
带标签的sklearn图混淆矩阵
带标签的sklearn图混淆矩阵
提问于 2013-10-07 20:08:53
我想绘制一个混淆矩阵来可视化分类器的性能,但它只显示标签的数量,而不是标签本身:
from sklearn.metrics import confusion_matrix
import pylab as pl
y_test=['business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business', 'business']
pred=array(['health', 'business', 'business', 'business', 'business',
'business', 'health', 'health', 'business', 'business', 'business',
'business', 'business', 'business', 'business', 'business',
'health', 'health', 'business', 'health'],
dtype='|S8')
cm = confusion_matrix(y_test, pred)
pl.matshow(cm)
pl.title('Confusion matrix of the classifier')
pl.colorbar()
pl.show()如何将标签(健康,business..etc)添加到混淆矩阵中?
回答 9
Stack Overflow用户
回答已采纳
发布于 2013-10-08 15:49:43
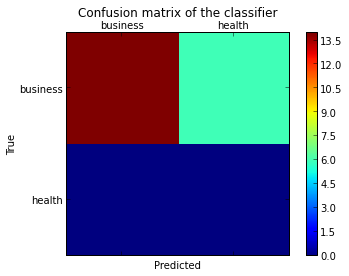
正如这个问题中所暗示的那样,您必须通过存储通过调用matplotlib函数(下面的fig、ax和cax变量)传递的图形和轴对象来“打开”低级艺术家API。然后,可以使用set_xticklabels/set_yticklabels替换默认的x轴和y轴滴答。
from sklearn.metrics import confusion_matrix
labels = ['business', 'health']
cm = confusion_matrix(y_test, pred, labels)
print(cm)
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(cm)
plt.title('Confusion matrix of the classifier')
fig.colorbar(cax)
ax.set_xticklabels([''] + labels)
ax.set_yticklabels([''] + labels)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()请注意,我将labels列表传递给confusion_matrix函数,以确保它得到了正确的排序,并与滴答进行了匹配。
这导致了以下数字:
Stack Overflow用户
发布于 2017-12-29 07:01:30
更新:
在scikit-learn 0.22中,有一个新特性可以直接绘制混淆矩阵(但是,1.0中不推荐它,1.2中将删除它)。
请参阅文档:矩阵
旧答案:
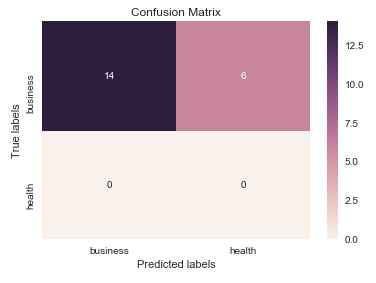
我认为在这里值得一提的是seaborn.heatmap的使用。
import seaborn as sns
import matplotlib.pyplot as plt
ax= plt.subplot()
sns.heatmap(cm, annot=True, fmt='g', ax=ax); #annot=True to annotate cells, ftm='g' to disable scientific notation
# labels, title and ticks
ax.set_xlabel('Predicted labels');ax.set_ylabel('True labels');
ax.set_title('Confusion Matrix');
ax.xaxis.set_ticklabels(['business', 'health']); ax.yaxis.set_ticklabels(['health', 'business']);
Stack Overflow用户
发布于 2018-05-17 08:35:05
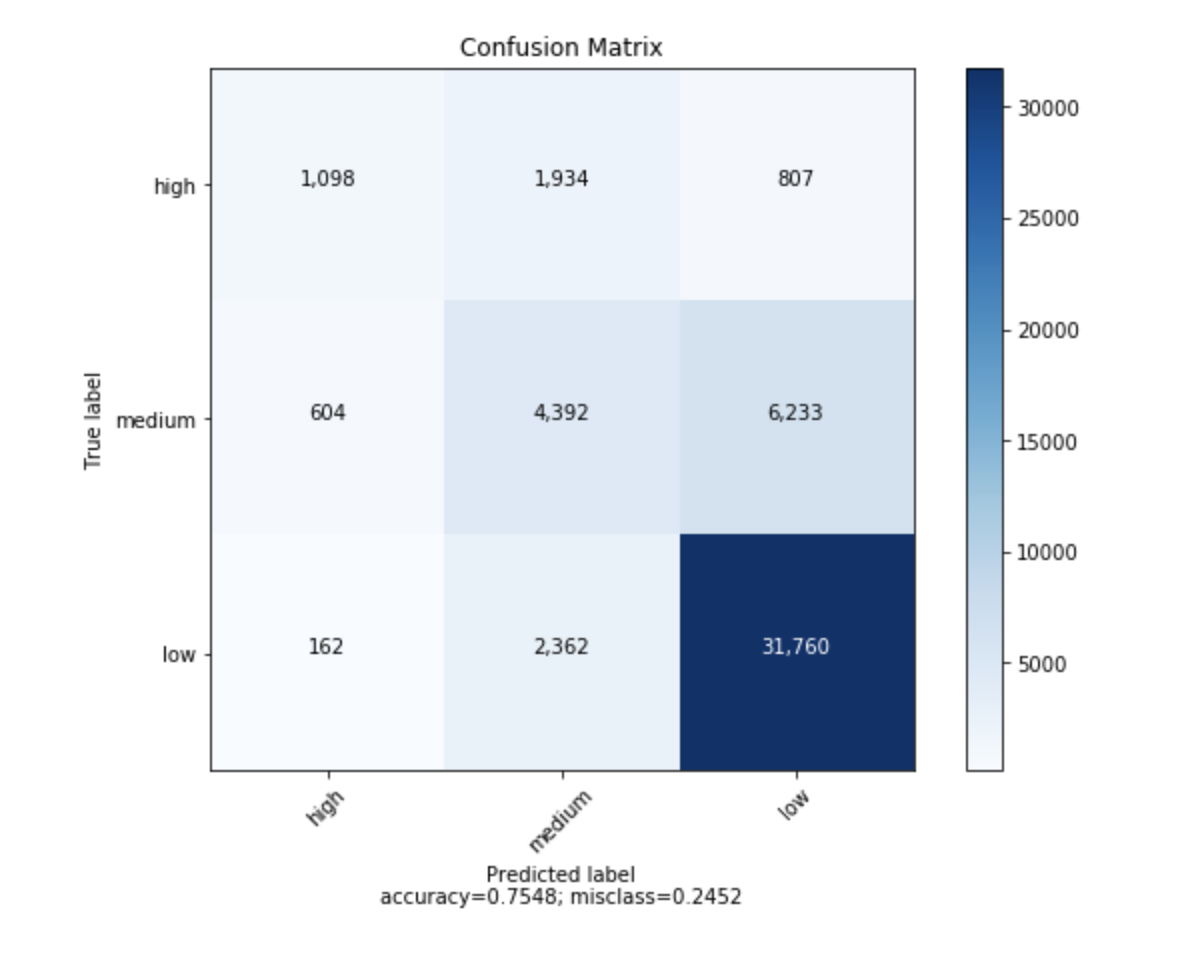
