
并行化oracle联合查询问题
我有这样一个Oralce查询:
Sub_query1
Union
Sub_query2;我想并行化查询。我在网上搜索,发现有些人说UNION不能并行化,因为子查询是串行运行的,并且UNION在两个子查询完成之前不会运行。他们是人们说的联盟可以并行化。我的问题是:
(1) can a UNION query be parallezied? if yes, how? if no, why? (2) can I just parallelize the two sub queries?
我正在使用Oracle数据库11g企业版发行版11.1.0.7.0-64位生产
谢谢!
回答 3
Stack Overflow用户
发布于 2012-10-17 18:13:20
我认为,与并行运行查询相比,同时运行这两个查询会使您感到困惑。SQL是一种描述性语言,由SQL引擎/优化器将其转换为代码。该查询计划由许多不同的组件组成,用于从表中检索数据、执行连接、进行聚合等等。
Oracle为您的联合查询生成一个查询计划。查询计划的每个组件都可以使用所有可用的处理器(假设满足了正确的条件)。然而,每个组件基本上一次运行一个(以一个合理的近似)。因此,查询的组件是并行化的,尽管这两个子查询不能同时运行。
一条建议。每当您考虑使用UNION时,您都应该问自己UNION ALL是否也能工作。UNION ALL的效率要高得多,因为它不需要删除最终结果集中的重复项。
Stack Overflow用户
发布于 2012-12-30 05:20:17
是的,正如您已经发现的,UNION查询可以并行运行。
要完全了解这里发生的事情,您可能需要阅读有关VLDB和分区指南中的并行执行的内容。
操作内并行几乎可以发生在任何地方。互操作并行只发生在生产者和消费者之间。在这种情况下,这意味着UNION (使用者)可以始终并行执行。每个子查询(生产者)将并行执行,但不是同时执行。
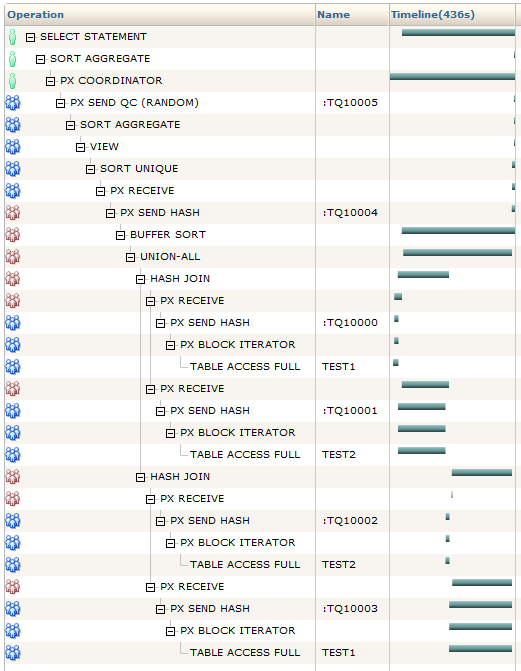
通过查看查询的活动报告,您可以在下面的示例中看到这种情况。
--Create two simple tables
create table test1(a number);
create table test2(a number);
--Populate them with 10 million rows
begin
for i in 1 .. 100 loop
insert into test1 select level from dual connect by level <= 100000;
insert into test2 select level from dual connect by level <= 100000;
end loop;
end;
/
commit;
--Gather stats
begin
dbms_stats.gather_table_stats(user, 'TEST1');
dbms_stats.gather_table_stats(user, 'TEST2');
end;
/
--Run a simple UNION.
select /*+ parallel */ count(*) from
(
select a from test1 join test2 using (a) where a <= 1000
union
select a from test2 join test1 using (a) where a <= 1000
);
--Find the SQL_ID by looking at v$sql, then get the active report
--(which must be saved and viewed in a browser)
select dbms_sqltune.report_sql_monitor(sql_id => 'bv5c18gyykntv', type => 'active')
from dual;这是输出的一部分。这是很难理解的,但它显示了联邦,这个计划的前11个步骤,是如何一直运作的。第一个子查询,接下来的9行,在查询的前半部分运行。然后,第二个子查询,最后9行,在查询的后半部分运行。
Stack Overflow用户
发布于 2012-10-17 19:23:13
通过进行一些测试和比较执行计划,我终于找到了一种类似于这样并行化的方法:
select/* +parallel (Result) */ * from
(Sub_query1
Union
Sub_query2) Result;通过这样做,时间和cpu花费几乎是串行版本的一半。向两个子查询添加并行提示不会改变时间和cpu成本。
https://stackoverflow.com/questions/12939400
复制相似问题
腾讯云开发者
