
为什么如果我使用睡眠,所测量的网络延迟会发生变化?
我试图确定一台机器接收一个数据包所需的时间,对它进行处理并给出一个答复。
这台机器,我将调用'server',运行一个非常简单的程序,它在缓冲区中接收数据包(recv(2)),将接收到的内容(memcpy(3))复制到另一个缓冲区,并将数据包发回(send(2))。服务器运行NetBSD 5.1.2。
我的客户端测量往返时间多次(pkt_count):
struct timespec start, end;
for(i = 0; i < pkt_count; ++i)
{
printf("%d ", i+1);
clock_gettime(CLOCK_MONOTONIC, &start);
send(sock, send_buf, pkt_size, 0);
recv(sock, recv_buf, pkt_size, 0);
clock_gettime(CLOCK_MONOTONIC, &end);
//struct timespec nsleep = {.tv_sec = 0, .tv_nsec = 100000};
//nanosleep(&nsleep, NULL);
printf("%.3f ", timespec_diff_usec(&end, &start));
} 为了清晰起见,我删除了错误检查和其他次要的内容。客户端在Ubuntu12.04 64位上运行.这两个程序都以实时优先级运行,尽管只有Ubuntu内核是实时的(-rt)。程序之间的连接是TCP。这很好,平均给我750微秒。
然而,如果我启用已注释掉的纳米睡眠呼叫(睡眠时间为100秒),我的测量值将下降100秒,平均为650秒;如果我睡眠200秒,则测量值下降到550秒,等等。这会上升到600秒的睡眠,平均150秒。然后,如果我把睡眠提高到700秒,我的措施就会平均提高到800秒。我向Wireshark证实了我的计划。
我不知道发生了什么。我已经在客户机和服务器中设置了TCP_NODELAY套接字选项,没有区别。我使用了UDP,没有区别(相同的行为)。所以我想这种行为并不是因为Nagle算法。会是什么?
更新
下面是与Wireshark一起的客户端输出的屏幕截图。现在,我在另一台机器上运行我的服务器。我使用相同的操作系统与相同的配置(因为它是一个生活系统在一个钢笔驱动器),但硬件是不同的。这种行为并没有出现,一切都如期而至。但问题仍然存在:为什么在以前的硬件中会出现这种情况?
更新2:更多信息
如前所述,我在两台不同的服务器计算机上测试了我的两个程序(客户机/服务器)。我画出了两个结果。
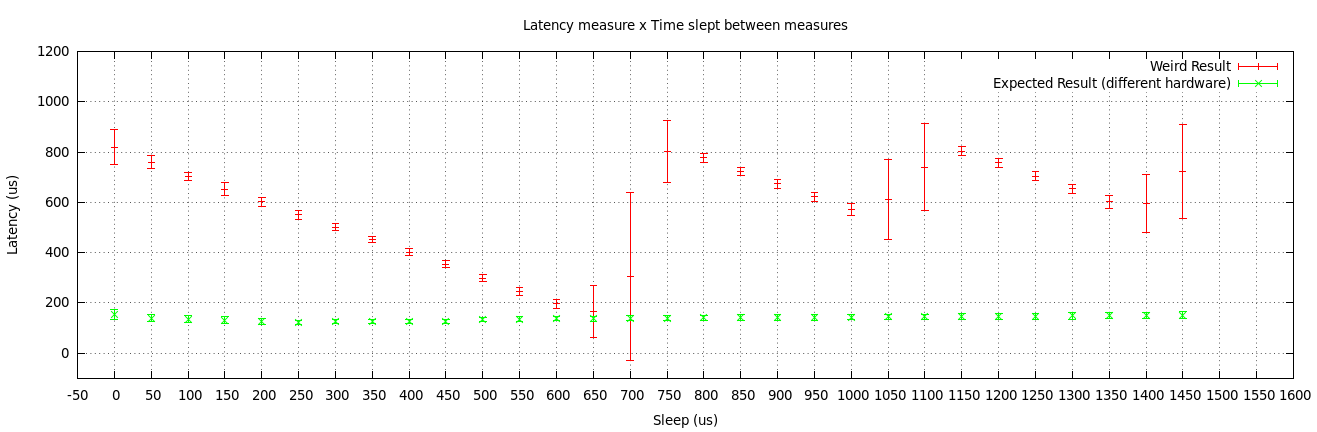
第一个服务器(奇怪的服务器)是一个RTD单板计算机,具有1Gbps的以太网接口。第二台服务器(普通服务器)是一个具有100 with以太网接口的金刚石单板计算机。它们运行相同的操作系统(NetBSD 5.1.2)。
从这些结果中,我确实认为这种行为是由于司机或NIC本身,虽然我仍然无法想象为什么会发生.