我找到了一个函数,它可以绘制sklearn生成的混淆矩阵。
import numpy as np
def plot_confusion_matrix(cm,
target_names,
title='Confusion matrix',
cmap=None,
normalize=True):
"""
given a sklearn confusion matrix (cm), make a nice plot
Arguments
---------
cm: confusion matrix from sklearn.metrics.confusion_matrix
target_names: given classification classes such as [0, 1, 2]
the class names, for example: ['high', 'medium', 'low']
title: the text to display at the top of the matrix
cmap: the gradient of the values displayed from matplotlib.pyplot.cm
see http://matplotlib.org/examples/color/colormaps_reference.html
plt.get_cmap('jet') or plt.cm.Blues
normalize: If False, plot the raw numbers
If True, plot the proportions
Usage
-----
plot_confusion_matrix(cm = cm, # confusion matrix created by
# sklearn.metrics.confusion_matrix
normalize = True, # show proportions
target_names = y_labels_vals, # list of names of the classes
title = best_estimator_name) # title of graph
Citiation
---------
http://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
"""
import matplotlib.pyplot as plt
import numpy as np
import itertools
accuracy = np.trace(cm) / np.sum(cm).astype('float')
misclass = 1 - accuracy
if cmap is None:
cmap = plt.get_cmap('Blues')
plt.figure(figsize=(8, 6))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
if target_names is not None:
tick_marks = np.arange(len(target_names))
plt.xticks(tick_marks, target_names, rotation=45)
plt.yticks(tick_marks, target_names)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
thresh = cm.max() / 1.5 if normalize else cm.max() / 2
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
if normalize:
plt.text(j, i, "{:0.4f}".format(cm[i, j]),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
else:
plt.text(j, i, "{:,}".format(cm[i, j]),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label\naccuracy={:0.4f}; misclass={:0.4f}'.format(accuracy, misclass))
plt.show()它会看起来像这样
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/19233771
复制相关文章
相似问题
腾讯云开发者
