
rubyXL (Errno::ENOENT)
rubyXL (Errno::ENOENT)
提问于 2013-01-05 17:33:51
我在使用rubyXL构建的爬虫上遇到了麻烦。它正确地遍历了我的文件系统,但是我收到了一个(Errno::ENOENT)错误。我已经签出了所有的rubyXL代码,并且所有的东西似乎都已经签出了。我的代码附在下面-有什么建议吗?
/Users/.../testdata.xlsx
/Users/.../moretestdata.xlsx
/Users/.../Lab 1 Data.xlsx
/Users/Dylan/.rvm/gems/ruby-1.9.3-p327/gems/rubyXL-1.2.10/lib/rubyXL/parser.rb:404:in `initialize': No such file or directory - /Users/Dylan/.../sheet6.xml (Errno::ENOENT)
from /Users/Dylan/.rvm/gems/ruby-1.9.3-p327/gems/rubyXL-1.2.10/lib/rubyXL/parser.rb:404:in `open'
from /Users/Dylan/.rvm/gems/ruby-1.9.3-p327/gems/rubyXL-1.2.10/lib/rubyXL/parser.rb:404:in `block in decompress'
from /Users/Dylan/.rvm/gems/ruby-1.9.3-p327/gems/rubyXL-1.2.10/lib/rubyXL/parser.rb:402:in `upto'
from /Users/Dylan/.rvm/gems/ruby-1.9.3-p327/gems/rubyXL-1.2.10/lib/rubyXL/parser.rb:402:in `decompress'
from /Users/Dylan/.rvm/gems/ruby-1.9.3-p327/gems/rubyXL-1.2.10/lib/rubyXL/parser.rb:47:in `parse'
from xlcrawler.rb:9:in `block in xlcrawler'
from /Users/Dylan/.rvm/rubies/ruby-1.9.3-p327/lib/ruby/1.9.1/find.rb:41:in `block in find'
from /Users/Dylan/.rvm/rubies/ruby-1.9.3-p327/lib/ruby/1.9.1/find.rb:40:in `catch'
from /Users/Dylan/.rvm/rubies/ruby-1.9.3-p327/lib/ruby/1.9.1/find.rb:40:in `find'
from xlcrawler.rb:6:in `xlcrawler'
from xlcrawler.rb:22:in `<main>'require 'find'
require 'rubyXL'
def xlcrawler(path)
count = 0
Find.find(path) do |file| # begin iteration of each file of a specified directory
if file =~ /\b.xlsx$\b/ # check if a given file is xlsx format
puts file # ensure crawler is traversing the file system
workbook = RubyXL::Parser.parse(file).worksheets # creates an object containing all worksheets of an excel workbook
workbook.each do |worksheet| # begin iteration over each worksheet
data = worksheet.extract_data.to_s # extract data of a given worksheet - must be converted to a string in order to match a regex
if data =~ /regex/
puts file
count += 1
end
end
end
end
puts "#{count} files were found"
end
xlcrawler('/Users/')回答 1
Stack Overflow用户
回答已采纳
发布于 2013-01-06 05:06:00
我对github上的rubyXL代码做了一些挖掘,看起来在解压缩方法中存在一个bug。
files['styles'] = Nokogiri::XML.parse(File.open(File.join(dir_path,'xl','styles.xml'),'r'))
@num_sheets = files['workbook'].css('sheets').children.size
@num_sheets = Integer(@num_sheets)
#adds all worksheet xml files to files hash
i=1
1.upto(@num_sheets) do
filename = 'sheet'+i.to_s # <----- BUG IS HERE
files[i] = Nokogiri::XML.parse(File.open(File.join(dir_path,'xl','worksheets',filename+'.xml'),'r'))
i=i+1
end这段代码对excel中的工作表编号做了一个假设,这是不正确的。这段代码简单地计算了工作表的数量,并对它们进行了数字分配。但是,如果您删除一个工作表,然后创建一个新的工作表,数字序列就会中断。
如果您检查您的Lab Data 1.xlsx文件,如果您拉起vba窗口(按alt + F11),您将看到以下内容:
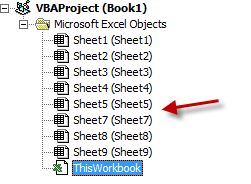
如您所见,这种安排将击败for循环,并在i= 6时导致异常。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/14174451
复制相关文章
相似问题
腾讯云开发者
