
SQLServer的UNION比UNION ALL有更好的性能?
SQLServer的UNION比UNION ALL有更好的性能?
提问于 2012-09-12 07:54:39
我知道UNION应该比UNION具有更好的性能(参见:工会对工会的表现)。
现在,我有了一个巨大的存储过程(包含大量查询),最后的结果是两个节SELECT,它们之间有一个UNION。由于这两个数据集是相互陌生的,所以我可以使用UNION --所有这些都应该更好(没有不同的操作)。
我已经在几个数据库上查过了,而且运行得很好。问题是,我的一个客户给我他的数据库进行性能调优,当我调查它时,我注意到如果我将UNION更改为UNION,性能会更好一些(!)。这是我在存储过程中所做的所有更改。
有人能解释一下这种情况是如何发生的吗?
谢谢,
齐夫
更新:
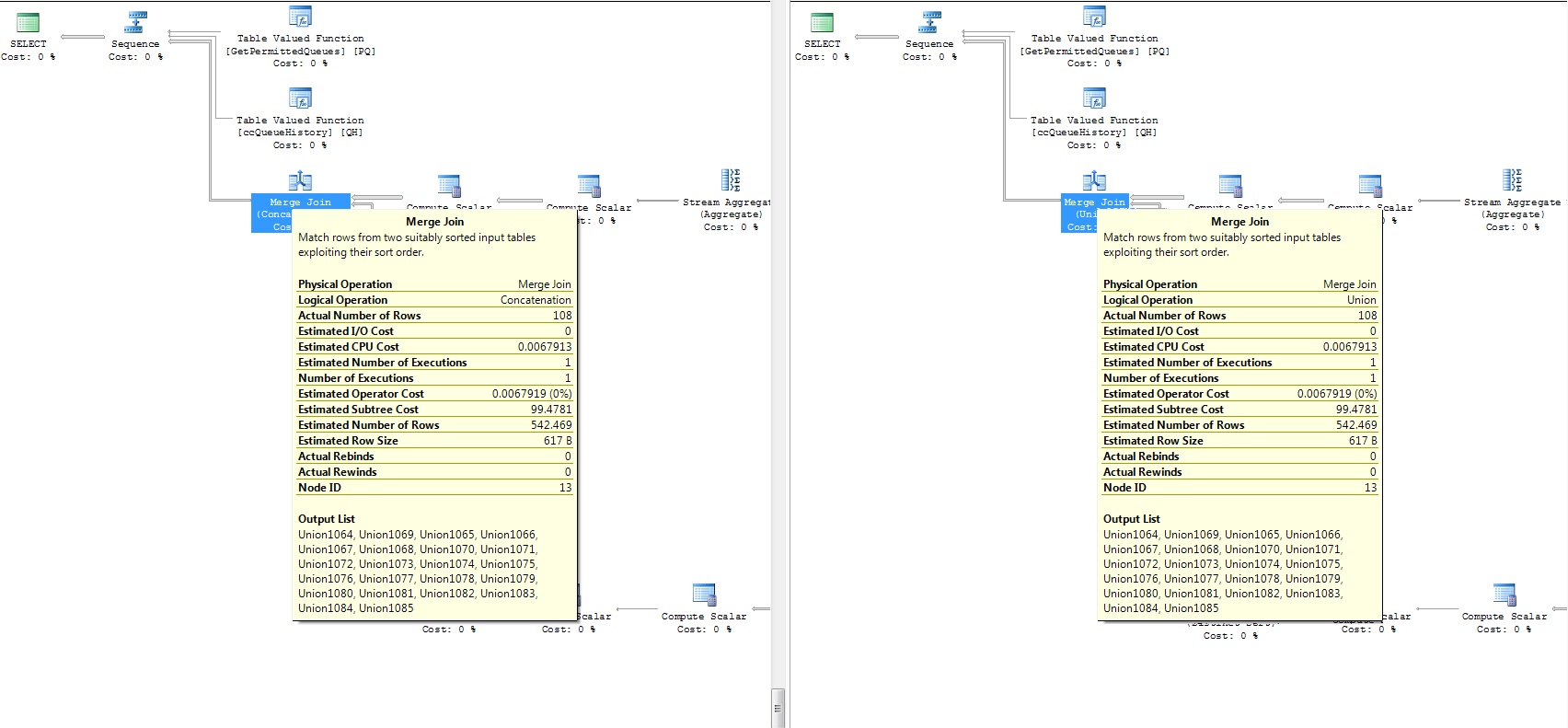
随附的两个查询的执行计划( diff部分):
Stack Overflow用户
发布于 2012-09-12 10:18:37
您引用了指向此文章的另一个主题。
如果您检查这个,这里有两个不同的执行计划。最大的不同是Distinct Sort,这使得性能更差。
在您的示例中,两个执行计划与物理操作Merge具有相同的步骤(只有逻辑操作不同)。甚至估计也是一样的。
现在我真的成了courios:这两个查询的区别有多大?
如果您没有做以下操作,请再次重复您的测试:
1)在运行中华人民共和国之前使用以下行:
DBCC FREEPROCCACHE
DBCC DROPCLEANBUFFERS 这使得缓存变得清晰,在这两种情况下,您都可以进行“冷运行”。您也可以在这里查看另一个文章。
2)多次重复运行,以查看avarage。
这种差异还存在吗?
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/12383549
复制相关文章
相似问题
腾讯云开发者