回答 5
Stack Overflow用户
发布于 2013-09-05 20:50:01
好吧,我得出了一个结论。
我在服务器上使用Linux而不是NetBSD来尝试我的程序。它按预期运行,也就是说,无论在代码的那个点上我睡眠了多少,结果都是一样的。
这个事实告诉我,问题可能在于NetBSD的接口驱动程序。为了识别驱动程序,我读取了dmesg输出。这是有关的部分:
wm0 at pci0 dev 25 function 0: 82801I mobile (AMT) LAN Controller, rev. 3
wm0: interrupting at ioapic0 pin 20
wm0: PCI-Express bus
wm0: FLASH
wm0: Ethernet address [OMMITED]
ukphy0 at wm0 phy 2: Generic IEEE 802.3u media interface
ukphy0: OUI 0x000ac2, model 0x000b, rev. 1
ukphy0: 10baseT, 10baseT-FDX, 100baseTX, 100baseTX-FDX, 1000baseT, 1000baseT-FDX, auto因此,正如您所看到的,我的接口名为wm0。根据这 (第9页),我应该通过查阅sys/dev/pci/files.pci文件第625行(这里)来检查加载了哪个驱动程序。它显示:
# Intel i8254x Gigabit Ethernet
device wm: ether, ifnet, arp, mii, mii_bitbang
attach wm at pci
file dev/pci/if_wm.c wm然后,通过搜索驱动程序源代码(dev/pci/if_wm.c,这里),我发现了一段可能会改变驱动程序行为的代码片段:
/*
* For N interrupts/sec, set this value to:
* 1000000000 / (N * 256). Note that we set the
* absolute and packet timer values to this value
* divided by 4 to get "simple timer" behavior.
*/
sc->sc_itr = 1500; /* 2604 ints/sec */
CSR_WRITE(sc, WMREG_ITR, sc->sc_itr);然后,我将这个1500值更改为1(试图增加每秒允许的中断次数)和0(试图完全消除中断节流),但这两个值产生的结果相同:
- 无纳米睡眠:~400μs的潜伏期
- 100 us的纳米睡眠:~230 us的潜伏期
- 拥有200 us的纳米睡眠:潜伏期为120 us
- 纳米睡眠260 us:潜伏期~70 us
- 纳米睡眠270我们:潜伏期~60我们(我能达到的最小潜伏期)
- 有超过300我们的纳米睡眠:~420
这至少比以前的情况表现得更好。
因此,我得出结论,这种行为是由于服务器的接口驱动程序造成的。我不愿意为了找到其他的罪魁祸首而进一步调查它,因为我将从NetBSD转移到Linux,因为这个项目涉及到这台单板计算机。
Stack Overflow用户
发布于 2013-04-28 11:53:15
这是一个(希望受过良好教育的)猜测,但我认为它可以解释你所看到的。
我不知道linux内核有多实时。可能不会完全先发制人.所以,有了这个免责声明,继续说:)
根据调度程序的不同,任务可能具有所谓的“量子”,这只是在调度另一个优先级相同的任务之前可以运行的一段时间。如果内核不是完全抢占性的,这也可能是一个高优先级任务可以运行的点。这取决于调度程序的细节,而我对此还不太了解。
在您的第一次获得时间和第二次访问时间之间,您的任务可能会被抢占。这仅仅意味着它是“暂停”的,而另一个任务可以在一定的时间内使用CPU。
没有睡眠的循环可能会发生这样的情况
clock_gettime(CLOCK_MONOTONIC, &start);
send(sock, send_buf, pkt_size, 0);
recv(sock, recv_buf, pkt_size, 0);
clock_gettime(CLOCK_MONOTONIC, &end);
printf("%.3f ", timespec_diff_usec(&end, &start));
clock_gettime(CLOCK_MONOTONIC, &start);
<----- PREMPTION .. your tasks quanta has run out and the scheduler kicks in
... another task runs for a little while
<----- PREMPTION again and your back on the CPU
send(sock, send_buf, pkt_size, 0);
recv(sock, recv_buf, pkt_size, 0);
clock_gettime(CLOCK_MONOTONIC, &end);
// Because you got pre-empted, your time measurement is artifically long
printf("%.3f ", timespec_diff_usec(&end, &start));
