
Pandas中map、applymap和应用方法的区别
你能告诉我什么时候使用这些矢量化方法和基本例子吗?
我看到map是一个Series方法,而其余的是DataFrame方法。不过,我对apply和applymap方法感到困惑。为什么我们有两种将函数应用于DataFrame的方法?再次,简单的例子,说明使用将是很棒的!
Stack Overflow用户
发布于 2020-12-23 19:26:00
对于附加的上下文和直觉,这里有一个明确而具体的例子来说明这些差异。
假设您有下面所示的函数。(此label函数将根据作为参数(x)提供的阈值将值任意拆分为“High”和“Low”。)
def label(element, x):
if element > x:
return 'High'
else:
return 'Low'在这个例子中,让我们假设我们的dataframe有一个带有随机数的列。
如果您尝试用map映射label函数:
df['ColumnName'].map(label, x = 0.8)您将导致以下错误:
TypeError: map() got an unexpected keyword argument 'x'现在,使用相同的函数并使用apply,您将看到它是有效的:
df['ColumnName'].apply(label, x=0.8)Series.apply()可以采用额外的参数元素,而Series.map()方法将返回一个错误。
现在,如果您试图同时将相同的函数应用于数据帧中的几个列,则使用DataFrame.applymap()。
df[['ColumnName','ColumnName2','ColumnName3','ColumnName4']].applymap(label)最后,您也可以在dataframe上使用capabilities ()方法,但是DataFrame.apply()方法具有不同的功能。df.apply()方法不应用函数元素,而是沿轴应用函数,无论是按列方向,还是按行方向。当我们创建一个与df.apply()一起使用的函数时,我们将其设置为接受一个系列,最常见的是一个列。
下面是一个示例:
df.apply(pd.value_counts)当我们将pd.value_counts函数应用于dataframe时,它计算了所有列的值计数。
注意,当我们使用df.apply()方法转换多列时,这一点非常重要。这是可能的,因为pd.value_counts函数对一个系列进行操作。如果我们尝试使用df.apply()方法对多个列应用一个按元素工作的函数,就会得到一个错误:
例如:
def label(element):
if element > 1:
return 'High'
else:
return 'Low'
df[['ColumnName','ColumnName2','ColumnName3','ColumnName4']].apply(label)这将导致以下错误:
ValueError: ('The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().', u'occurred at index Economy')通常,当向量化函数不存在时,我们应该只使用apply()方法。回想一下,熊猫使用矢量化,对整个系列同时应用操作的过程,以优化性能。当我们使用apply()方法时,我们实际上是在遍历行,因此向量化方法可以比apply()方法更快地执行等效任务。
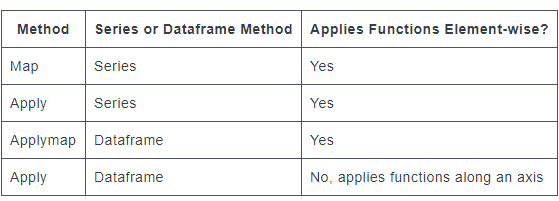
下面是一些已经存在的矢量化函数的示例,您不希望使用任何类型的apply/map方法重新创建这些函数:
- Series.str.split()拆分系列中的每个元素
- Series.str.strip()从系列中的每个字符串中剥离空格。
- Series.str.lower()将系列中的字符串转换为小写。
- Series.str.upper()将系列中的字符串转换为大写。
- Series.str.get()检索系列中每个元素的ith元素。
- Series.str.replace()用另一个字符串替换本系列中的正则表达式或字符串
- Series.str.cat()在一个系列中连接字符串。
- Series.str.extract()从匹配regex模式的系列中提取子字符串。
https://stackoverflow.com/questions/19798153
复制相似问题
腾讯云开发者
