
有能力的k-表示聚类?
我是算法和优化方面的新手。
我正在尝试实现允许的k-意思是,但是到目前为止还没有解决,结果也很糟糕。
这是CVRP仿真的一部分(有能力的车辆路径问题)。
我很好奇我是否把引用的算法解释错了。
参考文献:“改进的K-均值聚类算法”(Geetha,Poonthalir,Vanathi)
模拟CVRP有15个客户,有1个仓库。
每个客户都有欧几里德坐标(x,y)和需求。
现有车辆3辆,每辆90辆。
因此,有能力的k-方法试图将15名客户集中在3辆车中,每个集群的总需求不得超过车辆容量。
更新:
在所引用的算法中,当代码没有“下一个最近的质心”时,我无法捕捉到代码必须做什么的任何信息。
也就是说,当检查了所有“最近的质心”时,在下面的步骤14.b中,customers[1]仍未被分配。
这将导致未分配索引1的客户。
注:customer[1]是需求量最大的客户(30)。
Q:当满足这个条件时,代码应该做什么?
这是我对参考算法的解释,请更正我的代码,谢谢。
- 给定
n请求者(客户),n=customerCount和一个仓库 - N项要求,
- N坐标(x,y)
- 计算集群数,
k=(所有需求之和)/vehicleCapacity - 选择初始质心,
5.a.根据
demand按降序=d_customers对客户进行排序, 5.b.将kfirst customers从d_customers中选择为初始质心=centroids[0 .. k-1] - 创建二进制矩阵
bin_matrix,维度=(customerCount) x (k), 6.a.用所有零填充bin_matrix - 启动WHILE循环,条件= WHILE
not converged。 7.a.converged = False - 开始循环,条件=
each customers, 8.a.客户指数=i - 计算从
customers[i]到所有centroids=>edist的欧氏距离 9.a.按升序排序edist, 9.b.选择距离最近的第一个centroid=closest_centroid - 启动而循环,条件=
while customers[i]不分配给任何集群。 - 分组所有其他未分配的客户=
G, 11.a.将closest_centroid视为G的质心。 - 计算每个
Pi的优先级customersofG, 12.a.优先级Pi = (distance from customers[i] to closest_cent) / demand[i]12.b。选择优先级最高的Pi客户。 12.c.优先级最高的客户有索引=hpc12.d.问:如果找不到最高优先级的客户,我们必须做什么? - 如果可能的话,将
customers[hpc]分配给centroids[closest_centroid]。 13.a.需求customers[hpc]=d1, 13.b。质心成员的所有需求之和=dtot, 13.c.IF (d1 + dtot) <= vehicleCapacity, THEN.. 13.d.将customers[hpc]分配给centroids[closest_centroid]13.e.更新bin_matrix,行索引=hpc,列索引=closest_centroid,设置为1。 - 如果
customers[i]是(仍然)任何集群的not assigned,那么..。 14.a.选择next nearest centroid,与edist的下一个最近距离。 14.b.问:如果没有下一个最近的质心,那我们该怎么办? - 通过比较前一个矩阵和更新矩阵bin_matrix来计算收敛性。
15.a.如果
bin_matrix中没有任何更改,则设置converged = True。 - 否则,从更新的集群中计算
new centroids。 16.a.根据每个集群的成员计算新的centroids' coordinates。 16.b.sum_x=集群members的所有x-coordinate之和, 16.c.num_c=集群中所有customers (members)的数目, 16.d.新质心星系团的x-coordinate=sum_x / num_c。 16.e.用同样的公式计算新质心的y-coordinate=sum_y / num_c。 - 迭代主WHILE循环。
在步骤14.b中,我的代码总是以未分配的客户结束。
这是当customers[i]仍然没有被分配给任何质心的时候,它已经用完了“下一个最近的质心”。
所产生的星系团很差。输出图:
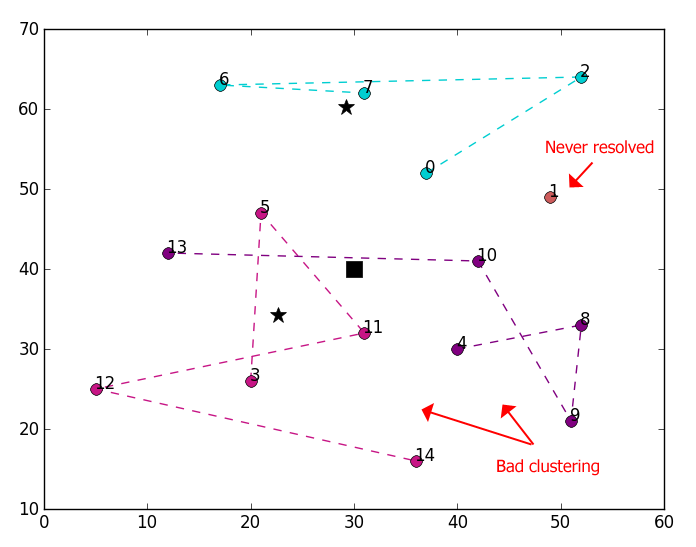
-In图片,星星是质心,方形是仓库。
在图中,客户标记为"1",demand=30总是以没有分配的集群结束。
程序输出,
k_cluster 3
idx [ 1 -1 1 0 2 0 1 1 2 2 2 0 0 2 0]
centroids [(22.6, 29.2), (34.25, 60.25), (39.4, 33.4)]
members [[3, 14, 12, 5, 11], [0, 2, 6, 7], [9, 8, 4, 13, 10]]
demands [86, 65, 77]第一簇和第三簇计算得很差。
没有分配索引为“1”的1 (-1)
问:我的解释和实现有什么问题?
如有任何更正、建议、帮助,将不胜感激,谢谢您的帮助。
这是我的完整代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
# pastebin.com/UwqUrHhh
# output graph: i.imgur.com/u3v2OFt.png
import math
import random
from operator import itemgetter
from copy import deepcopy
import numpy
import pylab
# depot and customers, [index, x, y, demand]
depot = [0, 30.0, 40.0, 0]
