
图例中的重复项在matplotlib中?
图例中的重复项在matplotlib中?
提问于 2013-10-15 15:51:47
我正试图用以下片段将这个传说添加到我的情节中:
import matplotlib.pylab as plt
fig = plt.figure()
axes = fig.add_axes([0.1, 0.1, 0.8, 0.8]) # left, bottom, width, height (range 0 to 1)
axes.set_xlabel('x (m)')
axes.set_ylabel('y (m)')
for i, representative in enumerate(representatives):
axes.plot([e[0] for e in representative], [e[1] for e in representative], color='b', label='Representatives')
axes.scatter([e[0] for e in intersections], [e[1] for e in intersections], color='r', label='Intersections')
axes.legend() 我以这个阴谋收场
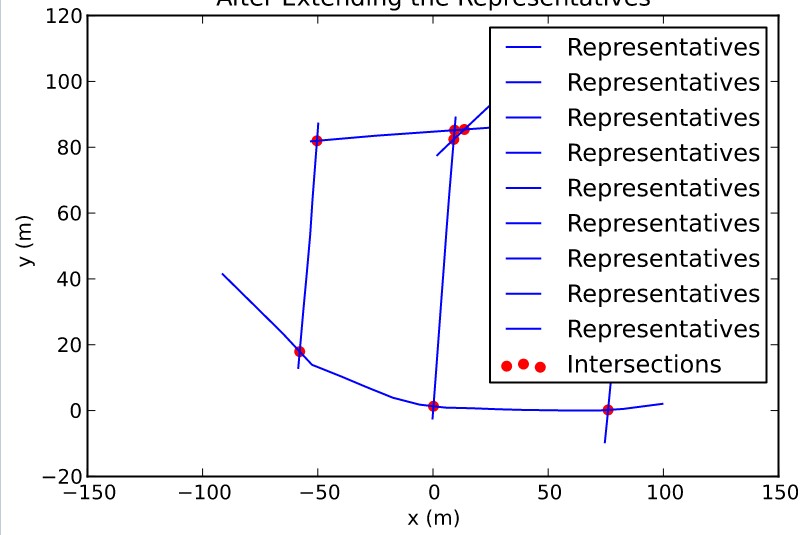
显然,这些项目在情节中是重复的。如何纠正此错误?
回答 6
Stack Overflow用户
回答已采纳
发布于 2013-10-15 16:13:22
正如文档所说,尽管很容易错过:
如果label属性为空字符串或以“_”开头,则将忽略这些艺术家。
因此,如果我在一个循环中绘制类似的行,而我只想要在图例中的一个示例行,我通常会这样做
ax.plot(x, y, label="Representatives" if i == 0 else "")其中i是我的循环索引。
不像单独构建它们那样好,但我经常希望标签逻辑尽可能接近于线条绘制。
(请注意,matplotlib开发人员自己倾向于使用"_nolegend_"来显式化。)
Stack Overflow用户
发布于 2019-05-22 09:32:01
基于完成,下面是一个通用方法,用于在没有重复标签的情况下绘制图例:
def legend_without_duplicate_labels(ax):
handles, labels = ax.get_legend_handles_labels()
unique = [(h, l) for i, (h, l) in enumerate(zip(handles, labels)) if l not in labels[:i]]
ax.legend(*zip(*unique))示例用法:(repl.it)
fig, ax = plt.subplots()
ax.plot([0,1], [0,1], c="y", label="my lines")
ax.plot([0,1], [0,2], c="y", label="my lines")
legend_without_duplicate_labels(ax)
plt.show()
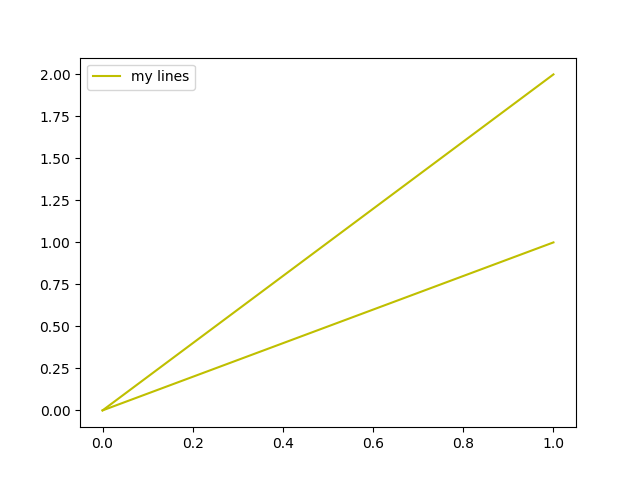
Stack Overflow用户
