
BizTalk中的线程饥饿
我有一个问题,在我们的BTS生产环境,我们不能复制在其他环境。在这里忍受我吧。
作为解决方案的一部分,业务流程(orch1)向消息框发送直接绑定消息,然后在一个分支上使用相关的接收形状和在另一个分支上实现接收超时的延迟(实现接收超时)进入侦听形状。延迟时间设置为10分钟。
直接绑定请求由一个不同的业务流程(orch2)处理,然后它将响应(同样通过直接绑定)返回到消息框,以便orch1能够获取它。
正在发生的情况是,大约每50次这种类型的操作中,orch1中的超时就会被触发一次,当来自orch2的响应返回时,我们会得到一个路由失败(这就是您所期望的,因为orch1上的消息实例订阅已经被删除)。
奇怪的是,orch2甚至在orch1中超时之后才初始化(见下面的屏幕截图)

在这里,您可以看到orch1将直接绑定请求发送到消息框,10分钟后超时将被触发。请求在11:26:31发送,超时时间在11:36:32。
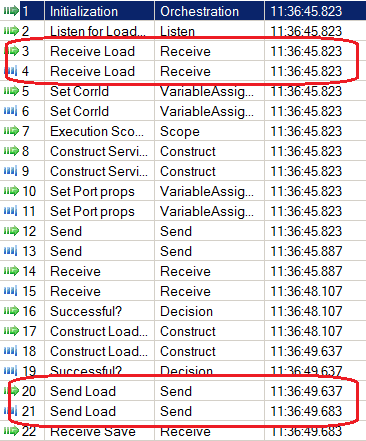
这显示了orch2的时间安排。如您所见,只有在orch1中超时触发后( 11:36:45),才会命中接收形状。
奇怪的是,orch1和orch2都托管在同一个主机中。此外,我们有一个负载均衡的集群,并且可以使用这个主机的两个实例来完成工作。因此,我期望在orch2上始终存在处理传入工作的可用性。然而,情况似乎并非如此。
我目前的怀疑是两个主机实例都存在线程饥饿问题。但是我的问题是
- ,这是一种合理的怀疑吗?
- ,我做了什么根本错误的事情吗?
- ,关于使用监听形状会影响线程的事情吗?
请注意,我们已经将主机线程设置配置为推荐级别(MaxIOThreads = 100,MaxWorkerThreads = 100,MinIOThreads = 25,MinWorkerThreads = 25)
回答 1
Stack Overflow用户
发布于 2012-06-18 19:05:26
听起来像是种族状况,但我不知道在哪里。
你考虑过把任务分开吗?
- orch1的第一部分发送请求。
- Orch2处理来自任务1的输出。
- 第二部分orch1处理来自orch1 2/ task 2的响应。
缺点是这没有能力对超时作出反应。我不知道这对你的问题是否重要。
https://stackoverflow.com/questions/10913842
复制相似问题
腾讯云开发者
