
如何比较两个等高线?(字体比较)
我试图分析两个等高线,并给出一个百分比对应于它们的相似性。假设我有描述这些等高线的所有点坐标(就像SVG路径),我应该根据哪个因素来判断它们几乎是相同的呢?
经过一些谷歌搜索后,我发现了一些与傅立叶描述符有关的东西,它们与我的情况相关吗?
编辑
我想做的是比较几种字体和另一种字体。就像做什么字体一样,但不是用图像。由于产生的算法,将有可能找到一个字体等价物根据相似度百分比。
有些脚本只是比较每个字母的边框,但这还不够。我需要一种方法来判断阿里尔离韦丹娜最近,而不是韦伯丁。因此,假设我可以从字体中提取轮廓,我需要一种比较两种轮廓的方法。
例如(带有“逻辑”百分比值):
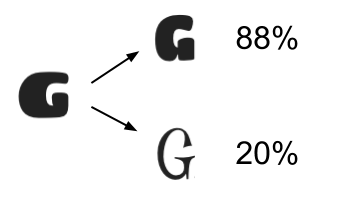
回答 2
Stack Overflow用户
发布于 2012-06-04 23:36:44
处理一般问题(字体匹配)的基本方法有两种:符号和统计。一个好的解决方案可能会在某种程度上将两者结合起来。
一种象征性的方法直接使用你对问题的了解。例如,你可以列出你(作为一个聪明的人)用来描述字体的东西。标识字体使用的问题类型。这种方法意味着编写足够聪明的例程来检测各种属性(例如笔画宽度、某些循环是否关闭、是否存在衬线等),再加上一个决策树(或“规则引擎”),将是/否/不确定的答案组合在一起,并给出答案。
统计方法听起来更像是你在想什么,而且可能是字体的工作原理。这里的想法是找到一些一般的属性,并使用这些作为权重,以找到一个“最佳”的选择。例如,如果你有很多字体,那么你可以训练一个神经网络(输入是一些样本分辨率的像素)。在这里,你不需要知道“如何”的网络决定-只是,只要有足够的培训数据,它将找到一个方法来这样做。或者,你可以看看所有暗像素的总和--这很可能会给出与以上百分比相似的结果。
这听起来很简单,但通常情况下,要找到简单的统计数据来很好地显示出所有您想要的方式上的差异并不容易。
所以两者之间有一个很大的中间地带。这样的想法是,如果你能从第一组中吸取一些想法,那么你就可以使第二组的方法更有效率。而最简单的神经网络方法是“一刀切”(它包括计算和决策),你可以把它们分开。所以,不只是给网络一堆像素,你可以给它更多的“有意义的”输入--你知道的东西有助于在不同字体之间检测到。比如笔画宽度,或者字符中“洞”的数目。您还可以添加一些智能来删除可能会混淆结果的东西--例如,预缩放到相同的高度(如果您有一个完整的字体集,那么您可以缩放所有内容,例如,小写"m“的高度是恒定的)。
傅立叶描述符是描述事物的“外部形状”的一种方式,因此可以像我前面描述的那样作为统计方法的输入。在给出的例子中,傅立叶描述符将在较低的G中提取锯齿的“尖度”,因此表示它与左边的G有很大的不同。但他们对笔画宽度不太在意,而对比例(放大/缩放)则毫不在意(这可能是件好事,也可能是坏事--如果你被随机赋予不同大小的字母,你不想对大小敏感,但如果你已经对整个字母表的标准"m“进行了归一化,那么你肯定想把它包括在内)。因为输出只是一个频谱,你可以通过互相关联来比较不同的字母,比如用PCA来分类不同类型的字母。
其他的想法是2d互相关(标准化相关的最大值给你一些关于两个事物是多么相似的概念),或者简单地看一下像素在两个字母中的比例。
正如评论中所说的,这是一个巨大的问题(我不是专家-以上只是一个有趣的旁观者随意胡扯)。
但是,要想最终回答你的问题,如果你拥有的是一个大纲,那么傅立叶描述符将是一个很好的起点。因为它关注的是形状,而不是“重量”,所以我会把它与轮廓所包围的总面积结合起来。然后编写一些代码来计算这些数字,并查看一些例子中的字母表的数字。如果它似乎区分了一些字母,但没有区分其他字母,那么在这些情况下寻找一些其他的测量方法。最后,您可能会将相当多的方法结合起来,以获得既快速又可靠的东西。
或者,如果你只想要一些简单的东西,试着使用一些容易测量的值,比如高度、宽度、等高线内的像素总数、沿垂直或水平线横过多少个笔画等等,如果你对傅里叶变换中涉及的数学不适应,那么结合这些数据就可以得到一些“足够好”的东西。
Stack Overflow用户
发布于 2012-06-05 14:33:45
您考虑过使用基于神经网络的方法吗?这论文使用自组织树映射来执行基于内容的图像检索。有了一个良好的训练集,应该可以创建一个多层网络(或索姆),它可以为您提供一个精确的相似性度量。
https://stackoverflow.com/questions/10884943
复制相似问题
腾讯云开发者