customers = [[1, 37.0, 52.0, 7], \
[2, 49.0, 49.0, 30], [3, 52.0, 64.0, 16], \
[4, 20.0, 26.0, 9], [5, 40.0, 30.0, 21], \
[6, 21.0, 47.0, 15], [7, 17.0, 63.0, 19], \
[8, 31.0, 62.0, 23], [9, 52.0, 33.0, 11], \
[10, 51.0, 21.0, 5], [11, 42.0, 41.0, 19], \
[12, 31.0, 32.0, 29], [13, 5.0, 25.0, 23], \
[14, 12.0, 42.0, 21], [15, 36.0, 16.0, 10]]
customerCount = 15
vehicleCount = 3
vehicleCapacity = 90
assigned = [-1] * customerCount
# number of clusters
k_cluster = 0
# binary matrix
bin_matrix = []
# coordinate of centroids
centroids = []
# total demand for each cluster, must be <= capacity
tot_demand = []
# members of each cluster
members = []
# coordinate of members of each cluster
xy_members = []
def distance(p1, p2):
return math.sqrt((p1[0] - p2[0])**2 + (p1[1] - p2[1])**2)
# capacitated k-means clustering
# http://www.dcc.ufla.br/infocomp/artigos/v8.4/art07.pdf
def cap_k_means():
global k_cluster, bin_matrix, centroids, tot_demand
global members, xy_members, prev_members
# calculate number of clusters
tot_demand = sum([c[3] for c in customers])
k_cluster = int(math.ceil(float(tot_demand) / vehicleCapacity))
print 'k_cluster', k_cluster
# initial centroids = first sorted-customers based on demand
d_customers = sorted(customers, key=itemgetter(3), reverse=True)
centroids, tot_demand, members, xy_members = [], [], [], []
for i in range(k_cluster):
centroids.append(d_customers[i][1:3]) # [x,y]
# initial total demand and members for each cluster
tot_demand.append(0)
members.append([])
xy_members.append([])
# binary matrix, dimension = customerCount-1 x k_cluster
bin_matrix = [[0] * k_cluster for i in range(len(customers))]
converged = False
while not converged: # until no changes in formed-clusters
prev_matrix = deepcopy(bin_matrix)
for i in range(len(customers)):
edist = [] # list of distance to clusters
if assigned[i] == -1: # if not assigned yet
# Calculate the Euclidean distance to each of k-clusters
for k in range(k_cluster):
p1 = (customers[i][1], customers[i][2]) # x,y
p2 = (centroids[k][0], centroids[k][1])
edist.append((distance(p1, p2), k))
# sort, based on closest distance
edist = sorted(edist, key=itemgetter(0))
closest_centroid = 0 # first index of edist
# loop while customer[i] is not assigned
while assigned[i] == -1:
# calculate all unsigned customers (G)'s priority
max_prior = (0, -1) # value, index
for n in range(len(customers)):
pc = customers[n]
if assigned[n] == -1: # if unassigned
# get index of current centroid
c = edist[closest_centroid][1]
cen = centroids[c] # x,y
# distance_cost / demand
p = distance((pc[1], pc[2]), cen) / pc[3]
# find highest priority
if p > max_prior[0]:
