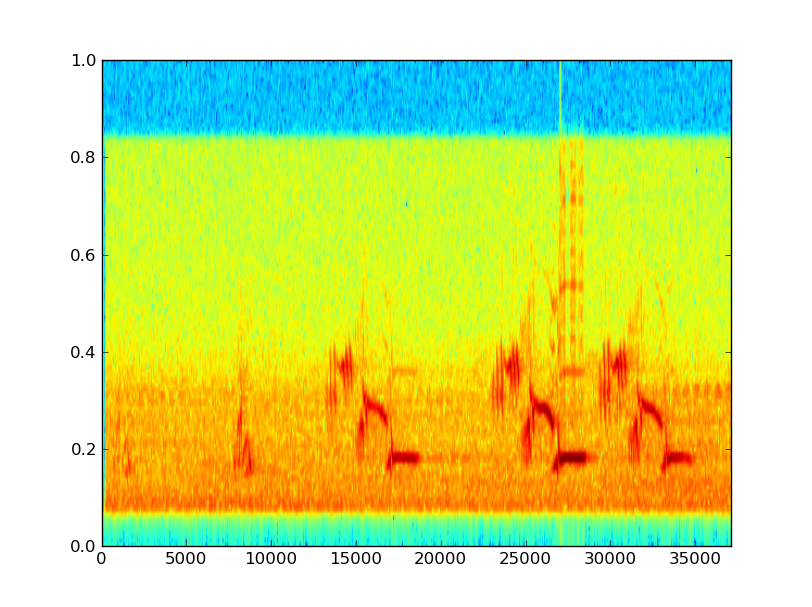
这些鸟歌显然发生在“单词”中,这可能是我应该比较的水平;相似的词和不同单词的频率和顺序的差异。
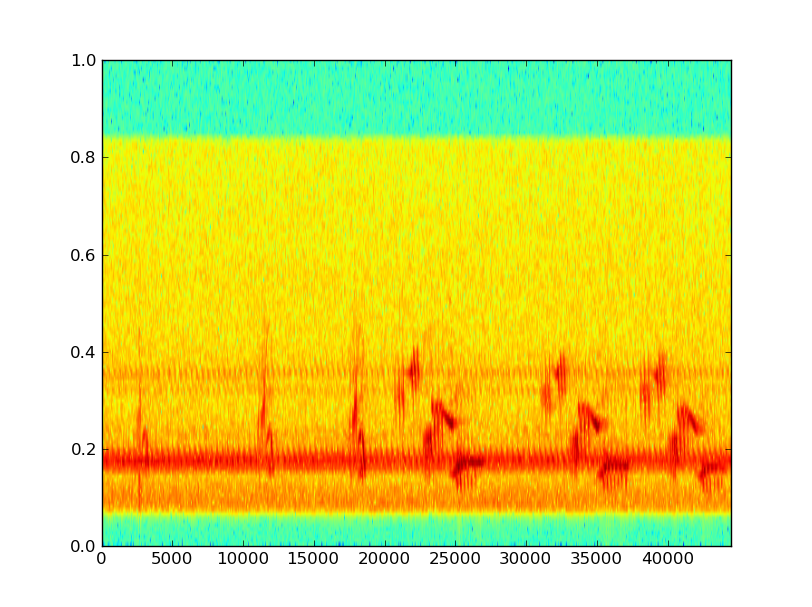
我想尝试消除蝉噪声-蝉啁啾的相当一致的频率,并倾向于相位匹配,所以这应该不会太难。
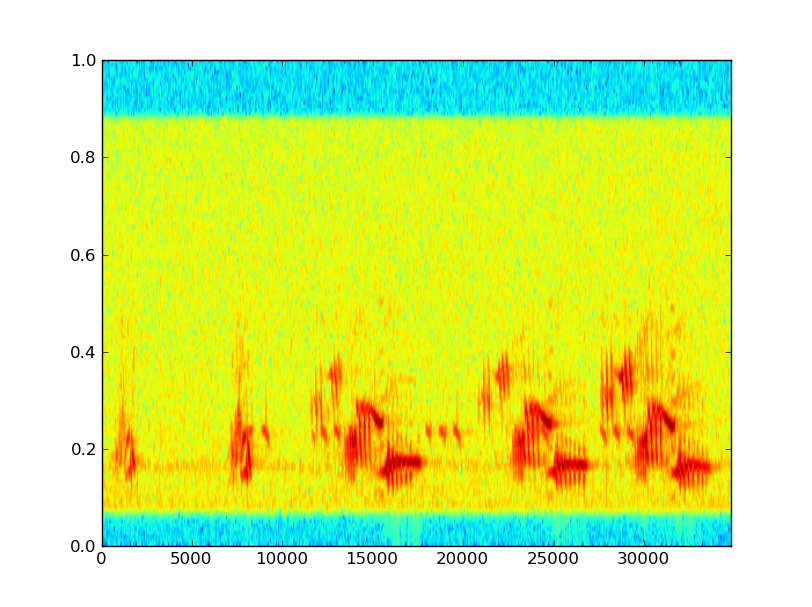
看来一些脱粒可能是有用的。
我被告知,大多数现有的文献使用基于歌曲特征的手工分类,比如潘多拉音乐基因组项目。我想像回声巢一样,使用自动分类。更新:很多人都在学习这个。
我的问题是,我应该使用什么工具来进行分析?我需要:
- 过滤/阈值去除一般噪音并保留音乐
- 滤除特定的噪音,如蝉
- 对鸟歌中的短语、音节和/或音符进行分割和分类。
- 建立各部分之间差异/相似性的度量标准;将发现鸟类之间的差异,将同一鸟不同叫声之间的差异最小化。
我选择的武器是numpy/scipy,但是像openCV这样的东西在这里可能有用吗?
