
写大熊猫档案的几个问题
写大熊猫档案的几个问题
提问于 2013-10-14 15:30:10
我目前正在尝试用熊猫的tr8 pd.to_excel函数从文件格式中编写一个excel文件。然而,它写入excel文件,但是在excel中打开时,我看不到完整的数据。我附上了tr8的代码
output_file = pd.ExcelWriter('20131001103311.xlsx')
widths = [1, 8, 2, 4, 2, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 5, 1, 10, 1]
df = pd.read_fwf('20131001103311.tr8', widths=widths, header=True)
df.columns = ['TIP. REG.', 'COD. EST.', 'TIP. INF.', 'AGNO', 'DEL', 'ENE', 'OBS', 'FEB', 'OBS', 'MAR', 'OBS', 'ABR',
'OBS', 'MAY', 'OBS', 'JUN', 'OBS', 'JUL', 'OBS', 'AGO', 'OBS', 'SEP', 'OBS', 'OCT', 'OBS', 'NOV', 'OBS',
'DIC', 'OBS', 'ESP.', 'TIP. DATO']
df.to_excel(output_file, '20131001103311')
output_file.save()回答 1
Stack Overflow用户
回答已采纳
发布于 2013-10-14 19:12:59
为了测试,我将您的程序简化为2列数据:
import pandas as pd
output_file = pd.ExcelWriter('20131001103311.xlsx')
widths = [10, 10]
df = pd.read_fwf('20131001103311.tr8', widths=widths, header=True)
df.columns = ['TIP. REG.', 'COD. EST.']
df.to_excel(output_file, '20131001103311')
output_file.save()我运行它是针对以下固定宽度格式的fwf文件:
$ cat 20131001103311.tr8
TIP. REG. COD. EST.
1 1000
2 300
3 7000
4 600
5 12345我没有得到任何执行错误,输出看起来应该是:
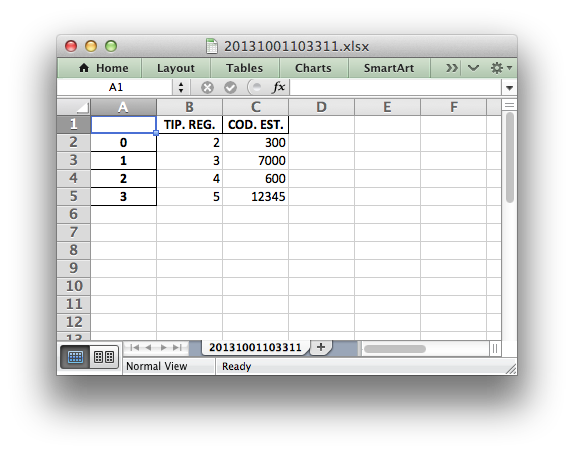
由于参数header=True已被传递给read_fwf,因此丢失了第一行数据。
因此,这似乎不是一个pandas问题。
我会查看您的固定宽度字段文件中的列。也许在阅读之后打印出来,看看您提供给df.columns的列名是否都被正确地解析了。
Update:查看@jchavarro试图上传的输入数据和输出文件的图像,看上去这里可能有问题。至少Excel输出没有绑定到DataFrame数据。可能是由于重复的OBS列造成的。
更新2:这是一个问题。我已经在GitHub并提交了一个修复程序上提过了。
更新3:我为上面的问题创建了一个修复程序,现在它已经合并到熊猫主分支中,并且应该作为0.13版本的一部分发布。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/19363779
复制相关文章
相似问题
腾讯云开发者
