
(有点)复杂的数据库结构和简单的空字段
我目前正在两种不同的数据库设计之间进行选择。一个复杂的,对数据的分离比简单的更好。更复杂的设计将需要更多的null复杂查询,而简单的 one将有几个字段。
考虑下面的例子:
Complicated:
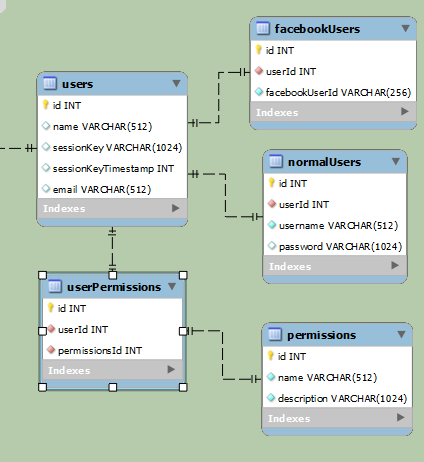
更简单:
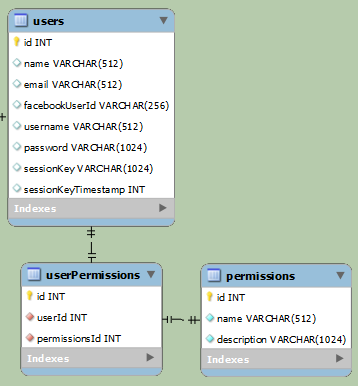
上面的示例用于分离常规用户和Facebook用户(他们最终将访问相同的数据,但登录方式不同)。在第一个例子中,数据显然是分开的。第二个例子要简单得多,但每行至少有一个null字段。如果是正常用户,facebookUserId将为空,而username和password如果是Facebook用户,则为空。
我的问题是:,什么更喜欢?赞成还是反对?随着时间的推移,哪一个最容易维护?
Stack Overflow用户
发布于 2012-10-31 23:46:55
问得好。
这适用于您可能选择实现的任何抽象,无论是在代码中还是在数据库中。您是为Facebook用户和“普通”用户编写单独的类,还是在一个类中处理这两种情况?
第一个选择是更复杂的。为什么这么复杂?因为它更容易扩展。您可以轻松地包括其他身份验证方法(例如,用于Twitter ID的表),或者扩展Facebook表以包括.其他一些facebook的特定信息。您已经将特定于每个身份验证方法的信息提取到它自己的表中,允许每个方法单独使用。这太棒了!
交换条件是,查询需要更多的精力,选择和插入需要花费更多的精力,而且可能会变得更加混乱。对于十几种不同的身份验证方法,您不需要一打表。而且,除非您从两个验证方法中获得了一些好处,否则您并不真正需要两个表。你需要这种灵活性吗?身份验证方法都是相似的--它们将有一个用户名和密码。这个抽象允许您存储更多特定于方法的信息,但是该信息存在吗?
第二种选择正好相反。更简单,但是您将如何处理未来的身份验证方法,如果您需要添加一些特定于身份验证方法的信息呢?
就我个人而言,我试图评估这个身份验证组件对系统的重要性。记住YAGNI -你不会需要它的-并且不要过度设计。除非您需要第一个选项提供的扩展性,否则请使用第二个选项。如果有必要的话,你可以随时提取它。
https://stackoverflow.com/questions/13167365
复制相似问题
腾讯云开发者