max_prior = (p, n) # priority,customer-index
# if highest-priority is not found, what should we do ???
if max_prior[1] == -1:
break
# try to assign current cluster to highest-priority customer
hpc = max_prior[1] # index of highest-priority customer
c = edist[closest_centroid][1] # index of current cluster
# constraint, total demand in a cluster <= capacity
if tot_demand[c] + customers[hpc][3] <= vehicleCapacity:
# assign new member of cluster
members[c].append(hpc) # add index of customer
xy = (customers[hpc][1], customers[hpc][2]) # x,y
xy_members[c].append(xy)
tot_demand[c] += customers[hpc][3]
assigned[hpc] = c # update cluster to assigned-customer
# update binary matrix
bin_matrix[hpc][c] = 1
# if customer is not assigned then,
if assigned[i] == -1:
if closest_centroid < len(edist)-1:
# choose the next nearest centroid
closest_centroid += 1
# if run out of closest centroid, what must we do ???
else:
break # exit without centroid ???
# end while
# end for
# Calculate the new centroid from the formed clusters
for j in range(k_cluster):
xj = sum([cn[0] for cn in xy_members[j]])
yj = sum([cn[1] for cn in xy_members[j]])
xj = float(xj) / len(xy_members[j])
yj = float(yj) / len(xy_members[j])
centroids[j] = (xj, yj)
# calculate converged
converged = numpy.array_equal(numpy.array(prev_matrix), numpy.array(bin_matrix))
# end while
def clustering():
cap_k_means()
# debug plot
idx = numpy.array([c for c in assigned])
xy = numpy.array([(c[1], c[2]) for c in customers])
COLORS = ["Blue", "DarkSeaGreen", "DarkTurquoise",
"IndianRed", "MediumVioletRed", "Orange", "Purple"]
for i in range(min(idx), max(idx)+1):
clr = random.choice(COLORS)
pylab.plot(xy[idx==i, 0], xy[idx==i, 1], color=clr, \
linestyle='dashed', \
marker='o', markerfacecolor=clr, markersize=8)
pylab.plot(centroids[:][0], centroids[:][1], '*k', markersize=12)
pylab.plot(depot[1], depot[2], 'sk', markersize=12)
for i in range(len(idx)):
pylab.annotate(str(i), xy[i])
pylab.savefig('clust1.png')
pylab.show()
return idx
def main():
idx = clustering()
print 'idx', idx
print 'centroids', centroids
print 'members', members
print 'demands', tot_demand
if __name__ == '__main__':
main()Stack Overflow用户
发布于 2013-08-01 14:01:30
当总需求接近总容量时,这个问题就开始涉及到垃圾箱包装的各个方面。正如您已经发现的,这种特定算法的贪婪方法并不总是成功的。我不知道作者是否承认了这一点,但如果他们不承认,评审员就应该抓住它。
如果您想继续使用类似的算法,我将尝试使用整数规划将请求者分配给质心。
https://stackoverflow.com/questions/17992189
复制相似问题
腾讯云开发者
