从PHP中的字符串中删除特殊HTML字符
从PHP中的字符串中删除特殊HTML字符
提问于 2013-07-31 13:18:51
我发现了许多结果,但由于某种原因,对我没有任何作用!我用regex和html_entity_decode试过html_entity_decode,但没什么好的.
我想选择带有哈希标记前缀的单词,例如#WORD,它工作得很好,但有时哈希标记被读取为‏#WORD,但它错过了。
示例:This is a normal #hash_mark but #this_isn't
如下所示:

用于选择带有哈希标记前缀'~(?<=\s|^)#[^\s#]++~um'的单词的regex
在标记为重复的问题中,答案不适用于Unicode文本,如图像所示:

代码确实删除了所有特殊字符,包括Unicode文本,只需要用普通的‏#替换#
function remove_special_char($sentence){
return preg_replace('/[^a-zA-Z0-9_ %\[\]\.\(\)%&-]/s','',$sentence);
}
echo remove_special_char("hello مرحبا привет שלום");输出:
hello回答 1
Stack Overflow用户
发布于 2013-07-31 14:12:08
有两个不同的字符人物
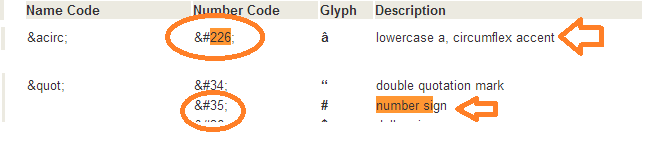
让你看看发生了什么我做了一些调试
var_dump(ord('#')); //return ASCII value of this char
$str1 = 'This is character 226 #';
$str1v1 = preg_replace('/[^a-zA-Z0-9_ %\[\]\.\(\)%&-]/s', '', $str1);
var_dump(ord('#')); //return ASCII value of second char
$str2 = "This is character 35 #";
$str2v1 = preg_replace('/[^a-zA-Z0-9_ %\[\]\.\(\)%&-]/s', '', $str2);
var_dump($str1v1);
var_dump($str2v1);
var_dump($str1);
var_dump($str2);输出:
int 226
int 35
string 'This is character 226 ' (length=22)
string 'This is character 35 ' (length=21)
string 'This is character 226 â€#' (length=26)
string 'This is character 35 #' (length=22)也许您或您的最终用户在某个地方复制和粘贴了这些代码,它们包含了转换后的字符代码,如您所描述的(‏#)。因为它们被渲染成相同的表面,让你感到困惑。
为了摆脱这些字符,我在下面的行中使用了regex
preg_replace('/[^a-zA-Z0-9_ %\[\]\.\(\)%&-]/s', '', $str1);该正则表达式已从PHP从字符串中删除特殊字符中提取。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/17971544
复制相关文章
相似问题
腾讯云开发者
