
将拟合回归线(abline)限制在模型中使用的数据范围内
是否有可能只在一定的x值范围内绘制适合的abline?
我有一个具有该数据集子集的线性拟合的数据集:
# The dataset:
daten <- data.frame(x = c(0:6), y = c(0.3, 0.1, 0.9, 3.1, 5, 4.9, 6.2))
# make a linear fit for the datapoints 3, 4, 5
daten_fit <- lm(formula = y~x, data = daten, subset = 3:5)当我绘制数据并绘制一条回归线时:
plot (y ~ x, data = daten)
abline(reg = daten_fit)这条线是为原始数据中x-值的全部范围绘制的.但是,我只想为用于曲线拟合的数据子集绘制回归线。我脑子里有两个想法:
- 绘制的第二行更厚,但只显示在3:5范围内。我检查了
abline、lines和segments的参数,但找不到任何东西。 - 将小滴答添加到与
abline垂直的各个位置。我现在知道该怎么做了。当然,这将是更好的方式。
你有什么解决办法吗?
回答 3
Stack Overflow用户
发布于 2011-06-08 13:58:29
一种方法是使用颜色来区分已安装的点和未安装的点:
daten_fit <- lm(formula = y~x, data = daten[3:5, ])
plot(y ~ x, data = daten)
points(y ~ x, data = daten[3:5, ], col="red")
abline(reg=daten_fit, col="red")
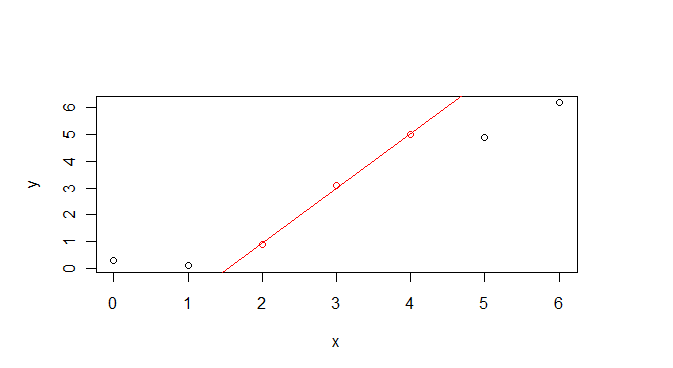
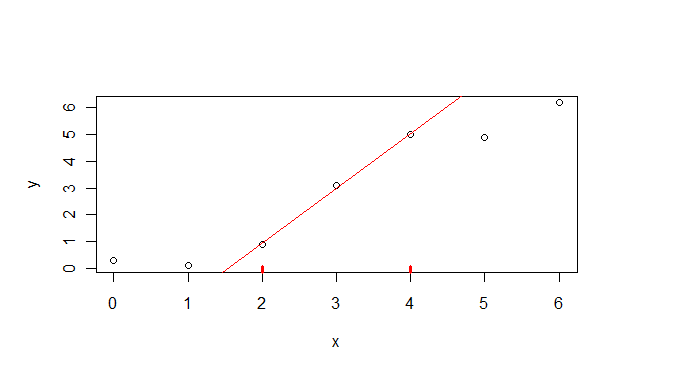
第二种方法是在x轴上画出滴答记号.这些蜱称为地毯,可以使用rug函数绘制。但是首先你必须计算range
#points(y ~ x, data = daten[3:5, ], col="red")
abline(reg=daten_fit, col="red")
rug(range(daten[3:5, 1]), lwd=3, col="red")
Stack Overflow用户
发布于 2011-06-08 14:33:29
答案是否定的,这是不可能得到abline()绘制拟合线上的一个部分的绘图区域,模型是拟合的。这是因为它只使用模型系数来绘制直线,而不是从模型中预测。如果你仔细观察,你会发现这条线实际上延伸到了地块区域之外,覆盖了它所在区域的绘图框架。
对于这些问题,最简单的解决办法是从模型中预测您想要的区域。
# The dataset:
daten <- data.frame(x = c(0:6), y = c(0.3, 0.1, 0.9, 3.1, 5, 4.9, 6.2))
# make a linear fit for the datapoints 3, 4, 5
mod <- lm(y~x, data = daten, subset = 3:5)首先,我们得到我们想要区分的x值的范围:
xr <- with(daten, range(x[3:5]))然后,我们使用该模型对这一范围内的一组均匀距离点进行预测:
pred <- data.frame(x = seq(from = xr[1], to = xr[2], length = 50))
pred <- transform(pred, yhat = predict(mod, newdata = pred))现在用abline()绘制数据和模型
plot(y ~ x, data = daten)
abline(mod)然后在你想要强调的地区加上:
lines(yhat ~ x, data = pred, col = "red", lwd = 2)这给了我们这个情节:
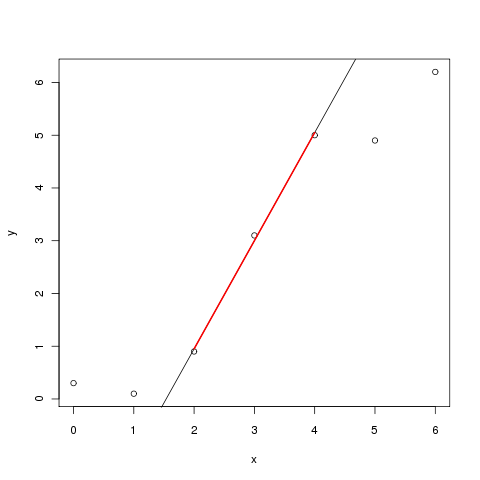
如果您有一个比abline()可以处理的模型更复杂的模型,那么我们采取稍微不同的策略,预测可用的、绘制的数据的范围来绘制直线,然后选择我们想要突出显示的间隔。下面的代码是这样做的:
## range of all `x` data
xr2 <- with(daten, range(x))
## same as before
pred <- data.frame(x = seq(from = xr2[1], to = xr2[2], length = 100))
pred <- transform(pred, yhat = predict(mod, newdata = pred))
## plot the data and the fitted model line
plot(y ~ x, data = daten)
lines(yhat ~ x, data = pred)
## add emphasis to the interval used in fitting
with(pred, lines(yhat ~ x, data = pred, subset = x >= xr[1] & x <= xr[2],
lwd = 2, col = "red"))我们在这里所做的是使用subset参数从拟合所用的区间内的预测中选择值,我们传递给subset的向量是TRUE和FALSE值的逻辑向量,表示哪些数据在感兴趣的区域,而lines()只沿着这些数据绘制一条线。
R> head(with(pred, x >= xr[1] & x <= xr[2]))
[1] FALSE FALSE FALSE FALSE FALSE FALSE有人可能会想,为什么我会预测预测变量的50或100个均匀间隔值,而在这种情况下,我们只对数据或感兴趣区域的开始和结束做了预测,并加入了这两个点?嗯,并不是所有的建模练习都那么简单--前面问题中的双重日志模型就是一个很好的例子--我上面概述的通用解决方案在所有情况下都会起作用,而将两个预测简单地结合起来就不行了。
@Andrie为您提供了解决方案2。
https://stackoverflow.com/questions/6279759
复制相似问题
腾讯云开发者