clock_gettime(CLOCK_MONOTONIC, &start);
<----- PREMPTION .. your tasks quanta has run out and the scheduler kicks in
... another task runs for a little while
<----- PREMPTION again and your back on the CPU
and so on....当您放置纳秒睡眠时,这很可能是调度程序能够在当前任务的量程过期之前运行的一个点(对于recv(),也适用于哪些块)。所以也许你得到的是这样的
clock_gettime(CLOCK_MONOTONIC, &start);
send(sock, send_buf, pkt_size, 0);
recv(sock, recv_buf, pkt_size, 0);
clock_gettime(CLOCK_MONOTONIC, &end);
struct timespec nsleep = {.tv_sec = 0, .tv_nsec = 100000};
nanosleep(&nsleep, NULL);
<----- PREMPTION .. nanosleep allows the scheduler to kick in because this is a pre-emption point
... another task runs for a little while
<----- PREMPTION again and your back on the CPU
// Now it so happens that because your task got prempted where it did, the time
// measurement has not been artifically increased. Your task then can fiish the rest of
// it's quanta
printf("%.3f ", timespec_diff_usec(&end, &start));
clock_gettime(CLOCK_MONOTONIC, &start);
... and so on然后会出现某种交错,有时你在两个获取时间()之间被提前,有时由于纳米睡眠而在它们之外出现。取决于x,你可能会碰到一个甜蜜点,在那里你会(偶然)得到你的先发制人点,平均来说,在你的时间测量块之外。
不管怎么说,这是我的两便士价值,希望它有助于解释:)
一张关于“纳秒”的小纸条.
我认为人们需要谨慎对待“纳秒”睡眠。我之所以这么说,是因为我认为普通电脑不可能真正做到这一点,除非它使用特殊的硬件。
正常情况下,操作系统将有一个正常的系统“滴答”,产生的时间可能是5ms。这是由RTC (实时时钟-只是一点硬件)所产生的中断。使用这个“滴答”系统然后生成它的内部时间表示。因此,平均操作系统只有几毫秒的时间分辨率。这个滴答不快的原因是,在保持一个非常准确的时间和不用计时器干扰淹没系统之间有一种平衡。
不知道我是不是和你普通的现代电脑有点过时了.我认为他们中的一些确实有更高的定时器,但仍然没有进入纳秒的范围,甚至可能在100美国时挣扎。
因此,总之,请记住,您可能获得的最佳时间分辨率通常在毫秒范围内。
编辑:只要重温一下,我想我应该添加以下内容.不能解释你看到了什么但可能会提供另一条调查途径..。
如前所述,纳米睡眠的计时精度不太可能优于毫秒。此外,您的任务可以被抢占,这也会导致时间问题。还存在一个问题,即数据包上升到协议栈所需的时间可能会有所不同,以及网络延迟。
您可以尝试的一件事是,如果NIC支持IEEE1588 (也称为PTP)。如果您的NIC支持它,它可以在PTP事件数据包离开并进入PHY时对其进行时间戳。这将为您提供对网络延迟的可能估计。这消除了您在软件抢占等方面可能遇到的任何问题。恐怕我对Linux PTP了解不足,但您可以尝试http://linuxptp.sourceforge.net/。
Stack Overflow用户
发布于 2013-07-11 09:28:23
我认为“量子”是最好的解释理论。在linux上,它是上下文切换频率。内核给处理量子时间。但是,在两种情况下,进程是先入为主的:
- 进程调用系统过程
- 量子时间结束了
- 硬件中断正在启动(从网络、hdd、usb、时钟等)
未使用的量子时间分配给另一个准备运行进程的时间,使用优先级/rt等。
实际上,上下文切换频率被配置为每秒10000次,它给出了大约100 is的量子值。但是内容切换需要一段时间,这是cpu所依赖的,看:http://blog.tsunanet.net/2010/11/how-long-does-it-take-to-make-context.html我不低估,为什么内容开关频率那么高,但它是讨论的linux内核论坛。
您可以在这里找到部分类似的问题:https://serverfault.com/questions/14199/how-many-context-switches-is-normal-as-a-function-of-cpu-cores-or-other
https://stackoverflow.com/questions/16043843
复制相似问题
腾讯云开发者