发布于 2016-11-29 16:16:50
下面是在正常分配标签之后删除重复的图例条目的方法:
representatives=[[[-100,40],[-50,20],[0,0],[75,-5],[100,5]], #made up some data
[[-60,80],[0,85],[100,90]],
[[-60,15],[-50,90]],
[[-2,-2],[5,95]]]
fig = plt.figure()
axes = fig.add_axes([0.1, 0.1, 0.8, 0.8]) # left, bottom, width, height (range 0 to 1)
axes.set_xlabel('x (m)')
axes.set_ylabel('y (m)')
for i, representative in enumerate(representatives):
axes.plot([e[0] for e in representative], [e[1] for e in representative],color='b', label='Representatives')
#make sure only unique labels show up (no repeats)
handles,labels=axes.get_legend_handles_labels() #get existing legend item handles and labels
i=arange(len(labels)) #make an index for later
filter=array([]) #set up a filter (empty for now)
unique_labels=tolist(set(labels)) #find unique labels
for ul in unique_labels: #loop through unique labels
filter=np.append(filter,[i[array(labels)==ul][0]]) #find the first instance of this label and add its index to the filter
handles=[handles[int(f)] for f in filter] #filter out legend items to keep only the first instance of each repeated label
labels=[labels[int(f)] for f in filter]
axes.legend(handles,labels) #draw the legend with the filtered handles and labels lists以下是研究结果:
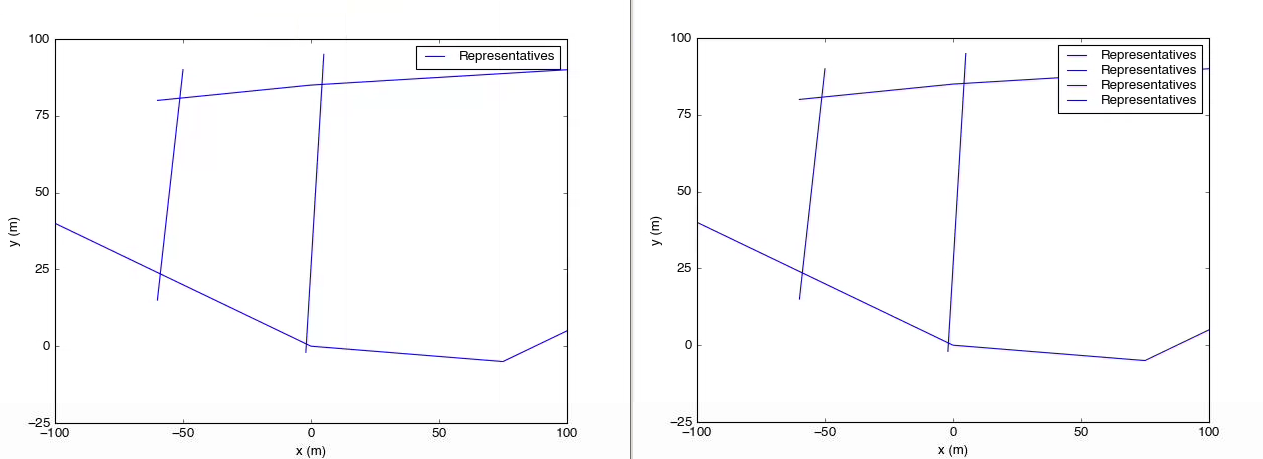
左边是上面脚本的结果。在右侧,传奇调用已被axes.legend()替换。
它的优点是,您可以浏览大部分代码,只需正常地分配标签,而不必担心内联循环或if,您也可以将其构建到图例或类似的包装器中。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/19385639
复制相关文章
相似问题
腾讯云开发者