编辑:更新了我的术语和重新措辞的方法后,经过一些研究和史蒂夫的有益答案。
回答 4
Stack Overflow用户
发布于 2010-12-21 22:42:31
必须给出一个答案,因为它太长了,不能发表评论。
我现在基本上是在这个领域工作,所以我觉得我有一些知识。显然,从我的角度来看,我建议使用音频而不是图像。我还建议使用MFCC作为您的特征提取(您可以认为是系数,总结/表征特定的音频子带,因为他们是)。
GMMs是最好的选择。
要执行这个任务,您的labelled/known必须有一些(最好是很多)数据,否则机器学习就没有基础了。
--你可能会发现有用的技术性:
然后,在测试期间,您向GMM提交一个查询MFCC向量,它将告诉您它认为是哪种。
更准确地说,您向每个GMM提交了一个查询(如果您正确地使用了它们,那么每个查询都会给出由该概率分布发出的特定特征向量的可能得分概率)。然后,您比较所有可能的分数,从所有的GMMs和分类的基础上,你收到的最高。
UBMs
而不是“过滤”噪声,您可以简单地建模所有背景噪声/信道失真的UBM (通用背景模型)。该模型由一个GMM组成,它使用了您可以使用的所有培训数据(即您为每个类使用的所有培训数据)。您可以使用此方法获得“似然比”(Prx将由特定模型发出/ Prx将由背景模型(UBM)发出),以帮助消除可由背景模型本身解释的任何偏差。
Stack Overflow用户
发布于 2010-12-21 20:37:33
这是个有趣的问题,但相当广泛。我确实推荐查阅一些现有的关于自动鸟鸣叫识别的文献。(是的,有一群人在做这个工作。)
本文(编辑:抱歉,死链接,但本章由杜福尔等人著。2014年可能更清楚)使用了一种基本的两阶段模式识别方法,我建议首先尝试:特征提取(论文使用MFCC),然后分类(论文使用GMM)。对于输入信号中的每一帧,您将得到一个MFCC矢量(介于10到30之间)。这些MFCC向量用于训练GMM (或SVM)以及相应的鸟类标记。然后,在测试期间,您向GMM提交一个查询MFCC向量,它将告诉您它认为它是哪些物种。
虽然有些人已经将图像处理技术应用于音频分类/指纹问题(例如,本文由Google Research撰写。),但由于时间上的烦人变化,我不愿推荐这些技术来解决您的问题或类似的问题。
“我应该使用什么工具来进行分析?”除其他外:
- 特征提取:MFCC,起始检测
- 分类: GMM,SVM
- 谷歌
很抱歉答案不完整,但这是一个宽泛的问题,这个问题比这里可以简短回答的问题更多。
Stack Overflow用户
发布于 2011-01-21 09:39:33
显然,您已经在执行STFT或类似的操作来构造这些图像,所以我建议对这些混合的时/频结构进行有用的总结。我记得一个系统,它的目的略有不同,它能够很好地利用音频波形数据,方法是将音频波形数据按时间和幅度分解成一小部分(< 30)个回收箱,并简单地计算每个垃圾箱中掉下的样本数。您可以在时间/振幅域或时间/频率域进行类似的操作。
https://stackoverflow.com/questions/4503181
复制相似问题
腾讯云开发者
